Preface
Welcome to Stambia!
This guide contains information about administering the products and and putting into production Stambia developments.
Audience
This document is intended for administrators and users interested the production flow of Stambia.
Other Stambia Resources
In addition to the product manuals, Stambia provides other resources available on its company website: www.stambia.com and community website www.stambia.org.
Obtaining Help
To get help you can:
- contact our global Technical Support Center: www.stambia.org/di/support.
- consult the articles on our community website www.stambia.org.
- consult or post topics on our forum on www.stambia.org.
Feedback
We welcome your comments and suggestions on the quality and usefulness of this documentation.
If you find any error or have any suggestion for improvement, please contact us at www.stambia.org/di/support and indicate the title of the documentation along with the chapter, section, and page number, if available. Please let us know if you want a reply.
Architecture
Introduction to Stambia
Stambia is the next generation high performance data integration platform that enables your IT team to deliver the right data, at the right place, at the right time. It is a key component for your data integration projects.
Stambia is designed with the following key features for better design-time productivity and higher run-time performances.
High-Performance ELT Architecture
Traditional data integration products use the Extract-Transform-Load (ETL) architecture to run the data transformations. In this architecture, a dedicated proprietary engine is in charge of the data processing.
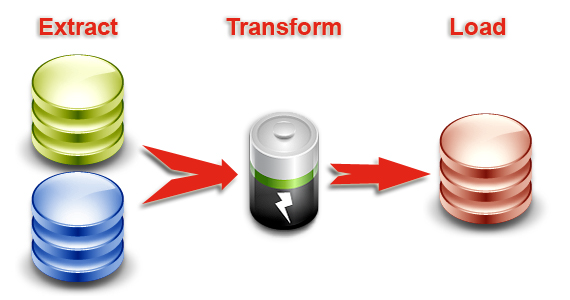
The ELT (Extract-Load and Transform) architecture used in Stambia removes the need for this middle-tier engine. It leverages the data processing engines in place to run processes generated and optimized for these engines.
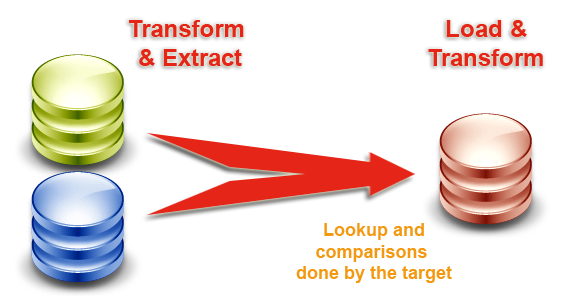
By removing the cost of the hardware, software, maintenance and tuning skills required for the ETL server, the ELT architecture guarantees the best TCO. This architecture scales naturally with the source and target data stores. It guarantees the best performance and scalability for data integration at any time.
Rationalized Production
Setting up and maintaining a production environment with Stambia is made fast and simple:
- Lightweight Runtime Deployment: Stambia uses a single lightweight Java component – the Runtime Engine – to handle run time execution and logging.
- Rationalized Deployment Model: The deployment model for data integration processes is designed for production users. Package files generated by the development team are easily configured and deployed by the production teams, using graphical or command-line interfaces.
- Comprehensive Monitoring: The entire execution flow is tracked in logs which are accessed using a Web-based administration dashboard. Live executions can be monitored and past executions can be replayed in diagrams that reflect the processes created at design-time.
Enterprise Data Integration
Stambia provides universal data access and enterprise-class capabilities for integration.
- Extensible Connectivity Framework: In Stambia, connectivity is a fully extensible framework. Technology Descriptors can be added or customized to support any type of technology without restricting the capabilities to a subset. Built-in Process Templates can also be customized to generate processes optimized for specific use cases.
- Built-in Technology Adapters: Out of the box adapters provide read/write access to a variety of systems and data formats including files, databases, XML, web services, applications, etc. They include both the technology descriptors and process templates for these technologies.
- Real-Time and Batch Integration Patterns: Both the real-time (Using Changed Data Capture) and batch integration patterns are supported. These patterns cover the most common use cases for Enterprise Data Integration, Business Intelligence and Master Data Management.
Through all these features, Stambia enables you to deliver data where and when the business needs it, in a simple, fast and safe way.
Architecture overview
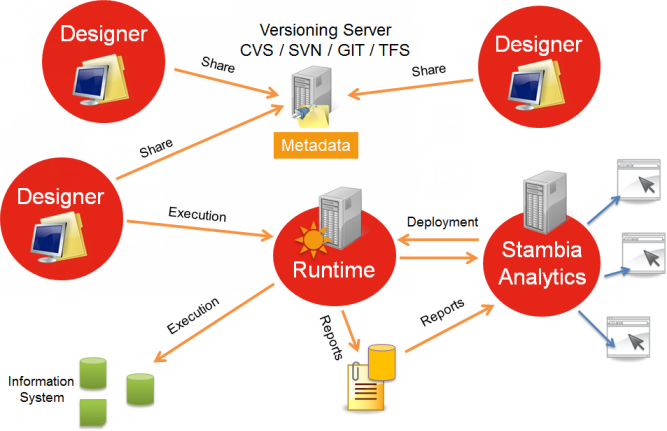
Stambia is built with three components:
- Designers: a heavy client, useful for setting parameters and developing flows.
- Runtimes (engines): this component executes the flows once they have been developed.
- Stambia Analytics: this component allows one to deploy, configure and manage flows as well as following and consult their executions in time.
The Designer
Powerful User Experience
Stambia uses an intuitive, familiar and robust Integrated Development Environment (IDE), the Stambia Designer that contributes to the unified user experience of the Stambia platform. This IDE is designed with features that ensure better productivity for development and higher efficiency for maintenance.
- Metadata Driven Approach: The entire integration logic design is driven by metadata, supporting powerful cross-referencing and impact analysis capabilities that ease the development and maintenance of the data integration flows.
- Declarative Design: Data mappings are designed graphically in a declarative way, focusing on the purpose of these mappings. The technical processes required for achieving the data movement and transformation are automatically generated using built-in process templates.
- Integration Process Workflows: Complex process workflows are designed in diagrams, using a rich toolbox. Workflows support parallelism, conditional branching and event-based execution.
- Components Reusability and Templating: The mappings as well as the workflows can be reused within the same project or in other projects. Processes can be converted into user-defined templates for reusability.
- Seamless Team Collaboration: Standard source control systems such as Concurrent Versioning System (CVS) or Apache Subversion (SVN) are available from within the Stambia to safely share projects within the team or across teams in robust infrastructures.
The Runtimes
Overview
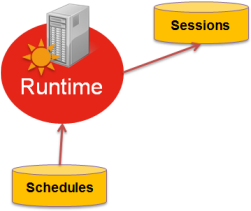
A Runtime is a Java component.
It saves its implementation reports (or session logs) in a database. Are also stored in a database any schedules made with the Runtime.
Services exposed by the Runtime
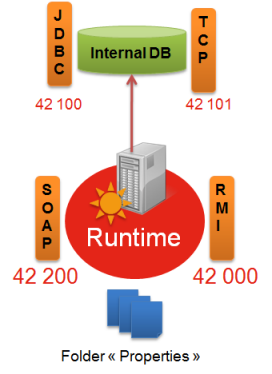
Runtimes can expose different services:
- An RMI service: this enables Java applications (Designer, Stambia Analytics, …) to converse with the Runtime. Its default port is 42000.
- An internal database which is the default destination of log sessions and schedules. Its default ports are 42100 and 42101.
- The Scheduler
- A Web Services REST or Soap API if the Runtime needs a Web service to launch the remote execution of a delivery. Its default port is 42200.
The different default listening ports
Stambia can potentially open several ports when launching:
- The RMI listening port, by default 42000
- The SOAP and REST listening port, by default 42200
- The JDBC listening port of the internal base, by default 42100
- The HTTP listening port of the internal base, by default 42101
Depending on the way the Runtime is used, these ports may have to be opened according to the security rules of the network (firewall for example), or they will have to be modified.
Port modification will be explained further on in this document.
Setting parameters on a Runtime
By default, the Runtime will store its sessions (log sessions) and the scheduler’s plannings in the internal database (Java H2 database).
The parameters of these services may be found in the properties folder.
Two different files are used to set the saving location of the reports and the schedules:
- properties\engineParameters.xml is the main Runtime configuration file.
- properties\engineScheduler.properties is the scheduler configuration file, used to define where schedules are saved for instance (this file is optional)
These files can always be modified later.
In this case, the Runtime will have to be restarted.
We will see further on what may be modified.
Parameters of the debug logs
The Runtime also stores “debug logs” in the “log” folder. These logs are configured via the file “log4j.xml”.
By default, the debug logs are rotary logs, which means the folder will never exceed a certain size. Parameters have to follow the Log4J standard.
This behavior may be modified, particularly if Stambia support has requested it, but usually, it is advisable not to change it.
Stambia Analytics
The Stambia Analytics component executes on a Web Server such as Apache Tomcat.
It is used to
- configure the deployment of the deliveries
- schedule the deliveries
- consolidate logs (session logs) originating from several runtimes (several databases).
- manage the runtimes
It is a WAR that has to be deployed. After deployment, configuration will take place directly in the Web interface.
The configuration files for this tool are stored in the folder which is specified by the environment variable STAMBIA_WEBAPP_HOME. Write permissions must be given in this folder to the user who is executing the application server.
The Web server’s log will give the information in the case of permission errors.
Production Flow
When working with Stambia the final goal is to generate and deploy a «delivery», which is a file containing the complete roadmap of tasks to be done, with ready to use connections (server, ports, passwords, etc.), and which will be executed by a Runtime.
Most of the time producing those deliveries will be done through the following steps, from the developer developing the Mappings and Processes to the final deployment of the delivery to be executed by the Runtimes.
- Development of the Mappings and Processes by the development team.
- Generation of package for the production team to configure everything required for the production environment
- Generation of a delivery from the previously created package
- Publication of the delivery on Runtime(s)
This is the most common steps which are followed to get the final delivery to be published on Runtime(s).
The delivery can then be executed or scheduled to be executed regularly based on cron rules for instance.
This guide details the following sections:
- Package Generation
- Delivery Generation
- Delivery Deployment
- Delivery Execution
- Delivery Scheduling
Package Generation
A package is an archive containing all the needed files and folders to generate a delivery.
Most of the time, a package is generated by the development team when they have finished working on a Mapping / Process.
The package can then be used to generate the delivery that will be executed by the Runtimes.
To generate a package, there is two solutions:
- Generate the package directly from Stambia Designer.
- Generate the package from command line.
Generating a package from Stambia Designer
The most common way to generate the Package corresponding to a Mapping / Process is to do it from Stambia Designer.
The procedure for this is quite simple:
- Right click on the Mapping / Process
- From the menu, choose Build > Package [with documentation]
That’s all, you can now find the generated package under:
<Designer Installation>/stambiaRuntime/build/packages
Generating a package from command line
The other possibility is to generate the Package corresponding to a Mapping / Process from command line.
For this you’ll have to write a file containing the list of Packages to build, that will be specified on the command line tool.
The first step is to prepare the file listing the Packages to build.
The syntax is the following, and each new line represents a Package to build.
build package "<PROCESS_PATH_WITHIN_WORKSPACE>" -target "<TARGET_DIRECTORY>"
The following parameters are available:
| Parameter | Description |
|---|---|
| package <PATH_WITHIN_WORKSPACE> | Relative path within the workspace to the Process to build the package from. |
| -target <TARGET_DIRECTORY> | Target directory in which the generated package will be created. |
Example of file script:
build package "Tutorial - Fundamentals/Processes/Load All Datamart.proc.proc" -target "D:/Packages/"
build package "My Project - 01/Process01.proc" -target "D:/Packages/"
build package "My Project - 01/Process02.proc" -target "D:/Packages/"
If you want to generate the Package of a Mapping, specify the path of the Mapping’s built Process file, and not the .map file
As we now have the required script file, we can generate the Packages with the command line tool.
For this, navigate to the Designer installation root folder, and use the command below:
java -jar plugins/org.eclipse.equinox.launcher_1.3.0.v20120522-1813.jar -application com.indy.shell.application -data "WORKSPACE_PATH" -script "SCRIPT_PATH" [-logFile "LOG_FILE_PATH"] -console –noSplash
The following parameters are available:
| Parameter | Mandatory | Description |
|---|---|---|
| -data «WORKSPACE_PATH» | Yes | Path to the Stambia Designer workspace where the Processes are stored |
| -script «SCRIPT_PATH» | Yes | Path to the script file containing the list of packages to build, created earlier |
| -logFile «LOG_FILE_PATH» | No | Path to a log file where information about the Packages generation will be logged |
Example:
java -jar plugins/org.eclipse.equinox.launcher_1.3.0.v20120522-1813.jar -application com.indy.shell.application -data "D:/workspace/development" -script "D:/resources/scripts/packagesToGenerate.txt" -console –noSplash
Delivery Generation
A delivery is what will be executed or scheduled in the final stage by the Runtimes.
It is a file which contains the complete roadmap of tasks to be done, with ready to use connections (server, ports, passwords, etc.).
Everything in it is already configured, is completely autonomous, and will only need a Runtime to become executable.
There are three possibilities to generate a delivery:
- From Stambia Designer
- From Stambia Analytics
- From command line
From Stambia Designer
The first way to generate a delivery is to do it directly from Stambia Designer.
With this method, you do not need to generate a Package before as the Designer will take care of everything.
This means that the configuration (connection properties, parameters, ...) of the delivery will be the one of the Designer at the moment it is generated.
The procedure for this is quite simple:
- Right click on the Mapping / Process
- From the menu, choose Build > Delivery
That’s all, you can now find the generated delivery under:
<Designer Installation>/stambiaRuntime/build/deliveries
The delivery being generated, you must next deploy it on the Runtime you want it to be executable.
Refer to the Delivery Deployment part of this documentation for further information about deployment.
From Stambia Analytics
Generating a delivery can also be performed through Stambia Analytics.
The idea is to import into Stambia Analytics the Package generated by the development team, configure it, and generate (build) the delivery from it
This method is the most recommended one for production use.
It offers the possibility to create configurations for each environment (development, test, production, ...) and easily build and deploy deliveries from a management web UI.
For more information, consult the Stambia Analytics documentation.
The delivery being generated, you must next deploy it on the Runtime you want it to be executable.
Refer to the Delivery Deployment part of this documentation for further information about deployment.
From command line
The last method to generate a delivery is to build it from command line.
The idea is to use the Package that has been generated by the development team to build the delivery.
The Runtime is shipped with command line build scripts allowing to generate a delivery from a package: builddelivery.bat / builddelivery.sh.
Depending on if you are on a Microsoft Windows or Unix OS, the .bat or .sh should be used.
The scripts must be used as follow:
builddelivery.sh mypackage.pck [options]
Options
The following options are available
buildmode
-buildmode <mode>
Specifies how the delivery should be generated.
Prerequisites: Runtime S17.6.0 and higher
Two build modes are actually available to generate the deliveries, each one having its advantages.
- substitution
- generation
When this parameter is not specified the generation mode is used.
generation mode
Prerequisites: supported by all Runtime versions
Mode which has been used by default since the build scripts exist, which launches a generation mechanism to build the delivery.
The principal advantage of this mode is that as a new generation step is performed, user does not have to set all the parameters in the extracted configuration file, neither to use a configuration file. The default value with which the package has been generated is used for parameters which has not been valuated in the configuration file.
Another advantage is that it allows to customize Metadata parameters which were not defined as externalized when generating the package. This offers the possibility to add extra parameters on the extracted configuration file used to build the delivery, to replace parameters which were not anticipated when generating the package.
The con is that because of the generation mechanism, it can be time consuming for large processes.
substitution mode
Prerequisites: Runtime S17.6.0 and higher
Mode which consists of simply replacing the externalized attributes with the values provided inside the extracted configuration file.
The builder simply retrieves the pre-built delivery which is inside the package and replace the parameters in.
This is also the method that uses Stambia DI Production Analytics for generating deliveries, and this offers better performances as no generation is performed to build the delivery.
This also offers the possibility to generate deliveries for all the processes contained in a multi-process package, which is not possible with generation mode.
In this mode it is mandatory to build the delivery using a configuration with all the externalized Metadata parameters valuated.
Which build mode should I use?
For most common usage, the substitution mode can be used as it offers better performances and allows to build all the processes contained in a package.
The generation mode, which is still the default mode for backward compatibility, can be useful when you need to override values for parameters which were not originally externalized when the package was generated.
listprocessnames
-listprocessnames
list all the processes contained in a package
Prerequisites: Runtime S17.6.0 and higher
extract
-extract
Extract the configuration file of the package containing the externalized Metadata parameters which are used in the processes and which can be customized.
conf and conffile
-conf <name> | -conffile <file path>
When used with the -extract option, specifies a name for the configuration which will be extracted.
When used for building a delivery, specifies the previously extracted configuration to use for replacing the externalized Metadata parameters.
- For the generation mode if the configuration is not specified the values for those parameters will be the default values with which the package has been generated.
- For the substitution mode, specifying a configuration is mandatory.
processname
-processname <name>
Specify which process contained in the package should be built.
Prerequisites: Runtime S17.6.0 and higher
When the package contains only one process, this is not mandatory as the builder will detect that there is only one process and build it.
When the package contains multiple processes, this allows to choose which one to build.
When the package contains multiple processes, if this parameter is not specified, the deliveries for all the processes will be generated (supported on substitution mode only).
deliveryfolder
-deliveryfolder <folder path>
Allows to change the default location where the deliveries are generated.
Prerequisites: Runtime S17.6.0 and higher
About configuration files
When using the -extract option, the configuration file of the package is extracted and re-named as specified with the -conf (or -conffile) options.
This file contains all the Metadata parameters which are defined as externalized in the Metadata.
Some are externalized by default, such as the JDBC URL or JDBC User and password, and others can be externalized manually by the user from the Designer in the Metadata.
Those parameters are commented with a default value in the extracted configuration file, for the user to be able to customize them when generating deliveries.
Example of configuration file
#################################################################
### Name: super/Rdbms MetaData/Hypersonic SQL/HSQL - localhost_62210
### Type: com.stambia.rdbms.server
#_-1vK4CVLEeWjxY2_6aCFbA/url=jdbc:hsqldb:hsql://localhost:62210
#_-1vK4CVLEeWjxY2_6aCFbA/user=sa
#################################################################
### Name: super/Rdbms MetaData/Hypersonic SQL/HSQL - localhost_62210/HOTEL_MANAGEMENT
### Type: com.stambia.rdbms.schema
#_aUU9YE26Eeay9ZeykqAlHA/TABLE_SCHEM=HOTEL_MANAGEMENT
#################################################################
To specify a value for a parameter, uncomment the corresponding line (remove the ‹#› which is at its start) and specify the wanted value.
Example of modified configuration file
#################################################################
### Name: super/Rdbms MetaData/Hypersonic SQL/HSQL - localhost_62210
### Type: com.stambia.rdbms.server
_-1vK4CVLEeWjxY2_6aCFbA/url=jdbc:hsqldb:hsql://productionhost:62210
_-1vK4CVLEeWjxY2_6aCFbA/user=productionuser
#################################################################
### Name: super/Rdbms MetaData/Hypersonic SQL/HSQL - localhost_62210/HOTEL_MANAGEMENT
### Type: com.stambia.rdbms.schema
_aUU9YE26Eeay9ZeykqAlHA/TABLE_SCHEM=HOTEL_PRODUCTION_SCHEMA
#################################################################
When the parameters correspond to the expected values, the delivery can be built using the configuration.
Note: Passwords properties are waiting for passwords encrypted using the
encrypt <password>command on the Runtime engine console (engine command line tool).
Examples
Below are examples of script usage
Listing the processes contained inside a package
builddelivery.sh mypackage.pck -listprocessnames
Extracting a configuration
builddelivery.sh mypackage.pck -conf myconf -extract
Building a delivery using a previously extracted configuration
builddelivery.sh mypackage.pck -conf myconf
Building a delivery using a configuration, process name, and delivery folder
builddelivery.sh mymultipackage.pck -conf myconf -processname "Load All Datamart" -deliveryfolder D:/deliveries/
Building all the deliveries of a multi-process package inside a specified folder (using substitution mode is mandatory)
builddelivery.sh mymultipackage.pck -conf myconf -deliveryfolder D:/deliveries/ -buildmode substitution
The generated delivery will be found in the folder build/deliveries if the -deliveryfolder option is not specified.
The delivery being generated, you must next deploy it on the Runtime you want it to be executable.
Refer to the Delivery Deployment part of this documentation for further information about deployment.
Delivery Deployment
After generating a delivery (see Delivery Generation part of this documentation), the next step is to publish it on a Runtime.
When the delivery is published, the Runtime will then be able to execute it.
There are three possibilities to perform these steps:
- From Stambia Designer
- From Stambia Analytics
- Manually
From Stambia Designer
The first way to publish a delivery is to do it directly from Stambia Designer.
With this method, you do not need to generate a Package before as the Designer will take care of everything.
This means that the configuration (connection properties, parameters, ...) of the delivery will be the one of the Designer at the moment it is generated.
The procedure for this is quite simple:
- Right click on the Mapping / Process
- From the menu, choose Publish > Delivery
The delivery will be automatically built locally and then published into the currently connected Runtime.
When publishing a delivery through the Designer, you do not have to perform the Delivery Generation step explained in this document.
The Designer take care of everything, build the delivery, and publish it on the currently connected Runtime.
The delivery being published, it can now be executed and scheduled.
From Stambia Analytics
Publishing a delivery can also be performed through Stambia Analytics.
After having imported the Package, configured it, and built the associated delivery, Stambia Analytics offers the possibility to publish it to Runtime(s).
This method is the recommended one for production use.
It offers the possibility to create configurations for each environment (development, test, production, ...) and easily build and deploy deliveries from a management web UI.
For more information, consult the Stambia Analytics documentation.
The delivery being published, it can now be executed and scheduled.
Manually
Finally, if the delivery is built from command line, you can also deploy it manually on the Runtime on which you want to execute it.
Simply copy the file inside the location where are stored the deliveries of this Runtime.
The default location is stambiaRuntime/build/deliveries
Delivery Execution
A delivery can be executed from Stambia, Stambia Analytics, or command line.
Two command line tools are available:
- startdelivery.sh: Creates a new Java process and executes the delivery as standalone outside a running Runtime.
- startcommand.sh: Connects to a Runtime. The execute delivery command can then be performed.
Tip: To optimize memory management, prefer the startcommand tool, as all the deliveries will be executed on a running Runtime, on the same Java process.
startDelivery command :
To proceed, with startdelivery:
./startdelivery.sh -name [DELIVERY_NAME]
Or
./startdelivery.sh -file [DELIVERY_FILE]
The script is synchronous: it waits for a return before handing back the commands to the caller.
The return code is:
- 0 if successful
- -1 if errors
- -2 if the session was stopped (properly killed by Stambia)
For Linux, the values are between 0 and 255, so the the return code is :
- 0 if successful
- 255 if errors
- -2 if the session was stopped (properly killed by Stambia)
Defining variables
The developer can also define Parameters that have to be valued when executing the delivery:
./startdelivery.sh -name [DELIVERY_NAME] -var [VARPATH1] [VALUE1] … -var [VARPATHN] [VALUEN]
Example:
./startdelivery.sh -name myDelivery -var ~/var1 value1
Defining configuration
When working with multi-Configuration deliveries, the Configuration to use must be specified in the command line:
./startdelivery.sh -name [DELIVERY_NAME] -configuration [CONFIGURATION_NAME]
Defining session name
By default the session name is the same as the delivery name, but you can override this value using the sessionName parameter :
./startdelivery.sh -name [DELIVERY_NAME] -sessionName [SESSION_NAME]
Defining repository
The repository, in which deliveries are stored, can also be defined with a parameter. Note that the repository must be configured in the Runtime.
./startdelivery.sh -name [DELIVERY_NAME] -repository [REPOSITORY_NAME]
Defining ReturnCode Path
This option allows to specify the path to a session variable containing the code to be used.
./startdelivery.sh -name [DELIVERY_NAME] -returnCodePath [VARIABLE_NAME)]
Examples :
./startdelivery.sh -name MyDelivery -returnCodePath CORE_DURATION
or
./startdelivery.sh -name MyDelivery -returnCodePath ~/MyProcess/MyVariable
For Linux, the values are between 0 and 255, so the the return code may be different.
Refer to this article for more information : https://tldp.org/LDP/abs/html/exitcodes.html
Defining log level
The log information that must be kept after execution can be specified in the command line:
./startdelivery.sh -name [DELIVERY_NAME] -loglevel [LOG_LEVEL]
Available values:
| Value | Description |
|---|---|
| -1 | Do not log anything (even errors won’t be logged) |
| 0 | Logs everything during execution and deletes everything at the end. |
| 100 | Logs everything during execution and deletes everything but the session and its stats. |
| 200 | Logs everything during execution and deletes everything but the session/processes and their stats. |
| 300 | Logs everything during execution and deletes everything but the session/processes/actions and their stats. |
| 400 | Everything is logged. |
Delivery Scheduling
The deliveries executions can be scheduled from different ways, as explained below.
External scheduling
External scheduling consists in scheduling the script startdelivery.sh
The return code is:
- 0 if successful
- -1 if errors
- -2 if the session was stopped manually (session was stopped before the end)
In addition to the return code, the command sends further information on the standard exit:
##### BEGIN #####
04/05/2011 17:22:11,718 - SESSION: e5b70658db3117952ad056f12fbb9a21e08000 is started
-- DURATION = 00:00:11,907
##### STATISTICS #####
SQL_NB_ROWS=177051
SQL_STAT_INSERT=37969
SQL_STAT_UPDATE=0
SQL_STAT_DELETE=37972
04/05/2011 17:22:23,671 - SESSION: e5b70658db3117952ad056f12fbb9a21e08000 is ended
##### END #####
Scheduling with Stambia scheduler
Scheduling basics
You will be scheduling deliveries.
The scheduler helps you schedule out jobs, using triggers.
If you wish to schedule a Stambia delivery, by default, the job will have the same name as the delivery.
You can however schedule a delivery with several different names (or jobs).
You can link one or several triggers to one job.
A job is unique (its name is also unique).
Scheduling with a command line
Once you are in the command line (using startcommand.bat or startcommand.sh), you need to connect to the Runtime on which you wish to schedule a job.
To connect to the local Runtime:
>connect
To schedule a job:
- with only one cron
>schedule delivery MY_DELIVERY cron "0 15 10 * * ? *"
- with a starting date and/or an ending date
>schedule delivery MY_DELIVERY start "2009/12/10 12:55:22" cron "0 15 10 * * ? *"
>schedule delivery MY_DELIVERY start "2009/12/10 12:55:22" end "2009/12/25 12:55:22" cron "0 15 10 * * ? *"
- with a variable
>schedule delivery MY_DELIVERY var ~/VAR1 VALUE1 var ~/VAR2 VALUE2 cron "0 15 10 * * ? *"
- with a configuration (for multi-Configuration deliveries)
>schedule delivery MY_DELIVERY configuration MY_CONFIGURATION cron "0 15 10 * * ? *"
- to get the schedules of a delivery
>get delivery schedules MY_DELIVERY
If you need more information about the command line:
>help
Cron Trigger tutorial
General syntax
A Cron expression is a character string containing 6 or 7 fields separated by spaces.
These fields can contain the characters listed in this table, or a combination of them.
| Field name | Mandatory | Authorized values | Authorized special characters |
|---|---|---|---|
| Seconds | YES | 0-59 | , - * / |
| Minutes | YES | 0-59 | , - * / |
| Hours | YES | 0-23 | , - * / |
| Day of the month | YES | 1-31 | , - * ? / L W |
| Month | YES | 1-12 or JAN-DEC | , - * / |
| Weekday | YES | 1-7 or SUN-SAT | , - * ? / L # |
| Year | NO | empty, 1970-2099 | , - * / |
Special Characters:
- « * » («all values») – used to select all the values for this field. For example, « * » in the minutes field means ‘every minute’.
- «?» («no specific value») – useful if you need to specify something in one of the two fields relevant to this special character, but not in the other one. For example, if you wish to set a trigger for a specific day in the month (let’s say the 10th), whatever the weekday. In this case, you will put ‘10’ in the ‘day of the month’ field, and ‘?’ in the ‘weekday’ field. For further understanding, check the examples.
- «-» used to specify an interval. For example, «10-12» in the ‘hour’ field means “hours 10, 11 and 12”.
- «,» – used to add more values. For example, «MON,WED,FRI» in the ‘weekday’ field means “Mondays, Wednesdays and Fridays”.
- «/» – used to specify repetition increments. For example, «0/15» in the ‘seconds’ field means “seconds 0, 15, 30 and 45”, in other words every 15 seconds, starting at 0 included. And «5/15» in the same field means «seconds 5, 20, 35, et 50». If you put ‘/’ with no number before and a number behind (for example ‘/5’) is equivalent to putting a 0 before the ‘/’. (i.e. ‘0/5’). Another example: ‹1/3› in the ‘day of the month’ field means “trigger every 3 days starting on the 1st of the month”.
- «L» («Last») – this character has different meanings depending on the field it is used in. For example, «L» in the ‘day of the month’ field means “the last day of the month”, i.e. the 31st for January, the 28th for February in non leap years. If ‘L’ is used in the ‘weekday’ field, it means the 7th day, i.e. Saturday (SAT). However, if ‘L’ is used in the ‘weekday’ field following a number, it will mean “the last X day in the month”; for example “6L” means “the last Friday in the month”. So as to have no ambiguity, it is advised not to use the ‘L’ character in value lists.
- «W» («weekday») – Used to specify the working weekday (Monday to Friday) that is nearest to a given date. For example, “15W” in the ‘day of the month’ field means “the working weekday the closest to the 15th”. So, if the 15th happens to be a Saturday, the trigger will position itself to Friday the 14th. And if the 15th happens to be a Sunday, the job will trigger on Monday the 16th. Take care, though, if you specify “1W” and the 1st happens to be a Saturday, the job will only be triggered on Monday the 3rd, since you cannot change the month. Also, ‘W’ will only work with unique values, not with intervals.
Characters ‘L’ and ‘W’ can be combined in the ‘day of the month’ field: “LW” will then mean “the last working weekday in the month”.
- «#» – used to specify “the n-th day XXX in the month”. For example, value «6#3» in the ‘weekday’ field means “the 3rd Friday of the month” (Day 6 = Friday, and #3 = the 3rd of the month).
Day names are not case-sensitive. This means ‘MON’ and ‘mon’ are identical.
Examples
| Expression | Meaning for the trigger |
|---|---|
| 0 0 12 * * ? | At 12 o’clock every day |
| 0 15 10 ? * * | at 10:15 every day |
| 0 15 10 * * ? | at 10:15 every day |
| 0 15 10 * * ? * | at 10:15 every day |
| 0 15 10 * * ? 2005 | at 10:15 every day of year 2005 |
| 0 * 14 * * ? | Every minute, between 14:00 and 14:59, every day |
| 0 0/5 14 * * ? | Every 5 minutes from 14:00 to 14:55, every day |
| 0 0/5 14,18 * * ? | Every 5 minutes from 14:00 to 14:55, every day, and every 5 minutes from 18:00 to 18:55, every day |
| 0 0-5 14 * * ? | Every minute from 14:00 to 14:05, every day |
| 0 10,44 14 ? 3 WED | at 14:10 and 14:44 every Wednesday of the month of March |
| 0 15 10 ? * MON-FRI | at 10:15 every Monday, Tuesday, Wednesday, Thursday and Friday |
| 0 15 10 15 * ? | at 10:15 on the 15th of each month |
| 0 15 10 L * ? | at 10h15 every last day of the month |
| 0 15 10 ? * 6L | at 10:15 the last Friday of each month |
| 0 15 10 ? * 6L 2002-2005 | at 10:15 the last Friday of each month for years 2002 to 2005 |
| 0 15 10 ? * 6#3 | at 10:15 the third Friday of each month |
| 0 0 12 1/5 * ? | at 12:00 every 5 days, each month, starting on the 1st |
| 0 11 11 11 11 ? | Every November 11th at 11:11 |
Runtime command reference
General commands
connect
Once you are in the command line (using startcommand.bat, startcommand.sh, ...), you need to connect to the Runtime with the connect command:
connect [to <host>] [port <port>] [silent]
| Parameter | Mandatory | Description |
|---|---|---|
| to <host> | No | Hostname or address of the host. If not set localhost is used. |
| port <port> | No | Runtime port. |
| silent | No | Avoids the feedback normally written on the standard output. |
runtime version
Return the version of the currently connected Runtime.
runtime version
execute commands in file
Execute a list of Runtime commands contained in a file.
execute commands in file <file>
| Parameter | Mandatory | Description |
|---|---|---|
| file <file> | Yes | Path to a file containing Runtime commands, separated with a line return |
Example of file:
execute delivery myDelivery synch
execute delivery myDelivery2
stop runtime
encrypt
Encrypt a password. The result can be used in various places in Stambia, especially in Process actions, when providing passwords manually.
It is possible to specify a custom ciphering key to choose which key will be used to encrypt the value.
This can be useful if you changed the ciphering keys used by the Runtime with your own ones.
If no ciphering key is specfied, the default Runtime ciphering key will be used.
encrypt <password>
encrypt <password> cipheringKey <key_functional_name>
The key used comes from a Keystore to also be declared in the EngineParameters.
stop runtime
Stop the currently connected Runtime properly.
The services are all stopped and by default, all running sessions are killed.
stop runtime [wait sessions]
| Parameter | Mandatory | Description |
|---|---|---|
| wait sessions | No | When set, the Runtime waits for all the sessions to be executed before stopping. No sessions can be started during this time (An exception will be thrown). |
kill runtime
Kill the currently connected Runtime.
kill runtime
help
Show a description and the list of parameters available for the Runtime commands.
help [on <commandName>]
| Parameter | Mandatory | Description |
|---|---|---|
| on <commandName > | No | Shows the help of a specific command. |
Service commands
Service management commands
Management of services. Stopping a service will not stop its running tasks. For example, stopping the execution service will not stop the currently running deliveries.
<start|stop|restart> <name> service
Example:
stop execution service
soap server
Management of soap server.
soap server [build|start|stop]
get services
Show information about status and running time of services.
get services [name <name>] [format <format>]
| Parameter | Mandatory | Description |
|---|---|---|
| name <name> | No | Specifies a service with its name. |
| format <format> | No | Columns to show on the output, separated with a comma. Available columns: %name, %status, %duration. |
Example:
get services format %name,%status
Result:
rmi,Running
rdbms,Running
execution,Stopped
soap,Running
listener,Running
scheduler,Running
versions
Return the version of the different services.
versions
Delivery management commands
execute delivery
Execute a delivery on the currently connected Runtime.
execute delivery <delivery> [mode <memory | standalone>] [configuration <configuration>] [var <varPath> <varName>] [synch] [sessionName <sessionName>] [repository <repositoryName>] [format <format>]
| Parameter | Mandatory | Description |
|---|---|---|
| mode | No | The «memory» mode starts the delivery in the current runtime and the «standalone» mode starts the delivery aside of the runtime. |
| configuration | No | When working with multi-Configuration deliveries, the Configuration to use must be specified with this parameter. |
| var <varPath> <varName> | No | Passes a Variable to the delivery. Multiple var parameters can be set. |
| synch | No | Waits for a return before handing back the commands to the caller. |
| sessionName | No | Can be used to customize the name of the session that will be executed, which defaults to the name of delivery if no set. |
| repository | No | Can be used to define the Runtime Delivery Repository in which the delivery will be searched. |
| format | No | This option can be used to customize the output of the command, which information to return and how. The following columns are available: %name,%status,%begindate,%enddate,%configuration,%id,%executionmode,%guesthost,%iter,%launchmode,%runtimehost,%runtimeport,%returncode,%errormessage,%exception,%parentiter |
Examples:
execute delivery myDeliv var ~/myVar1 value1 var "~/my var 2" "value 2"
execute delivery myDeliv repository MyRepo
execute delivery myDeliv format "%name, %id, %returncode"
execute delivery myDeliv format "%name | %id | %begindate | %enddate | %status | %returncode | %errormessage"
schedule delivery
Schedule a delivery on the currently connected Runtime.
schedule delivery <delivery> [scheduleName <scheduleName>] [sessionName <sessionName>] [jobName <jobname>] [with command] [on host <hostname>] [port <hostport>] [start <startDate>] [end <endDate>] [var <path> <value>] [var ...] [configuration <configuration>] cron <cronExpression>
| Parameter | Mandatory | Description |
|---|---|---|
| scheduleName <scheduleName> | No | Name that will identify this schedule, automatically generated if not set. |
| sessionName <sessionName> | No | Name of the session. If no set, the session is named after the delivery. |
| jobName <jobname> | No | Internal name for the schedule job. This is by default the delivery name. See below for further information. |
| with command | No | Executes the delivery with the command line tool. If no set, the delivery is invoked in memory in the currently connected Runtime. |
| on host <hostname> | No | Hostname or address of the Runtime host. If not set the currently connected Runtime is used. Can also be the name of a cluster (see this article for details on how to set up clustered runtimes). |
| port <hostport> | No | Runtime port. |
| start <startDate> | No | Start date of the schedule. |
| end <endDate> | No | End date of the schedule. |
| configuration | No | When working with multi-Configuration deliveries, the Configuration to use must be specified with this parameter. |
| var <varPath> <varName> | No | Passes a Variable to the delivery. Multiple var parameters can be set. |
| cron <cronExpression> | Yes | Cron expression to planify the schedule. |
Example:
schedule delivery myDeliv start "2015/12/10 12:55:22" end "2015/12/25 12:55:22" var ~/myvar myValue cron "0 15 10 * * ? *"
About the jobName
The jobName is used to identify the unicity of schedules.
Therefore, multiple schedules with the same jobName will not be able to be executed at the same time.
If this happens, only one of the two will be started.
This is to avoid the start of multiple schedules if their execution at the same time is not functionally possible.
This is, at purpose, the default behavior when having multiple schedules on the same delivery.
If you want to change that, just specify a jobName when scheduling a delivery.
Example: Two schedules that will not be able to be started at the same time:
schedule delivery myDeliv var ~/myvar myValue01 cron "0 15 10 * * ? *"
schedule delivery myDeliv var ~/myvar myValue02 cron "0 15 10 * * ? *"
Example: Two schedules that are allowed to start at the same time:
schedule delivery myDeliv jobName job01 var ~/myvar myValue01 cron "0 15 10 * * ? *"
schedule delivery myDeliv jobName job02 var ~/myvar myValue02 cron "0 15 10 * * ? *"
get repositories
Return the list of available Runtime delivery repositories.
get repositories
get deliveries
Return several information about the deliveries contained on the currently connected Runtime.
get deliveries [id <id1,id2,idn>] [format <format>] [repository <repository>]
| Parameter | Mandatory | Description |
|---|---|---|
| id <id1,id2,idn> | No | Deliveries ids, separated with a coma. |
| format <format> | No | Columns to show on the output, separated with a comma. Available columns: %name, %builduser, %configuration, %id, %packageid, %processid, %username, %version, %builddate, %exportdate. |
| repository <repository> | No | Runtime delivery repository to search in. If not set, the deliveries are search in the default repository. |
Example:
get deliveries format %name,%configuration,%builddate,%exportdate
get list deliveries
Retrieve the list of deliveries contained on the currently connected Runtime.
get list deliveries [to <file>]
| Parameter | Mandatory | Description |
|---|---|---|
| to <file> | No | Exports the result to a file. |
get delivery schedules
Retrieve information about delivery schedules, and optionally export it in a file. If a different job name has been specified during scheduling, it won’t appear in the list.
get delivery schedules <deliveryName> [to <file>]
| Parameter | Mandatory | Description |
|---|---|---|
| to <file> | No | Exports the result to a file. |
remove delivery
Remove / unpublish a delivery from the Runtime.
This operation will delete the delivery file from the Runtime.
remove delivery <name> [repository <repository>]
| Parameter | Mandatory | Description |
|---|---|---|
| name | Yes | Name of the Delivery to remove. |
| repository <repository> | No | Runtime delivery repository to search in for the delivery to remove. If not set, the delivery will be removed from the default repository. |
Session management commands
get sessions
Return the list of sessions existing in the Log Database configured for this Runtime as well as the sessions currently in memory.
get sessions [name <name>] [id <id1,id2,idn>] [status <running,error,done,stopped>] [duration <min>] [to <max>] [limit <limit>] [format <format>]
| Parameter | Mandatory | Description |
|---|---|---|
| name <name> | No | Session Name. |
| id <id> | No | Session Id. |
| status <status> | No | Session status. Available: running, error, done, stopped. |
| duration <min> | No | Session minimum duration in milliseconds. |
| to <max> | No | Session maximum duration in milliseconds. |
| limit <limit> | No | Number of sessions to retrieve. |
| format <format> | No | Columns to show on the output, separated with a comma. Available columns %name, %status, %begindate, %enddate, %configuration, %id, %deliveryid, %runtimehost, %runtimeport, %executionmode, %guesthost, %errormessage, %exception, %parentiter |
stop session
Sends a stop request to a specified running session.
stop session <id> [synch] [format <format>]
| Parameter | Mandatory | Description |
|---|---|---|
| id | Yes | Id of the session to be stopped. |
| synch | No | Waits for the session to be stopped before handing back the commands to the caller. If not specified the stop request is sent in the background and the command ends. |
| format | No | This option can be used to customize the output of the command, which information to return and how. This is supported only when using the synch mode. The following columns are available: %name,%status,%begindate,%enddate,%configuration,%id,%executionmode,%guesthost,%iter,%launchmode,%runtimehost,%runtimeport,%returncode,%errormessage,%exception,%parentiter |
Example 1:
stop session c0a84b0b016716c58c17de7b2e8a75c9
Result:
Sending a stop request to session c0a84b0b016716c58c17de7b2e8a75c9...
Stop request has been successfully sent to session c0a84b0b016716c58c17de7b2e8a75c9
Example 2:
stop session c0a84b0b016716c6b50bd39807324430 synch format %id,%status,%returncode
Result:
Sending a stop request to session c0a84b0b016716c6b50bd39807324430...
Session: c0a84b0b016716c6b50bd39807324430 is stopping...
c0a84b0b016716c6b50bd39807324430,STOPPED,-2
restart
Restarts a specified session.
restart session <id> [synch] [format <format>]
| Parameter | Mandatory | Description |
|---|---|---|
| id | Yes | Id of the session to be restarted. |
| synch | No | Waits for the restarted session to end before handing back the commands to the caller. If not specified the session is restarted in the background and the command ends. |
| format | No | This option can be used to customize the output of the command, which information to return and how. This is supported only when using the synch mode. The following columns are available: %name,%status,%begindate,%enddate,%configuration,%id,%executionmode,%guesthost,%iter,%launchmode,%runtimehost,%runtimeport,%returncode,%errormessage,%exception,%parentiter |
Example 1:
restart session c0a84b0b016716c58c17de7b2e8a75c9
Result:
Session: c0a84b0b016716c58c17de7b2e8a75c9 is restarted
Example 2:
restart session c0a84b0b016716c58c17de7b2e8a75c9 synch format %id,%status,%returncode
Result:
Session: c0a84b0b016716cadadf88fc29a8c399 is restarted...
c0a84b0b016716cadadf88fc29a8c399,ERROR,-1
wait session
Waits for a session until it ends.
wait session <id> [format <format>]
| Parameter | Mandatory | Description |
|---|---|---|
| id | Yes | Id of the session to connect to. |
| format | No | This option can be used to customize the output of the command, which information to return and how. When not specified the return code is printed. The following columns are available: %name,%status,%begindate,%enddate,%configuration,%id,%executionmode,%guesthost,%iter,%launchmode,%runtimehost,%runtimeport,%returncode,%errormessage,%exception,%parentiter |
Example 1:
wait session c0a84b0b016716cdb01b379e2eddf9a3
Result:
1
Example 2:
wait session c0a84b0b016716c58c17de7b2e8a75c9 format %id,%status,%returncode
Result:
c0a84b0b016716c58c17de7b2e8a75c9,EXECUTED,1
purge
Purge the Runtime’s sessions specified. All the information about these sessions will be deleted.
purge keep <number> <minute|hour|day|session> [sessionid <id1,id2,...>] [sessionname <name,name2,...>] [status <done,error,killed>]
| Parameter | Mandatory | Description |
|---|---|---|
| keep <number> <minute|hour|day|session> | Yes | Number of sessions to keep. |
| sessionid <id> | No | Sessions’ids, separated by a comma. |
| sessionname <name> | No | Sessions' names, separated by a comma. |
| status <done,error,killed> | No | Sessions' status, separated by a comma. |
Example:
Keep only last 100 sessions:
purge keep 100 session
Purge a session which id is mySessionid
purge keep 0 session sessionid mySessionid
Keep only five of the sessions which name is mySession and which status is done.
purge keep 5 session sessionname mySession status done
Keep sessions from last 3 days:
purge keep 3 day
schedule purge
Schedule a purge of Runtime’s sessions.
schedule purge keep <number> <minute|hour|day|session> cron <cronExpression> [sessionname <name,name2,...>] [sessionid <id1,id2,...>] [status <done,error,killed>] [on host <hostname>] [port <hostport>]
| Parameter | Mandatory | Description |
|---|---|---|
| keep <number> <minute|hour|day|session> | Yes | Number of sessions to keep. |
| cron <cronExpression> | yes | Cron expression to planify the purge. |
| sessionid <id> | No | Sessions' ids, separated by a comma. |
| sessionname <name> | No | Sessions' names, separated by a comma. |
| status <done,error,killed> | No | Sessions' status, separated by a comma. |
| on host <hostname> | No | Hostname or address of the Runtime host. If not set the currently connected Runtime is used. |
| port <hostport> | No | Runtime port. |
Example:
schedule purge keep 10 session cron "0 15 10 * * ? *"
Trigger commands
A trigger is created when a delivery or purge schedule is added.
get list triggers
Retrieve the list of triggers contained in the Runtime.
get list triggers [to <file>]
| Parameter | Mandatory | Description |
|---|---|---|
| to <file> | No | Exports the result to a file. |
get trigger detail
Retrieve detail of a specific trigger.
get trigger detail <triggerName> [to <file>]
| Parameter | Mandatory | Description |
|---|---|---|
| to <file> | No | Exports the result to a file. |
get triggers
Retrieve the list of triggers contained in the Runtime with details.
get triggers [name <name1,name2,namen>] [format <format>]
| Parameter | Mandatory | Description |
|---|---|---|
| name <name1,name2,namen> | No | Trigger name. |
| format <format> | No | Columns to show on the output, separated with a comma. Available columns %name, %cronexpression, %deliveryname, %executiontype, %starttime, %endtime, %nextexecution, %purgesize, %purgeunit, %jobname |
pause trigger
Pause the execution of a trigger.
pause trigger <name>
resume trigger
Resume the execution of a trigger.
resume trigger <name>
remove trigger
Remove a trigger.
remove trigger <triggerName>