Preface
Welcome to Stambia!
This guide contains information about using the product to design and develop a Data Integration project.
Tip: If you simply want to learn about Stambia and see what Stambia is all about, visit the Stambia website.
Audience
This document is intended for users interested in using Stambia for their Data Integration Initiatives : Business Intelligence, Data Migration, E-commerce projects, Web Services, etc..
Document Conventions
This guide uses the following formatting conventions:
| Convention | Meaning |
|---|---|
| boldface | Boldface type indicates graphical user interface associated with an action, or a product specific term or concept. |
| italic | Italic type indicates special emphasis or placeholder variable that you need to provide. |
monospace |
Monospace type indicates code example, text or commands that you enter. |
Other Stambia Resources
In addition to the product manuals, Stambia provides other resources available on its company website: www.stambia.com and community website www.stambia.org.
Obtaining Help
To get help you can:
- contact our global Technical Support Center: www.stambia.org/di/support.
- consult the articles on our community website www.stambia.org.
- consult or post topics on our forum on www.stambia.org.
Feedback
We welcome your comments and suggestions on the quality and usefulness of this documentation.
If you find any error or have any suggestion for improvement, please contact us at www.stambia.org/di/support and indicate the title of the documentation along with the chapter, section, and page number, if available. Please let us know if you want a reply.
Introduction to the Stambia Designer
Opening the Stambia Designer
To open the Stambia Designer:
- In the Stambia menu, click on the
stambiashortcut. - The Stambia Designer opens.
Stambia Designer Overview
The Stambia Designer appears as follows.
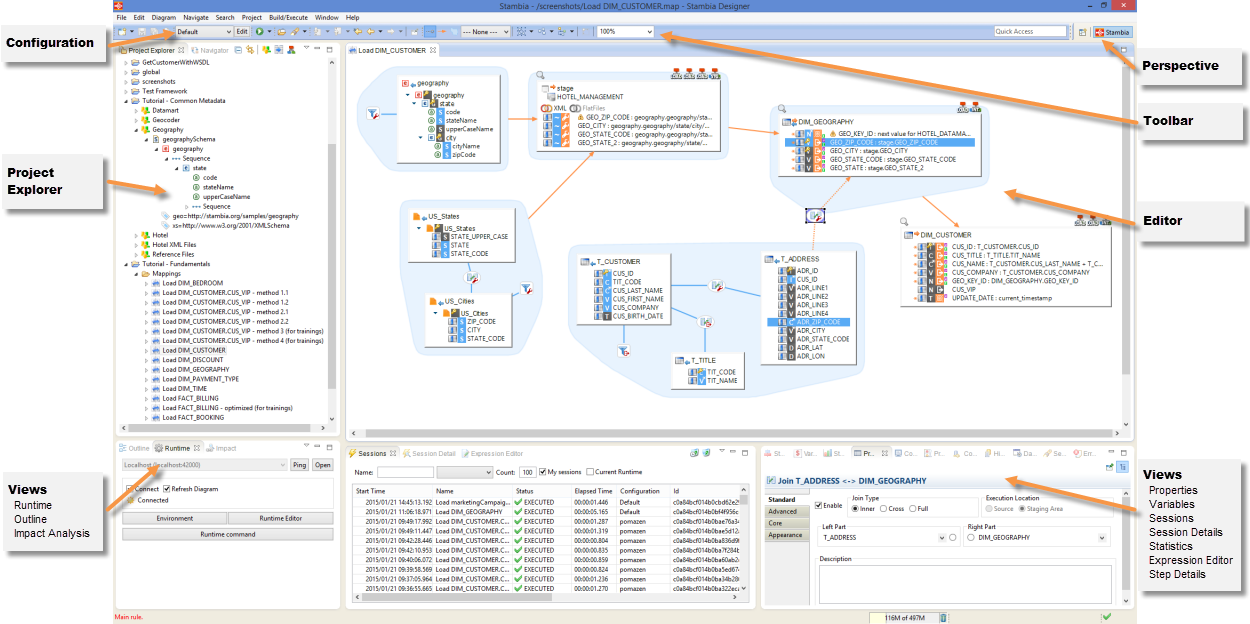
In the Stambia Designer, the following sections are available:
- The Project Explorer view provides a hierarchical view of the resources. From here, you can open files for editing or select resources for operations such as exporting.
- The Editors ' section contains the various objects being edited: mappings, metadata, processes, etc.
- Various other Views are organized around the edition view and allow navigating, viewing and editor object properties.
- The Configuration zone allows selecting the active Configuration (development, production, etc.).
- You can use the Perspectives to customize the layout of the various views in the Stambia Designer. A default Stambia perspective is created and it is possible to customize your own perspectives.
Design-Time Views
The following section describes the main views used at design-time.
The Project Explorer
The Project Explorer contains a hierarchical view of the resources in the workspace.
These resources are organized into projects and folders.
The following types of resources appear in the projects:
| Resource Type | File Extension | Description |
|---|---|---|
| Metadata | .md | A metadata resource describes source or target systems and datastores or variables that participate in a mapping or a process. |
| Mapping | .map | A mapping is used to load data between source and target datastores. |
| Process | .proc | A process is a sequence of tasks and sub-tasks that will be executed during run-time. Certain processes are Template Processes, which are used to generate a process from a mapping. |
| Templates Rules | .tpc | Templates Rules file describe the conditions upon which template processes can be used. For example, an Oracle integration template can be used when integrating data to a target datastore in an Oracle database, but is not suitable when targeting XML files. |
| Configuration Definition | .cfc | A configuration makes the metadata variable. For example, configurations can contain the connection information to the data servers and you can use configurations to switch between production and development environments. |
| Runtime Definition | .egc | Definition of a Runtime engine. A Runtime engine executes the integration processes created with the Stambia Designer. |
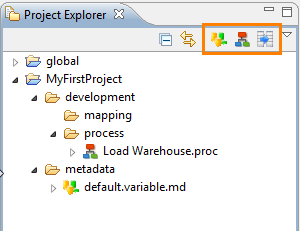
From the project explorer toolbar (highlighted in the previous screenshot) you can create the three main types of design-time resources: Metadata, Mappings and Processes.
Duplicate resources
Multiple resources with the same ID, called duplicates, can exist in the same Workspace.
Only one can be active at the same time, and is indicated with an asterisk at the end of the name:
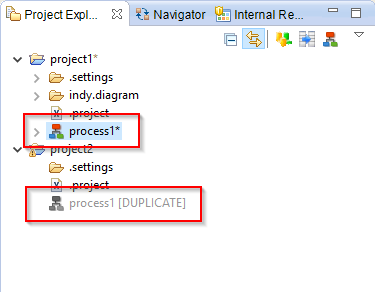
To enable a duplicate:
- Right click on it and select Enable Duplicate Model.
- The duplicated resource will become the active one.
Moreover, the Manage Duplicate Resource tool in the Impact View permits to manage the duplicates of the whole workspace.
The Properties View
The Properties view displays the list of properties of the object currently selected.
The Expression Editor
The Expression Editor displays code related to the object being edited. For example, the mapping expressions, the code of the actions, etc.
This editor provides two options:
- Lock: Allows you to lock the expression editor. When this option is not-selected the expression editor changes every time you select an element in the Stambia Designer to display the code of this element. To build expressions in the expression editor using drag-and-drop, you can select the element that you want to edit (for example, a target mapping), select the lock option and then drag and drop columns from the various source datastores of the mapping into the expression editor.
- Auto-Completion: This option enables auto-completion in the code. While editing, press CTRL+SPACE to have the list of suggestions for your code.
The Outline View
The Outline view provides a high-level hierarchical or graphical view of the object currently edited.
Moreover, it provides a search tool  , which permits to search into the current object.
, which permits to search into the current object.
The Impact View
The Impact view allows you to analyze the usage of an object in the project and perform impact analysis and cross-referencing.
To use the Impact Monitor:
- Select the object that you want to analyze. The Impact view displays the list of usages for this object.
- Double-click on one of the objects in the list to open it for edition.
The Impact Menu offers several tools:
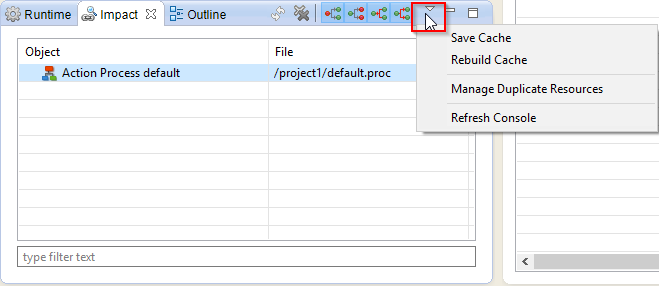
Save Cache and Rebuild Cache are used to explicitly refresh or save the cross-references cache for your workspace. In the normal course of operations, the cache is automatically refreshed.
Manage Duplicate Resource opens a new windows to manage the duplicated resources of the workspace.
Refresh Console refreshes the cache console (re-calculates mappings states, files states, cross-references, ...).
The Run-Time Views
Three views are used to monitor the run-time components and executions of the sessions.
The Runtime View
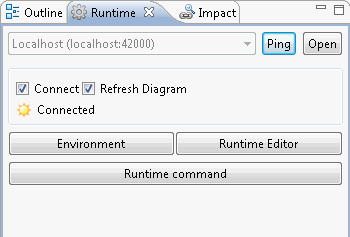
The Runtime view allows monitoring of a Runtime Engine.
From this view, you can perform the following operations:
- Click on the Environment button to start and stop a local (pre-configured) Runtime engine and demonstration databases.
- Click on the Runtime Editor button to add or modify Runtime engine definitions. The procedure to create a Runtime engine definition is described below.
- Check that a Runtime engine is active by selecting it in the list and clicking Ping.
- Connect a Runtime engine: Select it in the list and then Click on the Connect option. When a Runtime engine is connected, it is possible to view its sessions and issue commands to it via its command-line console.
- When connected to a Runtime engine, you can activate the Refresh Diagram option. When this option is active, you can monitor on the diagram of a process this process' activity as it runs in the Runtime engine.
- When connected to a Runtime engine, Click on the Runtime Command button to open its command-line console. From the Console you can issue commands to the Runtime engine. Type
helpin the console for a list of valid commands.
To create a new Runtime definition:
- In the Runtime view, Click on the Runtime Editor button. The Runtime definition (conf.egc) opens.
- Select the root node, right-click and select New Child > Engine.
- In the Properties view, enter the following information:
- Description: Description of this Runtime.
- Name: User-friendly name for the run-time.
- Server: Host name of IP address of the machine where the Runtime components run.
- Port: Port on this machine where the Runtime runs.
- Press CTRL + S to save the new Runtime definition.
The Sessions View
The Sessions view displays the list of sessions of the connected Runtime engine.
In this view, you can filter the sessions using parameters such as the session Name or Status, filter a number of sessions, or only the session started by the current user. If the log is shared by several Runtime engines, it is also possible to filter only sessions of the current Runtime engine.
From this view, you can also purge the log by clicking the Delete All and Delete Until buttons.
The list of sessions includes the following session properties:
- Start Time: Startup day and time of the session.
- Name: Name of this session.
- Status: Status of the session.
- Elapsed Time: Duration of the session.
- ID: Unique identifier of the session.
- Log Name: Name of the log storing this session.
- Log Type: Type of the log storing this session.
- Engine: Name of the Runtime engine processing the session.
- Guest Host: Name of the host from which the session was initiated.
- Launch Mode: Method used to start the session: Stambia Designer, Web Service, Scheduler, etc.
- Execution Mode: Memory or command line.
Statuses
| Status | Description |
|---|---|
| Prepared | Prepared but not executed sessions. |
| Running | Running sessions. |
| Executed | Executed sessions. |
| Error | Sessions in error. |
| Killed | Sessions killed by the user |
| Dead | Dead sessions, that is sessions that never finished and are considered as dead by Stambia Analytics |
Launch Modes
| Launch Mode | Description |
|---|---|
| Designer | The session has been executed from the Designer. |
| Schedule | The session has been executed automatically by a schedule. |
| Web Interactive | The session has been executed from Analytics. |
| Engine Command | The session has been executed from the Runtime Command utility (E.g. Using the ‹execute delivery› command). |
| Command Line | The session has been executed from command line (E.g. with startdelivery.bat). |
| Web Service | The session has been executed from the Runtime’s REST or SOAP web services. |
| Action | The session has been executed from the ‹Execute Delivery› Process Action. |
| Restart | The session has been restarted. |
Execution Modes
| Execution Mode | Description |
|---|---|
| Memory | The session has been executed in memory in the Runtime. |
| Autonomous | The session has been executed outside of the Runtime. |
The Session Detail View
This view displays the details of the session selected in the Sessions view. The Errors and Warning tabs display the list of issues, and the Variables tab displays the list of session and metadata variables.
Standard session variables include:
- CORE_BEGIN_DATE: Startup day and time of the session.
- CORE_DURATION: Duration of the session in milliseconds
- CORE_END_DATE: Day and time of the session completion.
- CORE_ENGINE_HOST: Host of the Runtime engine processing the session.
- CORE_ENGINE_PORT: Port of the Runtime engine processing the session.
- CORE_ROOT: Name of the process containing the session.
- CORE_SESSION_CONFIGURATION: Configuration used for this execution.
- CORE_SESSION_ID: Unique identifier of the session.
- CORE_SESSION_NAME: Name of this session.
- CORE_SESSION_TIMESTAMP: Session startup timestamp.
- CORE_TEMPORARY_FOLDER: Temporary folder for this session.
The Statistics View
The Statistics displays the list of statistics aggregated for the sessions.
The following default statistics are available:
- SQL_NB_ROWS: Number of lines processed.
- SQL_STAT_INSERT: Number of lines inserted.
- SQL_STAT_UPDATE: Number of lines updated.
- SQL_STAT_DELETE: Number of lines deleted.
- SQL_STAT_ERROR: Number of errors detected.
- OUT_FILE_SIZE: Output file size.
- OUT_NB_FILES: Number of output files.
- XML_NB_ELEMENTES: Number of XML elements processed.
- XML_NB_ATTRIBUTES: Number of XML attributes processed.
This view can be parameterized via the preferences (Window > Preferences), in the Stambia > Monitor section.
You can select which of the variables need to be aggregated using which aggregate function.
The Step Detail View
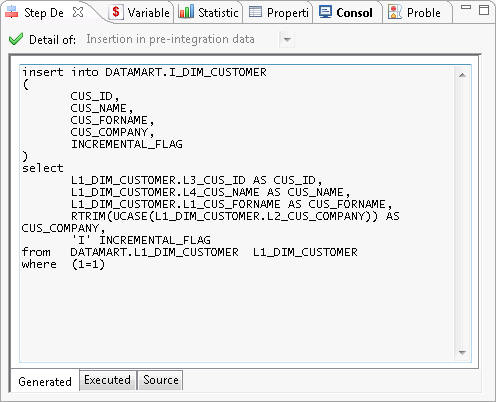
This view displays the details of the steps executed in a session.
It displays the code at various stages in three tabs:
- Source displays the source code before generation. It comes from the process templates.
- Generated displays the generated code. It may contain dynamic values replaced before execution.
- Executed displays the executed code with the variables replaced.
The Detail Of selection box allows you to select one of the iterations of a step that was executed several times.
The Variable View
The Variable view displays the variables for the selected step. The list of variables depends on the steps. The following standard variables appear for all steps:
- CORE_BEGIN_DATE: Startup day and time of the step.
- CORE_DURATION: Duration of the step in milliseconds
- CORE_END_DATE: Day and time of the step completion.
- CORE_BEGIN_ACTION: True if this action is a start action.
- CORE_NB_ENABLED_EXECUTIONS: Maximum number of executions allowed for this step. This variable is used in loops.
- CORE_NB_EXECUTION: Number of iterations of this step.
- CORE_RET_CODE: Return code for this step.
Working with Projects
Resources are organized into projects and folders.
In a Stambia workspace, there are two default projects:
- global contains all the objects global to this workspace, which include:
- The Runtime Engine Definition
- The Configuration Definitions
- The Template Processes are also imported in this project.
- .tech contains the definition of the various technologies supported by the platform. This project is hidden by default, and you do not need to modify this project.
Creating Projects
To create a new project:
- Right-click in the Project Explorer and then select New > Project in the context menu. The New Project wizard opens.
- In the Wizards filter, enter Project, and then select the General > Project item in the tree.
- Click Next.
- Enter a Project Name and then click Finish.
Creating Folders
To create a new folder:
- Right-click on a project or folder in the Project Explorer and then select New > Folder in the context menu. The New Folder wizard opens.
- Select the parent folder or project in the wizard.
- Enter a Folder Name and then click Finish.
You can organize folders within a project and resources within folders using drag and drop operations or using the Move action in a resource’s context menu.
A typical organization for a project is:
ProjectName(Project)metadata(folder): this folder contains all the metadata resources.development(folder): this folder contains all the development resources.process(folder): this folder contains all the processes.mapping(folder): this folder contains all the mappings.
Importing Templates
Stambia uses Templates to generate the code of processes for the mappings. By default, these templates are imported in the global project.
To import templates:
- In the Project Explorer, right-Click on the global project and select Import in the context menu. The Import wizard opens.
- In the tree view, select General > Archive File and then click Next.
- Use the Browse button to select the archive file containing the templates. This file is typically named
Templates.YYYY-MM-DD.zipwhereYYYY-MM-DDis a date corresponding to the template package release. Click OK. - When the file is selected, its contents appear in the wizard. Select all the templates, or only those relevant for your workspace.
- Click Finish to run the import. The imported templates appear in the global project, organized into folders.
Version Control
The Stambia workspace and the projects use exclusively file storage. They can be version controlled using a version control system compatible with Eclipse RCP, for example Subversion. Refer to the version control system documentation for more information.
Working with Metadata
Stambia uses metadata to design, generate and run the data integration processes. For example, the structure of the tables, text or XML files taken into account in the data integration flows.
A metadata file  handled by Stambia represents generally a data model. For example a database schema, a folder, etc, storing tables, files.
handled by Stambia represents generally a data model. For example a database schema, a folder, etc, storing tables, files.
A metadata file is created by connecting to the database server, file system, etc, to retrieve the structure of the tables, files, etc.. This mechanism is called reverse-engineering.
The following sections explain how to create the three main types of metadata files.
Defining a Database Model
Creating and Reversing a Database Model
This process uses a wizard that performs three steps:
- Create a new data server
- Create a new schema
- Reverse-engineer the datastores
To create a new data server:
- Click on the New Metadata button in the Project Explorer toolbar. The New Model wizard opens.
- In the Choose the type of Metadata tree, select RDBMS > <DBMS Technology> where <DBMS Technology> is the name of the DBMS technology that you want to connect.
- Click Next.
- Select the parent folder or project for your new resource.
- Enter a File Name and then click Finish. The metadata file is created and the Server wizard opens.
- In the Server Connection page, enter the following information:
- Name: Name of the data server.
- Driver: Select a JDBC Driver suitable for your data server.
- URL: Enter the JDBC URL to connect this data server.
- Un-select the User name is not required for this database option if authentication is required for this data server.
- User: The database user name.
- Password: This user’s password.
- (Optional) Modify the following options as needed:
- Auto Logon: This option allows the Stambia Designer to automatically create a connection to this data server when needed.
- Logon during Startup: This option allows the Stambia Designer to create a connection to this data server at startup.
- AutoCommit: Stambia Designer connections to this data server are autocommit connections.
- Commit On Close: Stambia Designer connections to this data server send a commit when they are closed.
- Click on the Connect button to validate this connection and then click Next. The Schema Properties page opens.
To create a new schema:
- In the Schema Properties page, enter the following information:
- Name: Use the checkbox to enable this field, and enter a user-friendly name for this schema.
- Schema Name: Click on the Refresh Values button to retrieve the list of schemas from the database, and then select one of these schemas.
- Reject Mask: Set the table name mask for the table containing the load rejects (error tables). See the Table Name Masks section below for more information.
- Reject Mask: Set the table name mask for the temporary load tables. See the Table Name Masks section below for more information.
- Integration Mask: Set the table name mask for the temporary integration tables. See the Table Name Masks section below for more information.
- Work Schema: Select a schema for storing the load and integration temporary tables for this data server. This schema is also referred to as the Staging Area. See the Work and Reject Schema Selection section for more information. Click on the ... button to create a new schema definition and set it as the work schema.
- Reject Schema: Select a schema for storing the errors (rejects) tables for this data server. See the Work and Reject Schema Selection section for more information. Click on the ... button to create a new schema and set it as the reject schema.
- Click Next. The Reverse Datastore page opens.
To reverse-engineer the datastores into a schema:
- In the Reverse Datastore page, optionally set an object filter. Use the
_and%wildcards to represent one or any number of characters. - Optionally filter the type of objects that you want to reverse-engineer: All, synonyms, tables and views.
- Click on the Refresh button to refresh the list of datastores.
- Select the datastores that you want to reverse engineer in the list.
- Click Finish. The reverse-engineering process retrieves the structure of these datastores.
- Press CTRL+S to save the editor.
Adding a New Schema
To add a new schema to an existing data server:
- In the metadata file editor, select the root node.
- Right-click and select Action > Launch DataSchema Wizard.
- Follow the steps described in the "To create a new schema" section of Creating and Reversing a Database Model.
Reverse-engineering an Existing Schema
To retrieve metadata changes from an existing schema, or to retrieve new table definitions, you must perform a new reverse-engineering.
To reverse-engineer an existing schema:
- In the metadata file editor, select the node corresponding to the schema.
- Right-click and select Action > Launch DataSchema Wizard.
- Click Next in the first page of the wizard.
- On the second page follow the steps described in the "To reverse-engineer the datastores in a schema" section of Creating and Reversing a Database Model.
Table Name Masks
Table name masks define name patterns for the temporary objects created at run-time.
Table Name masks can be any string parameterized using the following variables:
[number]: Automatically generated increment for the load tables, starting with 1.[targetName]: Name of the target table of a mapping.${variable}$or%{variable}%: A session variable that is set at run-time.
Note that the resulting string must be a valid table name.
Example: L_[targetName]_[number] would create Load tables named L_CUSTOMER_1, L_CUSTOMER_2, etc for a mapping loading the CUSTOMER table.
Work and Reject Schemas Selection
When defining a schema (with optionally a Name for this schema), you optionally refer to two other schemas, the Work Schema and Reject Schema.
These two schemas store respectively temporary load/integration tables (Staging Area) and the error (reject) tables for the data tables stored in the schema being defined. In the mappings, the work schema is also called the Staging Area.The value for these two schemas may be:
- Empty: In that case, the work schema and reject schemas are automatically set to the Schema Name. This means that the temporary and error tables are created in the same schema as the data tables.
- Set to the Name or Schema Name of another schema. In that case, the temporary or error tables are stored in this other schema’s Schema Name.
Tip: It is recommended to configure by default two separate temporary (for example,
STB_TEMP) and error (for exampleSTB_REJECTS) schemas for each database server and set them as the Work Schema and the Reject Schema for all the data schemas. This avoids mixing application data (data schemas) and Stambia tables in the same schemas.
Creating and using a Metadata Query
A SQL Query can be reversed and used in a database Metadata.
To create a Query:
- Right-click on the database node in the Metadata and select New > Query Folder. It will create a folder in which the queries will be stored.
- Give a name to the query folder which appeared in the Metadata.
- Finally, Right-click on it and select New > Query.
To reverse a Query:
- Give a name to the query.
- Enter a SQL SELECT query in the Expression.
- Save the Metadata.
- Right-click on the query and select Actions > Reverse
Note: The reversed query can be used in Mappings as Source like any other datastores. However, it is not recommended to use it as a Target as it only represents a query and is not a table.
Tip: It is possible to parameterize the query using xpath syntax: {./md:objectPath(ref:schema('schema_name'), 'table_name')} Note that the schema and table must exist on the metadata.
Defining a File Model
Creating a File Model
To create a new File metadata file:
- Click on the New Metadata button in the Project Explorer toolbar. The New Model wizard opens.
- In the Choose the type of Metadata tree, select File > File Server.
- Click Next.
- Select the parent folder or project for your new resource.
- Enter a File Name and then click Finish. The metadata file is created and the editor for this file opens.
- Select the Server node. In the Properties view, set the following properties:
- Name: A user-friendly name for this schema. The Server node is renamed with this name.
- Driver:
com.stambia.jdbc.driver.file.FileDriver - URL:
jdbc:stambia:file
- Right-Click on the root node of your file model editor, and then select Actions > Launch Directory wizard.
- In the Directory page, provide a user-friendly Name for the directory and select its Path.
- Click Next.
- In the File Properties page:
- Use the Browse button to select the file within the directory and set the Physical Name for the file.
- Set a logical Name for the file datastore.
- Select the file Type: Delimited or Positional (fixed width fields).
- Follow the process corresponding to the file type for reverse-engineering.
Reverse-Engineering a Delimited File
To reverse-engineer a delimited file:
- In the File Properties page, use the Refresh button to view the content of the file in the preview. Expand the wizard size to see the file contents.
- Set the following parameters to match the file structure:
- Charset Name: Code page of the text file.
- Line Separator: Character(s) used to separate the lines in the file.
- Field Separator: Character(s) used to separate the fields in a line.
- String Delimiter: Character(s) delimiting a string value in a field.
- Decimal Separator: Character used as the decimal separator for numbers.
- Lines to Skip: Number of lines to skip from the beginning of the file. This count must include the header.
- Header Line Position: Position of the header line in the file.
- Click Next.
- Click Reverse. If the parameters set in the previous page are correct, the list of columns detected in this file is automatically populated.
- Reverse-engineering parses through a number of lines in the file (defined by the Row Limit) to infer the data types and size of the columns. You can tune the reverse behavior by changing the Reverse Options and Size Management properties, and click Reverse again.
- You can manually edit the detected column datatype, size and name in the table.
- Click Finish for finish the reverse-engineering.
- Press CTRL+S to save the file.
Reverse-Engineering a Fixed-Width File
To reverse-engineer a fixed-width file:
- In the File Properties page, use the Refresh button to view the content of the file in the preview. Expand the wizard size to see the file contents.
- Set the following parameters to match the file structure:
- Charset Name: Code page of the text file.
- Line Separator: Character(s) used to separate the lines in the file.
- Decimal Separator: Character used as the decimal separator for numbers.
- Lines to Skip: Number of lines to skip from the beginning of the file. This count must include the header.
- Header Line Position: Position of the header line in the file.
- Click Next.
- Click Refresh to populate the preview.
- From this screen, you can use the table to add, move and edit column definitions for the file. As you add columns, the preview shows the position of the columns in the file.
- Click Finish to finish the reverse-engineering.
- Press CTRL+S to save the file.
Defining an XML Model
To create a new XML metadata file:
- Click on the New Metadata button in the Project Explorer toolbar. The New Model wizard opens.
- In the Choose the type of Metadata tree, select XML > XML Schema.
- Click Next.
- Select the parent folder or project for your new resource.
- Enter a File Name and then click Finish. The metadata file is created and the editor for this file opens.
- Right-Click on the Schema node in the editor and select Actions > Properties.
- In the Name field, enter a name for this schema.
- In the XML Path field, enter the full path to the XML file. This file does not need to physically exist at this location if you have the XSD, and can be generated as part of a data integration process.
- In the XSD Path field, enter the full path to the XSD describing the XML file. If this XSD does not exist, click Generate to generate an XSD from the content of the XML file provided in the XML Path.
- Click Refresh and then select the root element for this schema. If the XSD has several root nodes, it is possible to repeat this operation to reverse-engineer all the hierarchies of elements stored in the XML file. Each of these hierarchies can point to a different XML file specified in the properties of the element node.
- Click Reverse. The reverse-engineering process retrieves the XML structure from the XSD.
Defining a Generic Model
A Generic model is useful when you want to have custom Metadata available in order to parameterize your developments.
To define a Generic Model:
- Click on the New Metadata button in the Project Explorer toolbar. The New Model wizard opens.
- In the Choose the type of Metadata tree, select Generic > Element.
- Click Next.
- Select the parent folder or project for your new resource.
- Enter a File Name for your new metadata file and then click Finish. The metadata file is created and the editor for this file opens.
- Select the Element node and enter the Name for this element in the Properties view.
A Generic Model is a hierarchy of Elements and Attributes. The Attribute values can be retrieved for an element thanks to the Stambia usual Xpath syntax.
To create a new Element:
- Right-Click on the parent element.
- Select New > Element
- In the Properties view, enter the name of the new Element.
To add an attribute to an Element:
- Right-Click on the parent element.
- Select New > Attribute
- In the Properties view enter the Name and the Value of the Attribute. This name will be useful to retrieve the value of your attribute.
Working with Configurations
Configurations allow to parameterize metadata for a given context. For example, a single data model declared in Stambia may have two configurations, Production and Development. Used in the Development configuration it would point to a development server and used in the Production configuration it would point to a production server. Both servers contain the same data structures (as defined in the model), but not the same data, and have different connection information.
Creating a Configuration
To create a configuration:
- In the Stambia Designer toolbar, Click on the Edit button.
- The Configuration Definition editor (
conf.cfc) opens. - Right-Click on the root node (Cfc), then select New Child > Configuration.
- In the Properties view, enter the new configuration’s properties:
- Code: Code of the configuration. This code appears in the Configurations drop-down list in the Stambia Designer toolbar.
- Description: Description of the configuration.
- Execution Protection: Set to true if you want to be prompted for a password when executing a process in this configuration.
- Selection Protection: Set to true if you want to be prompted for a password when switching the Stambia Designer to this configuration.
- Password: Protection password for this configuration.
- Press CTRL+S to save the configuration.
Using Configurations
In a metadata file, it is possible to define configuration-specific values for certain properties. The following section describes the most common usage of the configurations in metadata files.
Using Configuration for Databases
In databases, you can customize the connection information to the data server as well as the data schema definitions using configuration.
To create a data server configuration:
- In the database metadata file editor, select the root node corresponding to your data server.
- Right-click and select New Child > DataServer Configuration.
- In the Properties view:
- Select the configuration in the Configuration Name field.
- Set the different values for the connection information (Driver, URL, User and Password) as required.
- Press CTRL+S to save the database metadata file.
To create a data schema configuration:
- In the database metadata file editor, select the node corresponding to your data schema.
- Right-click and select New Child > DataServer Configuration.
- In the Properties view:
- Select the configuration in the Configuration Name field.
- Set different values for the schema information (Schema Name, Reject Schema, etc.) as required.
- Press CTRL+S to save the database metadata file.
Note: You can define configurations at all levels in the database metadata file for example to define configuration-specific structural features for the datastores, columns, etc.
Using Configuration for Files
In files, you can customize the directory location as well as the file names depending on the configuration using a directory or a file configuration.
For example:
- in a development configuration, a file is located in the
C:\temp\directory and namedtestcustomers.txt - in a production configuration, a file is located in the
/prod/files/directory and namedcustomers.txt
To create a directory configuration:
- In the File metadata file editor, select the node corresponding to your directory.
- Right-click and select New Child > Directory Configuration.
- In the Properties view:
- Select the configuration in the Configuration Name field.
- Set a value for the Path specific to the configuration.
- Press CTRL+S to save the File metadata file.
To create a file configuration:
- In the File metadata file editor, select the node corresponding to your file.
- Right-click and select New Child > File Configuration.
- In the Properties view:
- Select the configuration in the Configuration Name field.
- Set a value for the Physical Name of the file specific to the configuration.
- Press CTRL+S to save the File metadata file.
Note: You can define configurations at all levels in the File metadata file for example to define configuration-specific structural features for flat files.
Using Configuration for XML
In XML files, you can customize the path of the XML and XSD files depending on the configuration using a schema configuration.
To create a schema configuration:
- In the XML metadata file editor, select the root node.
- Right-click and select New Child > Schema Configuration.
- In the Properties view:
- Select the configuration in the Configuration Name field.
- Set a value for the XML Path and XSD path specific to the configuration.
- Press CTRL+S to save the XML metadata file.
Note: You can define configurations at all levels in the XML metadata file for example to define configuration-specific structural features in the XML file.
Working with Mappings
Mappings  relate source and target metadata, and allow moving and transforming data from several source datastores (files, tables, XML) to target datastores.
relate source and target metadata, and allow moving and transforming data from several source datastores (files, tables, XML) to target datastores.
Designing a Mapping: Overall Process
The overall process to design a mapping follows the steps given below.
- Creating a New Mapping
- Adding the Targets and Sources
- Linking datastores
- Joining the Sources
- Mapping the Target Columns
- Filtering the Sources
- Staging the Sources
Creating a New Mapping
To create a new mapping:
- Click on the New Mapping button in the Project Explorer toolbar. The New Map Diagram wizard opens.
- Select the parent folder or project for your new resource.
- Enter a File Name and then click Finish. The mapping file is created and the editor for this file opens.
Adding the Targets and Sources
To add the source and target datastores:
- In the Project Explorer, expand the metadata file containing the datastore (table, file, XML file) that you want to integrate.
- Drag and drop the datastores into which data will be loaded (the targets) from the Project Explorer into the mapping editor.
- Drag and drop the datastores from which data will be extracted (the sources) from the Project Explorer into the mapping editor.
For each datastore that has been added:
- Select this datastore.
- In the properties view, set the following properties:
- Alias: Alias used in the expressions when referring to this datastore. It defaults to the datastore’s name.
- Use CDC: Check this box to enable consumption of changed data from a source datastore, captured via the CDC feature.
- Enable Rejects: Check this box to enable rejects management on a target datastore. When this option is selected, rows in the data flow not meeting the target table’s constraints are isolated into the rejects instead of causing a possible Runtime failure.
- Tag: Add a tag to the table. Tags are used in certain process templates.
- Description: Free form text.
- In the Advanced properties section, the Order defines the order of a source datastore in the FROM clause generated when loading a target.
- In the Advanced properties section, the Integration Sequence specifies the order in which tables without any mutual dependencies must be loaded.
Press CTRL+S to save the mapping.
Linking datastores
To create a link between 2 datastores:
- Select a column from a source datastore in the mapping diagram.
- While keeping the mouse button pressed, drag this column onto another source column in the mapping diagram.
- Release the mouse button. You will be prompted to select the type of link to create:
- Join: a new join will link the 2 datastores
- Map: a source-target relationship will be created between the two columns and their datastores
Note: You will be prompted to select the type of link only if Stambia Designer detects that both kind of links can be created. Otherwise the accurate type of link will be automatically created.
Note: When creating a source-target link between the datastores, blocks representing the load and integration process templates are automatically added to the upper part of the target datastore.
Note: When linking a source datastore to a target, the columns from the source are automatically mapped to the target datastore columns using column name matching.
Hint: If a join already exists between two datastores, drag-and-dropping a column between these datastores adds it to the existing join expression. If you want to create a new Join between those datastores, hold the CTRL key pressed while dropping the column
Defining a Join between Sources
When a join has been created:
- In the Expression Editor view, edit the code of the join. You can lock the expression editor and drag columns from the diagram into the expression editor. See the Mapping, Filter and Join Expressions section for more information about mapping expressions.
- Select the join in the mapping diagram.
- In the Properties view, set the following Standard Properties:
- Enable: Enables or disables the join.
- Set the join type by selecting either Join Type to Inner, Full or Cross or by selecting the Left Part or Right Part to perform a left outer or right outer join. See Join (SQL) for a definition of the join types.
- Set the Execution Location. The join may be executed within the source system (when joining two datastores in the same data server) or in the staging area.
- Description: Free form text.
- In the Properties view, optionally set the following Advanced Properties:
- Join Type: Explicit uses the ISO Syntax (join in the FROM clause), Implicit places the join in the WHERE clause, and Default takes the default type defined for the technology. This latter option is preferred for non-inner joins
- Order: Defines the order of the join when using the Explicit Join type.
- Press CTRL+S to save the mapping.
Warning: Be cautious when using Cross and Full joins as they may lead to a multiplication of rows and performance issues.
Note: When a Join is created between two datastores a blue area appears representing a set of datastores that are Joined together. This area is called a dataset.
Understanding conditional Joins
A conditional Join allows to activate a dataset and its corresponding join only if the driving dataset is used.
To define a conditional Join:
- Select the join
- In the Properties view, open the Advanced Properties
- Set the Activate property:
- Always: The join is not conditional and will always be executed
- With datastore's dataset: The conditional join will be activated only if the dataset containing the datastore is used.
Note: Conditional joins can be particularly useful to mutualize loads inside a Mapping.
Mapping the Target Columns
The target columns must be mapped with expressions using source columns. These expressions define which source columns contribute to loading data into the target columns.
When a map expression has been defined on a target column:
- Select the target column.
- In the Properties view, set the following Standard Properties:
- Enable: Enables or disables the mapping.
- Set the Execution Location. The mapping may be executed within the source system, in the staging area or in the target itself (while inserting data into the target).
- Use as Key: Check this option if this column must be used as part of the unique key for this mapping. Several columns participate to the unique key in the mapping. These may be the columns from one of the target table’s unique keys, or different columns. This unique key is used in the context of this mapping to identify records uniquely for reject management and target records update purposes.
- Enable Insert: Enable inserting data with this mapping.
- Enable Update: Enable updating data with this mapping.
- Aggregate: Indicates that this column contains an aggregate expression. Other (non-aggregated) columns are added in the GROUP BY clause of the queries.
- Tag: Add a tag to the mapping. Tags are used in certain process templates.
- Description: Free form text.
- Press CTRL+S to save the mapping.
Understanding Column Icons
Source and target columns have an icon that contains the first letter of their datatype. This icon appears in grey when the source column is not used in the mapping or when the target column is not mapped
In addition, target columns are tagged with icons to identify their key properties. The various icons and their meaning are listed in the following table.
| Icon | Meaning |
|---|---|
 |
The yellow key indicates that the column is part of the key. The white star in the upper left corner indicates that the column is not nullable. If reject management is activated, rows with null values for this column are rejected. The letter represents the column data type (I: Integer, V: Varchar, etc.) |
 |
The star in the upper right corner means that the column is not nullable and Stambia checks the null values for this column. |
 |
The cross in the upper right corner means that the column is not nullable but Stambia does not check the null values for this column. |
 |
No sign in the upper right corner means that the column is nullable and Stambia does not check the null values for this column. |
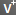 |
The plus sign in the upper right corner means that the column is nullable but Stambia checks the null values for this column. |
 |
This expression runs in the source. |
 |
This expression runs in the staging area. |
 |
This expression runs in the target. |
 |
These four letters have the following meaning when they appear:
|
Using Computed Fields
Computed fields are virtual fields, which are calculated on the fly during execution. They are only available during execution and are not stored.
To create a computed field on a mapping:
- Right-click on a column and select Create ComputedField
- A name for the container of the computed fields will be asked for the first created on the datastore.
- Finally, you can change the expression of the computed field to your needs.
Info Computed fields can be created only on objects having transformation capacities (RDBMS mostly, with SQL syntax)
Tip It is possible to create a computed field from an other computed field too. Usefull to chain transformations or operations.
Filtering the Sources
The data from the various source datastores may be filtered.
To create a filter:
- Select a column from a source datastore in the mapping diagram.
- While keeping the mouse button pressed, drag this column into the mapping diagram.
- Release the mouse button. A filter is created and appears in the diagram.
- In the Expression Editor view, edit the code of the filter. You can lock the expression editor and drag columns from the diagram into the expression editor. See the Mapping, Filter and Join Expressions section for more information about filter expressions.
- Select the filter in the mapping diagram.
- In the Properties view, set the following Standard Properties:
- Enable: Enables or disables the filter.
- Aggregate: Check this option if this filter is an aggregate and must produce a HAVING clause.
- Set the Execution Location. The join may be executed within the source system or in the staging area.
- Description: Free form text.
- Press CTRL+S to save the mapping.
Tip: It may be preferable to position the filters on the source to reduce the volume of data transferred from the source data server.
Info: To create a filter that must be executed only when a specific conditional join is activated, drag and drop the source column onto the conditional join itself and update the Expression.
Target filters
A filter can be configured to be activated only for one target.
Right-click on the filter and select Activate > For [...]
Staging the Sources
To create a new stage:
- In the Project Explorer select the schema where the stage will evaluate the expressions
- Drag and drop the schema onto the diagram
- Select the stage
- In the Properties view, set the following properties:
- Alias: Alias used in the expressions when referring to this stage.
- Tag: Add a tag to the stage. Tags are used in certain process templates.
- Description: Free form text.
- In the Advanced properties section, the Integration Sequence specifies the order in which tables and stages without any mutual dependencies must be loaded.
Add fields to the stage:
- Select the stage.
- Click on the
 button to add a new field to the Stage.
button to add a new field to the Stage. - In the Properties view, set the following properties:
- Alias: Alias used in the expressions when referring to this field.
- Enable: Enables or disables the mapping.
- Aggregate: Indicates that this column contains an aggregate expression. Other (non-aggregated) columns are added in the GROUP BY clause of the queries.
- Tag: Add a tag to the mapping. Tags are used in certain process templates.
- Description: Free form text.
Press CTRL+S to save the mapping.
Info: when you drop a schema on a link between sources and a target you create a stage that can be initialized by reusing the existing mapping expressions.
Info: you can also add fields to the stage by dragging a source field and dropping it on the stage.
Adding sets to a stage
To create a new set:
- Select the stage.
- Click on the
 button to add a new set to the Stage.
button to add a new set to the Stage. - In the Properties view, set the following properties:
- Alias: Alias used in the expressions when referring to this set.
- Description: Free form text.
- In the Expression Editor view, set the operators to use between the sets:
- Each set can be referred to as
[nameOfTheSet] - For example:
([A] union [B]) minus [C]
- Each set can be referred to as
- Select the set and map the fields in this set
Press CTRL+S to save the mapping.
Mapping, Filter and Join Expressions
For a mapping, filter or join, you specify an expression in the expression editor. These expressions are also referred to as the code of the mapping, filter or join.
The mapping, join or filter code can include any expression suitable for the engine that will process this mapping, filter or join. This engine is either the engine containing the source or target datastore, or the engine containing the staging area schema. You select the engine when choosing the Execution Location of the mapping, filter or join. This engine is typically a database engine. In this context, expressions are SQL expressions valid for the database engine. Literal values, column names, database functions and operators can be used in such expressions.
Examples of valid filter expressions:
CUSTOMER_COUNTRY LIKE 'USA'COUNTRY_CODE IN ('USA', 'CAN', 'MEX') AND UCASE(REGION_TYPE) = 'SALES'
Examples of valid join expressions:
CUSTOMER.COUNTRY_ID = COUNTRY.COUNTRY_IDUCASE(CUSTOMER.COUNTRYID) = GEOGRAPHY.COUNTRY_ID AND UCASE(CUSTOMER.REGIONID) = GEOGRAPHY.REGION_ID
Examples of valid mapping expressions:
- For the CUSTOMER_NAME field:
SRC.FIRST_NAME || ' ' || SRC.LAST_NAME - For the SALES_NUMBER aggregate field:
SUM(ORDERLINE.AMOUNT) - For an OWNER field:
'ADMIN'to set a constant value to this field.
Tip: When editing a Join or a Filter, think of it as a conditional expression from the WHERE clause. When editing a mapping, think of one expression in the column list of a SELECT statement.
Restrictions
- It is not possible to use a Stage as a source for another Stage if they are on different connections.
- A datastore can be joined or else mapped with another datastore, but not both actions at the same time.
Working with Processes
Processes  define organized sequences of Actions executed at run-time on the IT systems.
define organized sequences of Actions executed at run-time on the IT systems.
Processes are organized using Sub-processes, which are themselves composed of actions, sub-processes or References to other processes.
Creating a Process
Creating a new Process
To create a new process:
- Click on the New Process button in the Project Explorer toolbar. The New Process Diagram wizard opens.
- Select the parent folder of project for your new resource.
- Enter a File Name and then click Finish. The process file is created and the editor for this file opens.
- Press CTRL+S to save the process.
Adding a Mapping
To add a mapping to a process:
- Drag and drop first the mapping from the Project Explorer into the process editor. This mapping is added as a reference in the current process.
Adding an Action
To add an action:
- In the Palette, select the action that you want to add to the process. You can expand the accordions in the palette to access the appropriate action.
- Click in the process diagram. A block representing your action appears in the diagram.
- Right-Click this action and then select Show Properties View.
- In the Properties views, set the following values in the Standard section:
- Name: Name of the action. Use a naming convention for the action names as they are used in the variable path.
- Dynamic Name: Dynamic Name for this action. This name may change at run-time and is available through the CORE_DYNAMIC_NAME variable.
- Enable: Select this option to have this action enabled. Disabled actions are not executed or generated for execution.
- Error Accepted: Select this option to have this action complete with a Success status, even if it has failed.
- Is Begin Action: Select this option to declare this action explicitly as a startup action.
- Description: Detailed description of the action.
- In the Parameters section, set the action’s parameters. Each action has its own set of parameters.
- The mandatory parameters appear as editable fields. Enter values for these parameters.
- The optional parameters (possibly having a default value) appear as non-editable fields. Click on the field name to unlock the field value and then enter/select a value for these fields.
- Press CTRL+S to save the process.
Adding a Sub-Process
To add a sub-process:
- In the Palette, select the Process tool in the Component accordion.
- Click in the process diagram. A block representing your sub-process appears in the diagram.
- The focus is on this sub-process. Type in a name for this process and then press ENTER.
- A new editor opens to edit this sub-process.
Note: You can nest sub-processes within sub-processes.
Referencing another Process
For modular development, you can use another process within your process as a reference.
To reference another process:
- Drag and drop first the process that you want to reference from the Project Explorer into the process editor. This process is added as a reference in the current process.
- Select the referenced process step in the process diagram, right-click and then select Show Properties View.
- In the Parameters section, set the action’s parameters. Each process has its own set of parameters.
- Press CTRL+S to save the process.
Breadcrumb Trail
At the top of the process, a Breadcrumb Trail is displayed to navigate in the sub-processes.
By default, only the main process editor can be edited (main process and sub-processes created inside).
All process links (Mappings, reference to other processes, ...) are read only, to prevent modification of other processes by error.
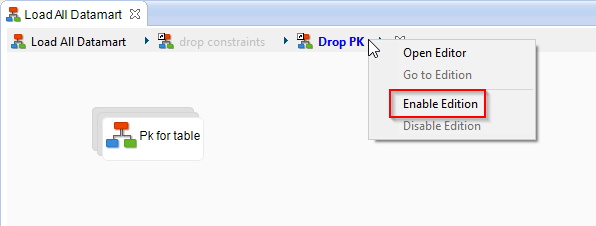
To enable the edition:
- Right click on a sub-process on the Breadcrumb Trail and click on Enable Edition. This will enable the edition directly inside this process.
- Right click on a sub-process on the Breadcrumb Trail and click on Open Editor. This will open a new editor for the selected sub-process.
Execution Flow
Steps Features
At a step level, a number of features impact the execution flow. These include Conditional Generation, Step Repetition and Startup Steps.
Conditional Generation
It is possible to make conditional the generation of given steps in a process.
For example, you can generate only certain steps in the process depending on the startup parameters of the process
To make a step’s generation conditional:
- Select the step in the process diagram, right-click and then select Show Properties View.
- In the Generation section, optionally set the following options:
- Generation Condition: Condition to generate the action code. If it is left empty, the action will be executed regardless of the condition. See Using Scripts in Conditions for more information.
- Press CTRL+S to save the process.
Step Repetition
Repetition allows you to generate a step several times to run in parallel or sequence. This repetition can be performed in parallel or sequence, and is done using the result of an XPath Query.
To enable step repetition:
- Select the step in the process diagram, right-click and then select Show Properties View.
- In the Generation section of an action or process:
- Provide an XPath Query. The action will be generated for each value returned by this query.
- Provide a Variable Name. This variable will contain each of the values returned by the query and pass them to the action. You can use this variable name in the action code.
- Specify whether this repetition must be Sequential or Parallel.
- In the Generation section of an action or process:
- Press CTRL+S to save the process.
Note: This repetition applies to the generation. It can be used for example to create one step for each table in a model.
Startup Steps
By default, all the steps with no incoming links are considered as startup steps. As a consequence, a process can start with several simultaneous steps.
In certain cases, (for example in the case of a process that is a loop) there is no step that can be identified as a startup step. In these cases, you must explicitly indicate the startup steps by checking the Is Begin Action option for these steps.
Classic Links
A classic link sequences two steps.
To add a classic link:
- In the Palette, select the OK Link tool in the Link accordion.
- Select a first step in the package diagram. While keeping the mouse button pressed, move the cursor onto another step and then release it. A link appears between the two steps.
- Right-Click this link and then select Show Properties View.
- In the link properties, set the following options:
- Generation Type: Define whether this link should be generated if the first step is Successful, Unsuccessful, or always (Anyway).
- Execution Type: Define whether this link should be triggered if the first step is Successful, Unsuccessful, or always (Anyway).
- Triggering Behavior: Define whether this link is Mandatory, Inhibitory or Not Mandatory for second step to run.
- Optionally set Generation and Execution Conditions for this link. See Using Scripts in Conditions for more information.
At execution time:
- When the first steps completes, depending on its completion status, the Generation Type and the Generation Condition, the link is created or not.
- Then the link is triggered depending on the first step’s completion status, the Execution Type and the Execution Condition.
- Finally, the second step runs depending on all the incoming links' Triggering Behavior value. For example:
- A step with two incoming Not Mandatory links (and no other) can start if one or the other link is triggered.
- A step with two incoming Mandatory links (and no other) can start only if both links are triggered.
- A step with one incoming Inhibitory link (and many others) will not run if this link is triggered.
Note: A default link is always generated (Generation Type=Anyway), triggered only if the first step is successful (Execution type=Successful) and Mandatory for the second step to execute.
Note: Links with conditions appear as dotted links.
Process Development
Process Parameters
A parameter is used to parameterize a process' behavior. The value of this parameter is passed when starting the process or when using it as a referenced process in another one.
To create a process parameter:
- In the Palette, select the Parameter tool in the Component accordion.
- Click in the process diagram. A block representing your parameter appears in the diagram.
- Right-Click this block and then select Show Properties View.
- In the Properties views, set the following values in the Core section:
- Name: Name of the parameter. Use a naming convention for these names since they are used in the variable path.
- Type: Type of the parameter.
- Value: Default Value for this parameter.
- Press CTRL+S to save the parameter.
To use a process parameter, refer to it as a variable in your code, using the ${<parameter_name>}$ syntax.
Direct Bind Links
The direct bind link is a specific type of link that allows you to run a target action once for each record returned by the source action.
For each iteration, the target action has access to the bind variables sent by the source, which can be used through the bind syntax::{column_name}:.
By default, the execution of a bind link stops as soon as one of the iteration fails.
The corresponding error is then thrown and the target action is put in error.
If needed, you can change this behavior to let all the iterations executes, even when an error occurs in one of them.
To accomplish this, simply uncheck the ‹Stop Bind On Error› parameter in the advanced tab of the target action.
Note: This parameter can only be changed on Actions targeted by a bind. Moreover, when multiple errors occur during the bind iterations, it is the first encountered that is thrown on the action at the end of the execution.
Warning: The ‹Stop Bind on Error› functionality requires Stambia DI Runtime S17.2.16 or higher.
Example with a SQL Operation action:
- The first action is a SELECT SQL Operation.
- The second action can be any action, including an INSERT/UPDATE/DELETE SQL Operation. This second action is repeated for each record returned by the select operation.
- The columns of the records returned by the select operation can be used in the second action using the bind syntax:
:{column_name}:.
For example, the first action performs the following SELECT query:
SELECT CUST_NAME, CUST_COUNTRY, CUST_CODE FROM CUSTOMER
The second action can generate a file with the following parameter
- TXT_WRITE_FILENAME:
/cust/docs/customer_:{CUST_CODE}:_content.txt
One file is written per customer returned by the select statement, named after the customer code (CUST_CODE).
Link Metadata to Actions
It is possible to link metadata to actions and processes.
A link allows you to use metadata information in actions without having to hardcode it. Instead, references to the metadata information are used in the actions.
When linking metadata to action, these metadata references are converted to metadata information at generation time, and the action code remains generic. If a link is made to another metadata file, or if the metadata is modified, then the action will use the new metadata information.
Note: Metadata Linking is used frequently to use within processes the connection information and other structural information (table names, list of columns, etc.) stored in metadata files.
Linking Metadata to a Process/Action
To link metadata to an action:
- Open the process that you want to modify.
- In the Project Explorer view, select the metadata that you want to link. For example a data store or a data server.
- Drag and drop the metadata onto the action in the diagram. It is added as a Metadata Link on the action element.
- Select this metadata link, right-click and then select Show Properties View.
- In the properties view, set the following parameters:
- Name: Name of the Metadata Link. This name is used to access the content in the metadata.
- Description: Description for the metadata link.
- Visibility: Define whether the link is visible for this current action or for the parent of the action too.
- Press CTRL+S to save the process.
Using the Metadata Connection
By linking actions (or processes containing actions) to a data server or schema defined in metadata file, you automatically use this data server or schema for the action. If the action required a SQL Connection, the SQL connection of the linked metadata is automatically used.
Using Metadata Specific Information
Through the metadata link, you can access specific information within the metadata. This information is accessed using an XPath query.
To use a value in a metadata link, in the code or any text field of the action, specify the XPath to the value.
Note that:
- You should use the Name set when defining the metadata link as a variable in the XPath expression.
- The XPath expression must be surrounded with
%x{...}x%in order to be interpreted accordingly and replaced by its value at run-time.
For example, a metadata link to a dataserver was named Local_XE. It is possible to use the following XPath to retrieve the JDBC URL of this data server in the action:
%x{ $Local_XE/tech:jdbcUrl() }x%
Working with Scripting
Scripting a feature helps you to customize the behavior of your processes.
You can use scripting in various locations in Stambia:
- In all the textual fields (conditions, texts, parameters, etc.) with the
%e(<language>){<script>}e(<language>)%syntax. In this context, the script is interpreted and the result of the script execution (return code) replaces the script in the field. - In the Java Native Scripting Actions steps.
Scripting Language
It is possible to specify the scripting language using the %e(<language>){...}e(<language>)% syntax.
In addition to JavaScript (Rhino), Groovy and Python (Jython) are supported.
For example:
%e(rhino){...}e(rhino)%%e(groovy){...}e(groovy)%%e(jython){...}e(jython)%
Using Session Variables
Stambia stores information about each action and process. This information is available as session variables.
These variables can be used in the code/text of an action, in its parameters, and in its metadata. Variables can also be used in scripts, for example in conditions.
The syntax to use a variable is ${variable_path}$ where variable_path is the path to the variable.
A variable belongs to an action or a process. This action or process may be contained in another process, and so on.
This organization is similar to a file system organization, with the main process at the root. You can access a variable with an absolute or relative path, depending on the location from which you request this variable.
For example if a process LOAD_DW contains a sub-process LOAD_DIMENSION which includes a sub-process LOAD_TIME which includes an action called WRITE_FILE, then the return code of this action is the following variable:
${LOAD_DW/LOAD_DIMENSION/LOAD_TIME/WRITE_FILE/CORE_RET_CODE}$
If you use this variable from the READ_FILE process within the LOAD_TIME sub-process, then the relative path is:
${../WRITE_FILE/CORE_RET_CODE}$
To use the return code of the current action, you can use:
${./CORE_RET_CODE}$
If the parent process' name is unknown, you can use the ~/ syntax:
${~/WRITE_FILE/CORE_RET_CODE}$
In the previous case, ~/ is replaced with LOAD_DW/LOAD_DIMENSION/LOAD_TIME/
Using Scripts in Conditions
Conditions may define whether:
- A link is generated or triggered (Link’s Generation and Execution Conditions)
- A step is generated (Step’s Generation Condition)
A condition:
- is a script that returns a Boolean value.
- may use session variables using the
${<variable>}$syntax.
The default language used for the conditions is JavaScript (Rhino implementation) and the interpreter adds the %e(rhino){...}e(rhino)% around the code in conditions.
Example of a condition: ${./AUTOMATION/CORE_NB_EXECUTIONS}$==1. The CORE_NB_EXECUTION variable (number of executions) for the AUTOMATION step should be equal to 1 for this condition to be true.
When a script is more complex than a simple expression, the context variable __ctx__.retvalue can be used to return the Boolean value from the script to the condition, as shown below.
%e(rhino){
/* Retrieves a session variable value */
myVarValue = '${~/MYVARIABLE}$';
if (myVarValue.substring(0,1).equals('R')) {
/* Returns true */
__ctx__.retValue = "true";
}
else {
/* Returns false */
__ctx__.retValue = "false";
}
}e(rhino)%
Note that this script also shows on line #3 the retrieval of the value for session variable MYVARIABLE.
Using the Scripting Context
When a script is interpreted, an object is passed to this script to provide access to the Runtime Engine features. This Context object is accessed using __ctx___.
This object provides a list of methods for manipulating variables and values as well as a return value used for code substitution and condition evaluation.
The following sections describe the various elements available with this object.
retValue Variable
The scripting context provides the retValue (__ctx__.retValue) variable.
This String variable is used to:
- return to the condition interpreter a Boolean value.
- return a string that replaces the script during code generation.
publishVariable Method
public void publishVariable(String name, String value) {}
public void publishVariable(String name, String value, String type) {}
This method is used to publish a session variable, and takes the following parameters:
- name: variable path.
- value: value of the variable.
- type: type of the variable. The default value is String. The possible values are: Float, Integer, Long, Boolean and String.
Example: Publish a string variable called INCREMENTAL_MODE with value ACTIVE on the parent element of the current action.
__ctx__.publishVariable("../INCREMENTAL_MODE","ACTIVE");
sumVariable, averageVariable, countVariable, minVariable and maxVariable Methods
public String sumVariable(String name) {}
public String sumVariable(String name, String startingPath) {}
public String averageVariable(String name) {}
public String averageVariable(String name, String startingPath) {}
public String countVariable(String name) {}
public String countVariable(String name, String startingPath) {}
public String minVariable(String name) {}
public String minVariable(String name, String startingPath) {}
public String maxVariable(String name) {}
public String maxVariable(String name, String startingPath) {}
These methods return the aggregated values for a variable. This aggregate is either a Sum, Average, Count, Min or Max.
The aggregate is performed within a given path.
This method takes the following parameters:
- name: Name of the variable
- startingPath: Path into which the variable values must be aggregated. If this parameter is omitted, the values are aggregated for the entire Session.
Example: Aggregate all the numbers of rows processed for LOAD_DIMENSION process and all its sub-processes/actions.
__ctx__.sumVariable("SQL_NB_ROWS","../LOAD_DIMENSION");
getCurrentBindIteration Method
public long getCurrentBindIteration() {}
This method returns the current bind iteration number. It takes no input parameter. See Direct Bind Links for more information about bind iterations.
getVariableValue method
public String getVariableValue(String path) {}
This method returns the value of a session variable, and takes the following parameter:
- path: Variable path.
Example: Retrieve the value of the CORE_SESSION_ID variable.
__ctx__.getVariableValue("/CORE_SESSION_ID");
getVariableCumulativeValue Method
public Object getVariableCumulativeValue(String name) {}
When an action iterates due to a bind or a loop, the variables store their value for the last iteration.
In addition, numerical values contain a cumulated value which can be retrieved.
This method takes the following parameters:
- Name: Path of the numerical variable.
getVariableTreeByName Method
public Map<String, IVariable> getVariableTreeByName(String name) {}
public Map<String, IVariable> getVariableTreeByName(String name, String startingPath) {}
public Map<String, IVariable> getVariableTreeByName(String name, boolean withErrors) {}
public Map<String, IVariable> getVariableTreeByName(String name, String startingPath, boolean withErrors)
This method returns a treeMap object containing the variables corresponding to certain criteria. It takes the following parameters:
- name: Name of the published variable.
- startingPath: Path from which the variable must be searched (The default value is
~/) - withErrors: Boolean value. If set to true, only the variables from steps in error are retrieved. It is set to false by default.
The returned Java Map object has the name of the action as the key and its value is a variable object with the following methods.
public Object getCumulativeValue(); // variable cumulated value (numbers only)
public String getShortName(); // variable name.
public String getName(); // variable name with path.
public String getActionName(); // action name with path.
public String getType(); // variable type.
public String getValue(); // variable value.
Usage example in Groovy: Retrieve the stack trace for all the steps in error.
%e(groovy){
def a = ""
def tree = __ctx__.getVariableTreeByName("CORE_STACK_TRACE","~/",true)
if (tree.size() != 0) {
def es=tree.entrySet()
es.each{
a = a+ "-- ACTION --> " + it.key + "\n"
a = a+ it.value.getValue() +"\n\n"
}
__ctx__.retValue = a
}
}e(groovy)%
Same example in JavaScript (Rhino):
%e(rhino){
importPackage(java.util);
a = "";
tree = __ctx__.getVariableTreeByName("CORE_STACK_TRACE","~/",true);
if (tree.size() != 0) {
for (i= tree.keySet().iterator() ; i.hasNext() ; ){
action = i.next();
maVar = tree.get(action);
a = a+ "-- ACTION --> " + action + "\n";
a = a+ maVar.getValue() +"\n\n";
}
__ctx__.retValue = a
}
}e(rhino)%
getLstVariablesByName Method
public List<IVariable> getLstVariablesByName(String name) {}
public List<IVariable> getLstVariablesByName(String name, boolean withErrors) {}
public List<IVariable> getLstVariablesByName(String name, String startingPath) {}
public List<IVariable> getLstVariablesByName(String name, String startingPath, boolean withErrors) {}
This method works like getVariableTreeByName, but returns a list of variables instead of a Java Map.
Usage example in Groovy:
%e(groovy){
def a = ""
def lst = __ctx__.getLstVariablesByName("V1","~/")
if (lst.size() != 0) {
for (var in lst) {
a =a + var.getValue() + "\n"
}
__ctx__.retValue = a
}
}e(groovy)%
Same example in JavaScript (Rhino):
%e(rhino){
importPackage(java.util);
a = "";
lst = __ctx__.getLstVariablesByName("V1","~/");
if (lst.size() != 0) {
for (i=0;i<lst.size();i++){
a = a+ "-- Value --> " + lst.get(i).getValue() +"\n";
}
__ctx__.retValue = a;
}
}e(rhino)%
createBindedPreparedStatement Method
public PreparedStatement createBindedPreparedStatement() {}
This method returns an object allowing to produce a custom set of Bind columns in Scripting, which can then be used through an outgoing Bind link.
This object allows to manipulate the column definition as well as publishing rows.
Definition of a column
The following methods can be used to define the properties of a column.
public void setColumn(int columnId, String columnName);
public void setColumn(int columnId, String columnName, String dataType)
public void setColumn(int columnId, String columnName, String dataType, int precision);
public void setColumn(int columnId, String columnName, String dataType, int precision, int scale);
Update of the properties
The following methods can be used to update the properties of a column.
public void setColumnName(int columnId, String columnName);
public void setColumnPrecision(int columnId, int precision);
public void setColumnType(int columnId, String dataType);
Definition of the value
The following methods can be used to set or update the value of a column in the current row.
public void setBigDecimal(int columnId, BigDecimal value);
public void setBoolean(int columnId, boolean value);
public void setBytes(int columnId, byte[] value);
public void setDate(int columnId, Date value);
public void setDouble(int columnId, double value);
public void setInt(int columnId, int value);
public void setLong(int columnId, long value);
public void setString(int columnId, String value);
public void setTime(int columnId, Time value);
public void setTimestamp(int columnId, Timestamp value);
Publish a new row
The following method can be used to publish a new row.
public int executeUpdate()
Example in Javascript (Rhino):
%e(rhino){
// Create the statement
ps=__ctx__.createBindedPreparedStatement();
// Definition of the columns
ps.setColumn(1,"TEST1"); // Set column 1
ps.setColumn(2,"TEST2","VARCHAR",255); // Set column 2
// First Bind Iteration
ps.setString(1,"VALUE1.1");
ps.setString(2,"VALUE2.1");
ps.executeUpdate();
// Second Bind Iteration
ps.setString(1,"VALUE3.1");
ps.setString(2,"VALUE3.2");
ps.executeUpdate();
}e(rhino)%
Tip: Use this method in Scripting Actions to create your own Bind columns. This can be useful to iterate on a list of values for example in scripting and use the result as Bind values in the target action.
executeCommand, executeCommands, executeRemoteCommand and executeRemoteCommands Methods
public String executeCommand(String command) {}
public String executeCommands(String commands, String separator) {}
public String executeRemoteCommand(String host, int port, String command) {}
public String executeRemoteCommands(String host, int port, String commands, String separator) {}
The executeCommand method enables you to execute a Stambia command on the current Runtime.
The executeCommands method enables you to execute a list of Stambia commands, separated by a defined character, on the current Runtime.
The executeRemoteCommand method enables you to execute a Stambia command on a remote Runtime.
The executeRemoteCommands method enables you to execute a list of Stambia commands, separated by a defined character, on a remote Runtime.
The available commands are the same as with the startCommand (.bat or .sh) shell program.
These methods return the standard output produced by the command’s execution.
The parameters are:
- command: command to be executed by the Runtime.
- commands: a list of commands to be executed by the Runtime, separated by a defined character.
- separator: separator used to separate the commands.
- host: You can specify in this parameter the Hostname or IP address of the remote Runtime that will execute the commands, or alternatively a cluster name when the current Runtime is configured to be able to execute on a Runtime cluster.
- port: RMI port of the remote Runtime.
Example:
%e(rhino){
__ctx__.executeCommand("versions");
__ctx__.executeCommands("versions;get deliveries",";");
__ctx__.executeRemoteCommand("localhost","43000","versions");
__ctx__.executeRemoteCommands("localhost","43000","versions;get deliveries",";");
}e(rhino)%
Note that the executeCommands and executeRemoteCommands methods return the results of the commands in a Java list of String values (java.util.ArrayList).
You can find below an example on how to access the results in a rhino scripting.
Example:
%e(rhino){
var results = __ctx__.executeCommands("versions;get deliveries",";");
// print the resut of the first command ("versions")
print(results.get(0));
//print the result of the second command ("get deliveries")
print(results.get(1));
}e(rhino)%
Working with Variables
Creating Variables in the metadata
Creating the Metadata file
Variables can be created as metadata with the «Variable Set» metadata type.

To create a new Variable set:
- Click on the New Metadata button in the Project Explorer toolbar. The New Model wizard opens.
- Select the Variable Set type.
- Choose a name and a folder to store the metadata file. The metadata file will be created
Creating the Variables
To create a new Variable:
- Right-Click on the Set node and choose New Child and Variable.
- In the properties tab, give a name to the Variable
Variables properties
| Name | Mandatory | Description |
|---|---|---|
| Name | yes | Name of the Variable |
| Type | Type of the Variable: String, Integer, Boolean or Float. The default value will be String. | |
| Refresh Query | Used if a Refresh Connection is defined. This query will be executed to retrieve a value for the Variable. In case of a query returning multiple rows or multiple columns (or both), the first column of the first row will used as the value | |
| Default Value | The default value of the Variable | |
| Saving Connection | Connection used to save the values of the Variable. A connection should be defined first. See below for more information. | |
| Refresh Connection | Connection used by the Refresh Query. A connection should be defined first. See below for more information. | |
| Default Operation | Operation used when invoking the Variable Manager. |
Associating connections to Variables
Connections can be defined and shared in the Variable Set.
This will allow
- to get values for the variable using a SQL order, through a refresh query defined on the variable
- to save and get the values of the Variables in a table
Defining a connection
To define a connection:
- Right-Click on the Set node and choose New Child and Connection.
- Give a name to the connection
- Drag and drop under the connection the metadata that you want to use for this connection.
Note: You can add several connections in the Variable Set.
Tip: You can use different types of metadata nodes in the connection: a server, a schema, a table or even a column. This can be useful to generate the proper SQL order for the refresh query.
Saving and Refreshing connections
Once the connections are defined in the Variable Set, they can be used to refresh or save the values of the Variables.
The Refresh and the save connections can be defined for each variable in the properties tab in its own combo box.
The Refresh and the save connections can also be defined on the Set node. In this case, all the variables for which connections are not defined will use these connections.
Using the metadata to generate proper SQL Orders
The node that has been defined on the connection can be used to generate the SQL orders.
The node, in fact, is a link to the Metadata.
In the Refresh Query, you can use the XPath or metadata functions provided by Stambia directly inside the { } enclosers.
If the metadata used in the connection is a schema, you can use the following syntaxes:
- To get the Schema name:
{ ./tech:physicalName() }
- To get a qualified name for an object (i.e. a table):
{ ./md:objectPath(.,'MYTABLE') }
If the metadata used in the connection is a table, you can use the following syntax:
{ ./tech:physicalPath() }
Using Variables in the Mappings
To use a Variable in a Mapping:
- Drag and drop the Variable node from the Metadata file into the Mapping. This will add the Variable as a new source in the Mapping.
- In the Mapping, drag and drop the Variable into the target column, the join or the filter expressions in which the Variable should be used.
In the Expression Editor the Variable will automatically have the following syntax:
%{VARIABLE_NAME}%
where VARIABLE_NAME is the name of the variable.
Using Variables in Processes
To use a Variable in a Process:
- Drag and drop the Variable node from the Metadata file into the Process diagram. This will instantiate the Variable Manager object with a predefined Metadata Link to the Variable. The predefined properties of the Variable will automatically be set on the Variable Manager when the Process will be generated (default value, connections, default Operation ...)
- Modify the properties in the Properties Tab view
Tip: if you want to retrieve a value from a table to parameterize a Mapping, you can instantiate a Variable in a Process as explained above. If the Variable has a Refresh Query, it will be used to retrieve the value. You can then use the Variable in the Mapping as explained in the previous sections.
Syntax to use Variables in Expressions
In order to use a Variable in an Expression (action text or parameter), you will have to instantiate the Variable in the Process, and use the following syntax:
%{VARIABLE_NAME}%
where VARIABLE_NAME is the name of the variable.
Using Variables in other Variables
In order to use a Variable in another Variable, there are two cases:
The two Variables are defined in the same Metadata file
In this case, you will just have to use the following syntax:
%{VARIABLE_NAME}%
where VARIABLE_NAME is the name of the Variable.
This syntax can be used in the query or in the default value.
The two Variables are defined in different Metadata files
In this case, before using the Variable inside another Variable, you will have to link the two Metadata files together:
- Open the destination Metadata file (the file in which is found the Variable that will receive the other Variable)
- Drag & drop the Variable node you want to use from its Metadata file to the opened Metadata file (on the Variable Set node)
- Use the following syntax:
%{VARIABLE_NAME}%
where VARIABLE_NAME is the name of the Variable.
This syntax can be used in the query or in the default value.
Using Variables in other Metadata
In order to use a variable in other Metadata properties (e.g. a Variable in a table condition), you will have to link the two Metadata files together:
- Open the destination Metadata file (the file in which is found the Metadata that will receive the Variable)
- Drag & drop the Variable node you want to use from its metadata file to the opened Metadata file
- Use the following syntax in the properties:
%{VARIABLE_NAME}%
where VARIABLE_NAME is the name of the Variable.
Working with External Value Resolvers
What is an External Value Resolver?
There are lot of dedicated technologies which allow to store values such as usernames, passwords, paths, and more... in dedicated stores.
The goal of those technologies, such as HashiCorp Vault, is to store and secure those values and then provide them when they are needed.
You can easily work with those technologies in Stambia through the «External Value Resolver» component which allows to retrieve values from external technologies. You can, as an example, specify in your Metadata that the username and password should be retrieved automatically from an external system, which avoids keeping that sensitive information in your Metadata.
Configuring External Value Resolvers
When you want to retrieve values from external systems, you first have to configure External Value Resolvers.
An External Value Resolver is simply a configuration which allows to specify all required information to access the external system. You can define multiple resolvers and use all of them during your developments.
External Value Resolvers are configured in the Runtime and can then be used in your developments when you want to retrieve values from them automatically.
Refer to Runtime Installation and Configuration Guide for further information on how to configure External Value Resolvers.
As External Value Resolvers are configured in Runtime, you must contact your Runtime administrator to know what resolvers are available and configured on it.
Using an External Value Resolver
Once your resolvers are configured in your Runtime, you can resolve values through, using the following generic syntax:
%ext{[<resolver prefix>]<key path>}ext%
- resolver prefix: The resolver prefix must correspond to the prefix of the External Value Resolver you want to access. If the resolver you try to access does not have a prefix defined, you can omit this part.
- key path: This part represents the key you want to retrieve. Depending on the resolver and plugin used, the key path to define will be different. Refer to the documentation of the resolver you are using to find the syntax of the path. When using HashiCorp Vault, for instance, the key path is the Vault’s key path, such as kv/secrets/database/username.
Plugin – Simple External Value Resolver
Stambia is shipped with a simple external value resolver plugin which is available on a default installation.
It’s a sample resolver which allows to define key / value information directly inside this dedicated plain text file.
You can access values of simple external value resolvers in your developments through the generic syntax:
%ext{[<resolver prefix>]<key path>}ext%
For the Simple External Value Resolver Plugin, the key path is simply the key name, for instance:
%ext{my_prefix_simple/key_a}ext%
Then, at execution this will be replaced automatically by the value of the «key_a» key, which will be resolved through the resolver having the prefix «my_prefix_simple».
Plugin – Vault External Value Resolver
Stambia proposes a Vault external value resolver plugin which is available as an addon.
It’s a resolver which allows to retrieve values from HashiCorp Vault servers.
You can access values of a Vault External Value Resolver in your developments through always the generic syntax:
%ext{[<resolver prefix>]<key path>}ext%
For the Vault External Value Resolver Plugin, the key path is the Vault’s path to access the key.
%ext{my_prefix_vault/kv/secrets/database/username}ext%
Then, at execution this will be replaced automatically by the value retrieved from Vault for the given path.
Note that if you configured a «startPath» on your Vault Resolver, the start path is added automatically at the beginning of the key path when resolving the value, so you must define only the last part of the key path.
As an example, if the startPath configured on the resolver is kv/secrets and you want to retrieve a Vault key which has the following path kv/secrets/database/username, you will need to retrieve it as follow.
%ext{my_prefix_vault/database/username}ext%
Limitations
For now, only the Runtime is able to resolve values from External Value Resolvers.
The external value syntax will therefore only be resolved when executing Mappings / Processes.
The various wizards in Designer does not support yet resolving such syntax. If you need to use wizards to perform connections, reverse, or SQL Editor for instance, all information required by the wizards, such as connection information, username, password, ... must be real values and not external values.
You can use Configurations for instance to have a dedicated Configuration with real values instead of external values when you need to use wizards.
Note also that values retrieved from external systems must be defined as plain text in this external system. For instance, if you want to retrieve a password from an external value resolver, the retrieved password should not be encrypted in the external system, because the Runtime might not be able to decrypt it.
Troubleshooting
Refer to Runtime Installation and Configuration Guide for further information about Troubleshooting.
Working with Restart Points
When a process failed (with an error or a killed status), it can be restarted.
By default, it will restart from the steps that had an error status.
In a process you can also open and close "Restart Points" to define other ways to restart.
In case you have defined Restart Points, if the process fails without reaching the step on which the Restart Point is closed, the process will restart from the Restart Point above the failed step.
Note that you can have several Restart Points. If the process fails, it will restart, for each failed step, on the last Restart Point above the failed step.
Opening a restart point
To open a restart point:
- Right-Click on the step in the process
- Choose «Restart Point» and "open"
- This will add the following icon:

Closing a restart point
To close a restart point:
- Right-Click on the step in the process
- Choose «Restart Point» and "close"
- This will add the following icon:
