Welcome to Stambia MDM.
This guide contains information about using the product to design and develop an MDM project.
Preface
Audience
| If you want to learn about MDM or discover Stambia MDM, you can watch our tutorials. |
| The Stambia MDM Documentation Library, including the development, administration and installation guides is available online. |
Document Conventions
This document uses the following formatting conventions:
| Convention | Meaning |
|---|---|
boldface |
Boldface type indicates graphical user interface elements associated with an action, or a product specific term or concept. |
italic |
Italic type indicates special emphasis or placeholder variable that you need to provide. |
|
Monospace type indicates code example, text or commands that you enter. |
Other Stambia Resources
In addition to the product manuals, Stambia provides other resources available on its web site: http://www.stambia.com.
Obtaining Help
There are many ways to access the Stambia Technical Support. You can call or email our global Technical Support Center (support@stambia.com). For more information, see http://www.stambia.com.
Feedback
We welcome your comments and suggestions on the quality and usefulness
of this documentation.
If you find any error or have any suggestion for improvement, please
mail support@stambia.com and indicate the title of the documentation
along with the chapter, section, and page number, if available. Please
let us know if you want a reply.
Overview
This guide contains information about using the product to design and develop an MDM project.
Using this guide, you will learn how to:
-
Use the Stambia MDM Workbench to design and develop an MDM project.
-
Design the logical model representing your business entities.
-
Design the integration process for certifying golden data from data published from source systems.
-
Deploy the logical models and run the integration processes developed in Stambia MDM Workbench.
| If you want to try Stambia MDM, you can use our demonstration environment and getting started guide: Getting Started with Stambia MDM. |
Introduction to Stambia MDM
Stambia MDM is designed to support any kind of Enterprise Master Data Management initiative. It brings an extreme flexibility for defining and implementing master data models and releasing them to production. The platform can be used as the target deployment point for all master data of your enterprise or in conjunction with existing data hubs to contribute to data transparency and quality with federated governance processes. Its powerful and intuitive environment covers all use cases for setting up a successful master data governance strategy.
Stambia MDM is based on a coherent set of features for all Master Data Management projects.
Unified User Interface
Data architects, business analysts, data stewards and business users all share the same point of entry in Stambia MDM through the single Stambia MDM Workbench user interface accessible through any type of browser. This interface uses rich perspectives to suit every user role and allows team collaboration. The advanced metadata management capabilities enhance the usability of this intuitive interface.
A Unique Modeling Framework
Stambia MDM includes a unique modeling framework that combines both ER and OO modeling with concepts such as inheritance or complex types. Data architects and business analysts use this environment to define semantically complete models that will serve as references for the enterprise. These models include the description of the business entities as well as the rules associated with them.
The Modeling Framework supports:
-
Logical Data Modeling: The expression of the logical data model semantics and rules by business analysts. This includes:
-
The target data model (Entities / Attributes / Relations / List of Values, etc.).
-
The rules for data quality (validations, referential integrity validation, list of values, etc.).
-
The functional decomposition of the model.
-
-
Integration Process Logical Design. This includes:
-
The definition of applications that publish data to the Hub (Publisher)
-
The rules to enrich and standardize data
-
The rules to match and to identify groups of similar records
-
The consolidation rules to produce the reference data (Golden Data)
-
-
Master Data Applications. This includes:
-
The definition of the data consumers via roles
-
The definition of the Privileges associated with these data consumers
-
Assembling the entities from the model into Business Objects
-
Defining views on these Business Objects
-
Assembling the Business Objects to create Application accessed by the business users and data stewards.
-
-
Master Data Workflows Design. This includes:
-
Creating human workflows for managing duplicates.
-
Creating human workflows for data entry or error fixing.
-
Data and Metadata Version Management
The innovative Stambia MDM technology supports an infinite number of
versions and branches of data and metadata. The collaborative process
between the different governance teams set the rules to close the
editions of metadata and data to keep full traceability or to run
multiple projects in parallel.
During the modeling phase, the data architect and business analysts
create their metadata definition until the first semantically data model
is finished. This model is then frozen in an edition and eventually
delivered to production. Subsequent iterations of the data model are
automatically opened. This allows Stambia MDM users
to replay the entire cycle of metadata definition. At any time, project
managers may choose to branch the developments in order to develop two
versions of the model in parallel.
Master Data in a Stambia MDM hub can also be managed with versions. Business processes specific to the enterprise set the rate at which data must be frozen in these versions. A consumer can access data in particular edition of the data and can see the data as it was at a particular moment in time. As a consequence, the company can develop a strategy for managing versions of data, for example during the introduction of new major versions of a model, for simulation projects and what-if analysis, or when launching new catalogs.
Golden Data Certification
Stambia MDM supports the integration of data from any source in batch mode, asynchronous or synchronous mode. The platform manages the lifecycle of data published in the hub. This data is pushed by publishers through existing middleware (ETL, SOA, EAI, Data Integration, etc.). The platform provides standards APIs such as SQL for ETLS, Java and Web Services integration for real-time publishing. The certification process follows a sequence of steps to produce and make available certified reference data (Golden Records). These steps apply all the logical integration rules defined in the modeling phase to certify at all times the integrity, quality and uniqueness of the reference data.
With its Open Plug-in Architecture Stambia MDM can delegate stages of the certification process to any component present in the information system infrastructure.
Generated Master Data Applications
Stambia MDM support Master Data Applications generation. These applications provide secured and filtered access to the golden and master data of the hub in business-friendly views in a Web 2.0 interface. Applications also support customized Human Workflows for duplicate management and data entry.
Golden Data Consumption
The certified data is stored in a relational database, which allows Stambia MDM to benefit from higher performance and scalability. The data is made available to consumers across multiple channels to allow a non-intrusive integration with the information system:
-
SQL access to reference data using JDBC or ODBC.
-
SOAP WebService for SOA: The platform generates Web Services to access the reference data from any SOA-enabled system.
Built-in Metrics & Dashboards
The Stambia MDM Pulse component enables business users to collect metrics and measure - with dashboards and KPIs - the health of their Stambia MDM Hub.
Introduction to the Stambia MDM Workbench
Logging In to the Stambia MDM Workbench
To access Stambia MDM Workbench, you need a URL, a user name and password that have been provided by your Stambia MDM administrator.
To log in to the Stambia MDM Workbench:
-
Open your web browser and connect to the URL provided to you by your administrator. For example
http://<host>:<port>/stambiamdm/where<host>and<port>represent the name and port of host running the Stambia MDM application. The Login Form is displayed. -
Enter your user name and password.
-
Click Log In. The Stambia MDM Welcome page opens.
-
Click the Stambia MDM Workbench button in the Design and Administration section. The Stambia MDM workbench opens on the Overview perspective.
Logging Out of the Stambia MDM Workbench
To log out of the Stambia MDM Workbench:
-
In the Stambia MDM Workbench menu, select File > Log Out.
Opening a Model Edition
A model edition is a version of a model. This edition can be in a closed
or open status. Only open editions can be edited.
Opening a model edition connects the workbench to this edition.
| Before opening a model edition, you have to create this model and its first edition. To create a new model and manage model editions, refer to the Models Management chapter. |
To open a model edition:
-
In the Stambia MDM Workbench menu, select File > Open Model Edition
-
In the Open a Model Edition dialog, expand the node for your model and then select a branch in the branch tree. The list of Model Editions for this branch is refreshed with the editions in this branch.
-
Select an edition in this list and then click Finish.
-
The Stambia MDM Workbench changes to the Model Edition perspective and displays the selected model edition.
Working with the Stambia MDM Workbench
The Stambia MDM Workbench is the graphical interface used by all Stambia MDM users. This user interface exposes information in
panels called Views and Editors .
A given layout of views and editors is called a Perspective .

Working with Perspectives
There are several perspectives in Stambia MDM Workbench:
-
Overview: this perspective is the landing page in the Workbench. It allows you to access all the other perspectives and the applications.
-
Model Design: this perspective is used to edit or view a model.
-
Data Locations: this perspective is used to create data locations as well as deploy and manage model and data editions deployed in these locations.
-
Model Administration: this perspective is used to manage model editions and branches.
-
Administration Console: this perspective is used to administer Stambia MDM and monitor run-time activity.
Working with Tree Views
When a perspective opens, a tree view showing the objects you can work
with in this view appears.
This view appears on the left hand-side of the screen.
In this tree view you can:
-
Expand and collapse nodes to access child objects.
-
Double-click a node to open the object’s editor.
-
Right-click a node to access all possible operations with this object.
Working with the Outline
Certain perspectives includes an Outline view. This view shows in tree
view form the object - and all its child objects - in the editor
currently opened.
This view appears on the left hand-side of the screen.
You can use the same expand, double-click, right-click actions in the
outline as in the tree view.
Working with Editors
An object currently being viewed or edited appears in an editor in the
central part of the screen.
You can have multiple editors opened at the same time, each editor
appearing with a different tab.
Editor Organization
Editors are organized as follows:
-
The editor has a local toolbar which is used for editor specific operations. For example, refreshing or saving the content of an editor is performed from the toolbar.
-
The editor has a breadcrumb that allows navigating up in the hierarchy of objects.
-
The editor has a sidebar which shows the various sections and child objects attached to an editor. You can click in this sidebar to jump to one of these sections.
-
Properties in the editors are organized into groups, which can be expanded or collapsed.
Saving an Editor
When the object in an editor is modified, the editor tab is displayed
with a star in the tab name. For example, Contact* indicates that the
content of the Contact editor has been modified and need to be saved.
To save an editor, either:
-
Click the Save button in the Workbench toolbar.
-
Use the CTRL+S key combination.
-
Use the File > Save option in the Workbench menu.
You can also use the File > Save All menu option or Save All toolbar button to save all modified editors.
Closing an Editor
To close an editor, either:
-
Click the Close (Cross) icon on the editor’s tab.
-
Use the File > Close option in the Workbench menu.
-
Use the Close option the editor’s context menu (right-click on the editor’s tab).
You can also use the File > Close All menu option or the Close All option the editor’s context menu (right-click on the editor’s tab) to close all the editors .
Accelerating Edition with CamelCase
In the editors and dialogs in Stambia MDM Workbench, the Auto Fill
checkbox accelerates object creation and edition.
When this option is checked and the object name is entered using the
CamelCase, the object Label as well as the Physical Name is
automatically generated.
For example, when creating an entity, if you type ProductPart in the
name, the label is automatically filled in with Product Part and the
physical name is set to PRODUCT_PART.
Duplicating Objects
The workbench support object duplication for Form Views, Tables Views, Search Forms, Business Objects, Business Object Views and Workflows.
To duplication an object:
-
Select the object to duplicate in the Model Edition tree view.
-
Right-click and then select Duplicate.
A copy of the object is created.
It is also possible to duplicate a group of objects. When duplicating a group of objects that reference one another, the references in the copied objects are moved to the copies of the original objects.
For example:
-
When copying a single business object view BOV1 that references a table view TV1, the copy of the business object View (BOV2) still references the table view TV1.
-
When copying a business object view BOV1 with a table view TV1 that it references (the group includes BOV1 and TV1), the copy of the business object view BOV2 references the copy of the table view BOV2.
To duplicate a group of objects:
-
Select the multiple objects to duplicate in in the Model Edition tree view. Press the CTRL key to enable multiple selection.
-
Right-click and then select Duplicate.
A copy of the group of object is created. The links are made if possible to the copied objects.
Working with Diagrams
Diagrams are used to design models and workflows.
The Model Diagram
The Model Diagram Editor shows a graphical representation of a portion
of the model or the entire model.
Using this diagram, you can create entities and references in a
graphical manner, and organize them as graphical shapes.
The diagram is organized in the following way:
-
The Diagram shows shapes representing entities and references.
-
The Toolbar allows you:
-
to zoom in and out in the diagram.
-
to select an automatic layout for the diagram and apply this layout by clicking the Auto Layout button.
-
to select the elements to show in the diagram (attributes, entities, labels or names, foreign attributes, etc)
-
-
The Palette provides a set of tools:
-
Select allows you to select, move and organize shapes in the diagram. This selection tool allows multiple selection (hold the Shift or CTRL keys).
-
Add Reference and Add Entity tools allow you to create objects.
-
Add Existing Entities allows you to create shapes for existing entities.
-
| After choosing a tool in the palette, the cursor changes. Click the Diagram to use the tool. Note that after using an Add… tool, the tool selection reverts to Select. |
For more information about the model diagrams, see the Diagrams section in the Logical Modeling chapter.
The Human Workflow Diagram
The human workflow diagram shows a graphical representation of the human
workflows.
Using this diagram, you can design tasks and transitions for a workflow.
The diagram is organized in the following way:
-
The Diagram shows shapes representing tasks (rectangles) and transitions (links), as well as the start and end events (round shapes).
-
The Toolbar allows you:
-
to zoom in and out in the diagram.
-
to select an automatic layout for the diagram and apply this layout by clicking the Auto Layout button.
-
to select the elements to show in the diagram (name/labels on the tasks and transitions).
-
to validate the workflow. The validation report shows the errors of the workflow.
-
-
The Palette provides a set of tools:
-
Select allows you to select, move and organize shapes in the diagram. This selection tool allows multiple selection (hold the Shift or CTRL keys).
-
Add Task and Add Transition tools allow you to modify the workflow.
-
-
The Properties view allows you to edit the properties of the task or transition selected in the diagram.
In this diagram, you can drag the transition arrows to change the source and target tasks of a transition.
For more information about the human workflow diagrams, see the Creating Human Workflows in the Working with Applications chapter.
Working with Other Views
Other views (for example: Progress, Validation Report) appear in certain perspectives. These views are perspective-dependent.
Workbench Preferences
User preferences are available to configure the workbench behavior. These preferences are stored in the repository and are specific to each user connecting to the workbench. The preferences are applied regardless of the client computer or browser used by the user to access the workbench.
Setting Preferences
Use the Window > Preferences dialog pages to set how you want the workbench to operate.
You can browse the Preferences dialog pages by looking through all the titles in the left pane or search a smaller set of titles by using the filter field at the top of the left pane. The results returned by the filter will match both Preference page titles and keywords such as general and stewardship.
The arrow controls in the upper-right of the right pane enable you to navigate through previously viewed pages. To return to a page after viewing several pages, click the drop-down arrow to display a list of your recently viewed preference pages.
The following preferences are available in the Preferences dialog:
-
Data Stewardship Preferences apply to the data stewardship applications:
-
Data Page Size: Size of a page displaying a list of records.
-
Show Hierarchy Navigation: Select this option to display the Hierarchical view of the records in the outline.
-
Show Lineage Navigation: Select this option to display the Lineage view of the records in the outline.
-
Predictable Navigation: Select to option to enable automated record sorting when opening a list of records. This option provides a predictable list of records for each access. This option is not recommended when accessing large data sets as sorting may be a time consuming operation.
-
List of Values Export Format: Format used when exporting attribute values with a list of values type.
-
List of Values Display Format: Format used when displaying attributes with a list of values type.
-
-
General Preferences:
-
Date Format: Format used to display the date values in the workbench. This format uses Java’s SimpleDataFormat patterns.
-
DateTime Format: Format used to display the date and time values in the workbench. This format uses Java’s SimpleDataFormat patterns.
-
Link Perspective to Active Editor: Select this option to automatically switch to the perspective related to an editor when selecting this editor.
-
Under the Data Stewardship preferences node, preference pages are listed for the data locations accessed by the user and for the entities under these data locations. These preference pages display no preferences and are used to reset the Filters, Sort and Columns selected by the user for the given entities, as well as the layout of the editors for these entities (the collapsed sections, for example). To reset the preferences on a preferences page, click the Restore Defaults button in this page.
Exporting and Importing User Preferences
Sharing preferences between users is performed using preferences import/export.
To export user preferences:
-
Select File > Export. The Export wizard opens.
-
Select Export Preferences in the Export Destination and then click Next.
-
Click the Download Preferences File link to download the preferences to your file system.
-
Click Finish to close the wizard.
To import user preferences:
-
Select File > Import. The Import wizard opens.
-
Select Import Preferences in the Import Source and then click Next.
-
Click the Open button to select an export file.
-
Click OK in the Import Preferences Dialog.
-
Click Finish to close the wizard.
Importing preferences replaces all the current user’s preferences by those stored in the preferences file.
Working with SemQL
| This section provides a quick introduction to the SemQL language. For a detailed description of this language with examples, refer to the Stambia MDM SemQL Reference Guide. |
SemQL is a language to express declarative rules in Stambia MDM Workbench. It is used in Enrichers, Matchers, Validations, Filters and Consolidators.
SemQL Language Characteristics
The SemQL Language has the following characteristics:
-
The syntax is close to the Oracle Database SQL language and most SemQL functions map to Oracle functions.
-
SemQL is not a query language: It does not support Joins, Sub-queries, Aggregation, in-line Views and Set Operators.
-
SemQL is converted on the fly and executed by the hub database.
-
SemQL uses Qualified Attribute Names instead of columns names. The code remains implementation-independent.
Qualified Attribute Names
A Qualified Attribute Name is the path to an attribute from the
current entity being processed.
This path not only allows accessing the attributes of the entity, but
also allows access to the attributes of the entities related to the
current entity.
Examples:
-
FirstName: Simple attribute of the current Employee entity. -
InputAddress.PostalCode: Definition Attribute (PostalCode ) of the InputAddress Complex Attribute used in the current Customer entity. -
CostCenter.CostCenterName: Current Employee entity references the CostCenter entity and this expression returns an employee’s cost center name -
CostCenter.ParentCostCenter.CostCenter: Same as above, but the name is the name of the cost center above in the hierarchy. Note that ParentCostCenter is the referenced role name in the reference definition. -
Record1.CustomerName: CustomerName of the first record being matched in a matcher process.Record1andRecord2are predefined qualifiers in the case of a matcher to represent the two records being matched.
SemQL Syntax
The SemQL Syntax is close to the Oracle Database SQL language for creating expressions , conditions and order by clauses.
-
Expressions contain functions and operators, and return a value of a given type.
-
Conditions are expression returning true or false. They support AND, OR, NOT, IN, IS NULL, LIKE, REGEXP_LIKE, Comparison operators (=, !=, >, >=, <, ⇐), etc.
-
Order By Clauses are used to sort records in a set of results using an arbitrary combination of Expressions sorted ascending or descending
In expressions, conditions and order by clauses, it is possible to use the SemQL functions. The list of SemQL functions is provided in the SemQL Editor
| SemQL is not a query language: SELECT, UPDATE or INSERT queries are not supported, as well as joins, sub-queries, aggregates, in-line views, set operators. |
SemQL Examples
Enricher Expressions
-
FirstName:
InitCap(FirstName) -
Name:
InitCap(FirstName) || Upper(FirstName) -
City:
Replace(Upper(InputAddress.City),'CEDEX','')
In these examples, InitCap, Upper and Replace are SemQL functions.
The concatenate operator || is also a SemQL operator.
Validation Conditions
-
Checking the Customer’s InputAddress complex attribute validity:
InputAddress.Address is not null and ( InputAddress.PostalCode is not null or InputAddress.City is not null)
In this example, the IS NOT NULL, AND and OR SemQL operators are
used to build the condition.
Matcher
-
Binning Expression to grouping customers by their Country/PostalCode:
InputAddress.Country || InputAddress.PostalCode
-
Matching Condition: Matching two customer records by name, address and city name similarity:
SEM_EDIT_DISTANCE_SIMILARITY( Record1.CustomerName, Record2.CustomerName ) > 65 and SEM_EDIT_DISTANCE_SIMILARITY( Record1.InputAddress.Address, Record2.InputAddress.Address ) > 65 and SEM_EDIT_DISTANCE_SIMILARITY( Record1.InputAddress.City, Record2.InputAddress.City ) > 65
In this last example, SEM_EDIT_DISTANCE_SIMILARITY is a SemQL
function. Record1 and Record2 are predefined names for qualifying
the two record to match.
The SemQL Editor
The SemQL editor can be called from the workbench when a SemQL expression, condition or clause needs to be built.

This editor is organized as follows:
-
Attributes available for the expression appear in left panel. Double-click an attribute to add it to the expression.
-
Functions declared in SemQL appear in the left bottom panel, grouped in function groups. Double-click a function to add it to the expression. You can declare your own PL/SQL functions in the model so that they appear in the list of functions.
-
Messages appear in the right bottom panel, showing parsing errors and warnings.
-
Description for the selected function or attribute appear at the bottom of the editor.
-
The Toolbar allows to indent the code or hide/display the various panels of the editor and to undo/redo code edits.
Declaring PL/SQL Functions for SemQL
You can use in SemQL customized functions implemented using PL/SQL.
You must declare these functions in the model to have them appear in the list of functions.
| Functions that are not declared can still be used in SemQL, but will not be recognized by the SemQL parser and will cause validation warnings. |
To declare a PL/SQL function:
-
Right-click the PL/SQL Functions node in the Model Edition view and select Add PL/SQL Function. The Create New PL/SQL Function wizard opens.
-
In the Create New PL/SQL Function wizard, enter the following values:
-
Name: Name of the PL/SQL function. This name must exactly match the name of the function in Oracle. Note that if this function is part of a package, the function name must be prefixed by the package name.
-
Schema: The Oracle schema containing this function/package.
-
Categories: Enter or select the function categories of the SemQL Editor into which this function should appear.
-
-
Click Finish to close the wizard. The PL/SQL Function editor opens.
-
In the Description field, enter a detailed description for the function.
-
Click the Add Argument button in the Function Arguments section to declare an argument for the function.
The new argument is added to the Function Arguments table.-
Edit the Name of this argument in the Function Arguments table.
-
Select whether this argument is Mandatory and whether it is an Array of values.
-
-
Repeat the previous step to declare all the arguments.
-
Use the Move Up and Move Down buttons to order the argument according to your function implementation.
-
Press CTRL+S to save the editor.
-
Close the editor.
| Only declare the Schema if the function is available in this given schema in all the environments (development, test, productions) into which the model will be deployed. If it is not the case, it is recommended not to use a schema name and to create Oracle synonyms to make your function available in all environments from the data location schema. |
| A Mandatory argument cannot follow a non-mandatory one. An Array argument must always the last argument in the list. |
Working with Plug-ins
Plug-ins allow extending the capabilities of the Stambia MDM using Java code and external APIs.
Plug-ins are used to implement enrichers or validations not feasible in
SemQL.
The plug-ins have the following characteristics:
-
All plug-ins take Inputs (mapped on attributes) and Parameters, which may be mandatory (or not).
-
Enricher Plug-ins return Outputs (mapped on attributes to enrich). A subset of these outputs may be used for enriching attributes.
-
Validation Plug-ins return a Boolean value indicating whether or not the values of the input are valid.
Examples of plug-ins:
-
Enricher: Geocoding using an external API (Google, Yahoo, etc.)
-
Validation: Pattern Matching, Validating against an external API, etc.
More information:
-
For more information on using Plug-ins, refer to the Logical Modeling and Integration Process Design chapters.
-
For more information on developing Plug-ins, refer to the Stambia MDM Plug-in Developer’s Guide.
Logical Modeling
Logical modeling allows defining the business entities that make up the model.
Introduction to Logical Modeling
In Stambia MDM, modeling is performed at the logical level. You do not design physical objects such as tables in a model, but logical business entities independently from their implementation.
Logical Model Objects
Logical modeling includes creating the following objects:
-
Customized types such as User-Defined Types, Complex Types and List of Values reused across the model.
-
Entities representing the business objects with their Attributes.
-
References Relationships linking the entities of the model, for example to build hierarchies.
-
Constraints such as Validations, Unique Keys and Mandatory attributes.
-
Display Names, Table Views, Table Views and Business Objects defining how the entities appear to the data stewards and end-users.
In the modeling phase, integration processes objects such as Enrichers, Matchers and Consolidators are also created. Creating these objects is described in the Integration Process Design chapter. After completing the modeling phase, you can create Applications to access the data stored in your model.
Objects Naming Convention
When designing a logical model, it is necessary to enforce a naming
convention to guarantee a good readability of the model and a clean
implementation.
There are several names and labels used in the objects in Stambia MDM:
-
Internal Names (Also called Names) are used mainly by the Model designers and are unique in the model. They can only contain alphanumeric characters, underscores and must start with a letter.
-
Physical Names and Prefixes are used to create the objects in the database corresponding to the logical object. These can only contain uppercase characters and underscores.
-
Labels and Descriptions are visible to the users (end-users and data stewards) consuming data through the UI. These user-friendly labels and descriptions can be fixed at later stages in the design. They are externalized and can be localized (translated) in the platform.
The following tips should be used for naming objects:
-
Use meaningful Internal Names. For example, reference relationships should all be named after the pattern
<entity name><relation verb><entity name>, like CustomerHasAccountManager . -
Do not try to shorten internal names excessively. They may become meaningless. For example, using CustAccMgr instead of CustomerHasAccountManager is not advised .
-
Use the CamelCase for internal names as it enables the use of the Auto fill feature. For example, ContactBelongsToCustomer, GeocodedAddressType.
-
Define team naming conventions that accelerate object type identification. For example, types and list of values can be post-fixed with their type such as GeocodedAddressType, GenderLOV.
-
Define user-friendly Labels and Descriptions. Internal Names are for the model designers, but labels and descriptions are for end users.
Model Validation
A model may be valid or invalid. An invalid model is a model that contains a number of design errors. When a model is invalid, you cannot deploy it, and you cannot close this model edition. Model validation detects errors or missing elements in the model.
To validate the model:
-
In the Model Edition view of the Model Design Perspective, select the model node at the root of the tree. You can alternately select on entity to validate only this entity.
-
Right-click and select Validate.
-
The validation process starts. At the end of the process, the list of issues (errors and warnings) is displayed in the Validation Report view. You can click an error or waning to open the object causing this issue.
| It is recommended to regularly run the validation on the model or on specific entities. Validation may guide you in the process of designing a model. You can perform regular validations to assess how complete the model really is, and you need to pass model validation before deploying or closing a model edition. |
Generating the Model Documentation
When a model is complete or under development, it is possible to generate a documentation set for this model.
This documentation set may contain the following documents:
-
The Logical Model Documentation, which includes a description of the logical model and the rules involved in the integration processes.
-
The Applications Documentation, which includes a description of the applications of the model, their related components (views, business objects, etc.) as well as their workflows.
-
The Physical Model Documentation, which includes a description of the physical tables generated in the data location when the model is deployed. This document is a physical model reference document for the integration developers.
The documentation is generated in HTML format and supports hyperlink navigation within and between documents.
To generate the model documentation:
-
In the Model Edition view of the Model Design Perspective, select the model node at the root of the tree.
-
Right-click and select Export Model Documentation.
-
In the Model Documentation Export dialog, select the documents to generate.
-
Select the appropriate Encoding and Locale for the exported documentation. The local defines the language of the generated documentation.
-
Click OK to download the documentation.
The documentation is exported in a zip file containing the selected documents.
| It is possible to export the model documentation only for a valid model. |
Types
Several types can be used in the Stambia MDM models:
-
Built-in Types are part of the platform. For example: string, integer, etc.
-
List of Values (LOVs) are a user-defined list of string codes and labels. For example: Gender (M:Male, F:Female), VendorStatus (OK:Active, KO:Inactive, HO:Hold).
-
User Defined Types are user restriction on a built-in type. For example the GenericNameType type can be defined as a String(80) and the ZipCodeType can be used as an alias for Decimal (5,0).
-
Complex Types are a customized composite type made of several Definition Attributes using Built-in Type, User-Defined Type or a List of Values. For example, an Address complex type has the following definition attributes: Street Number, Street Name, Zip Code, City Name and Country.
All these type as the user-defined are reused across the entire model.
| A list of values, user-defined or complex type is designed in the model and can be used across the entire model. Changes performed to such a type impact the entities and attributes using this type. To list the attributes using a type and analyze the impact of changing a type, open the editor for this type and then select the Used in item in the left sidebar. |
Built-in Types
Built-in types are provided out of the box in the platform.
Built-in types include:
-
Numeric Types:
-
ByteInteger: 8 bytes signed. Range [–128 to 127]
-
ShortInteger: 16 bytes signed. Range [–32,768 to –32,767]
-
Integer: 32 bytes signed. Range [–2^32 to (2^32-1)]
-
LongInteger: 64 bytes signed. Range [–2^64 to (2^64-1)]
-
Decimal: Number(Precision,Scale), where Precision in [1-38] and Scale in [–84-127]
-
-
Text Types:
-
String: Length smaller than 4000 characters.
-
LongText: No size limit – Translated to a CLOB in the database
-
-
Date Types:
-
Datetime: Date and Time (to the Second)
-
Timestamp: Date and Time (to fractional digits of a Second)
-
-
Binary Types:
-
Binary: Store any type of binary content (image, document, movie, etc.) with no size limit – Translated to a BLOB in the database
-
-
Misc. Types:
-
UUID: 16 bytes Global Unique ID
-
Boolean: 1 character containing either `1' (true) or `0' (false).
-
List of Values
List of Values (LOVs) are a user-defined list of code and label pairs.
They are limited to 1,000 entries and can be imported from a Microsoft
Excel Spreadsheet.
Examples:
-
Gender (M:Male, F:Female)
-
VendorStatus (OK:Active, KO:Inactive, HO:Hold)
| Lists of values are limited to 1,000 entries. If a list of value needs to contain more than 1,000 entries, you should consider implementing in the form of an entity instead. |
To create a list of values:
-
Right-click the List of Values node and select Add List of Values…. The Create New List of Values wizard opens.
-
In the Create New List of Values wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the list of values.
-
Label: User-friendly label in this field. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
Length: Length of the code for the LOV.
-
-
Click Finish to close the wizard. The List of Values editor opens.
-
In the Description field, optionally enter a description for the user-defined type.
-
Add values to the list using the following process:
-
In the Values section, click the Add Value button. The Create New LOV Value dialog appears.
-
In this dialog, enter the following values:
-
Code: Code of the LOV value. This code is the value stored in an entity attribute.
-
Label: User-friendly label displayed for a field having this value.
-
Description: Long description of this value.
-
-
Click Finish to close the dialog.
-
-
Repeat the previous operations to add the values. You can select a line in the list of value and click the Delete button to delete this line. Multiple line selection is also possible.
-
Press CTRL+S to save the editor.
-
Close the editor.
List of values can be entered manually as described above and can be translated.
In addition, you can also import values or translated values from a
Microsoft Excel Spreadsheet.
This spreadsheet must contain only one sheet with three columns
containing the Code, Label and Description values. Note that the first
line of the spreadsheet will be ignored in the import process.
To import a list of values from an excel spreadsheet:
-
Open the editor for the list of value.
-
Expand the Values section.
-
In the Values section, click the Import Values button. The Import LOV Values wizard appears.
-
Use the Open button to select a Microsoft Excel spreadsheet.
-
Choose the type of import:
-
Select Import codes, default labels and descriptions to simply import a list of codes, default labels and descriptions.
-
Select Import translated labels and description for the following locale then select a locale from the list to import translated labels and descriptions in a given language. Click the Merge option to only update existing and insert new translations. If you uncheck this box, the entire translation is replaced with the content of the Excel file. Entries not existing in the spreadsheet are removed.
-
-
Click Next . The changes to perform are computed and a report of object changes is displayed.
-
Click Finish to perform the import. The Import LOV wizard closes.
-
Press CTRL+S to save the editor.
-
Close the editor.
User-Defined Types
User-Defined Types (UDTs) are user restriction on a built-in type. They can be used as an alias to a built-in type, restricted to a given length/precision.
Examples:
-
GenericNameType type can be defined as a String(80)
-
ZipCodeType can be used as an alias for Decimal(5,0).
To create a user-defined type:
-
Right-click the User-defined Types node and select Add User-defined Type…. The Create New User-defined Type wizard opens.
-
In the Create New User-defined Type wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the user-defined type
-
Label: User-friendly label in this field. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
Built-in Type: Select a type from the list.
-
Length, Precision, Scale. Size for this user defined type. The fields available depend on the built-in type selected. For example a String built-in type will only allow entering a Length.
-
-
Click Finish to close the wizard. The User-defined Type editor opens.
-
In the Description field, optionally enter a description for the user define type.
-
Press CTRL+S to save the editor.
-
Close the editor.
Complex Types
Complex Types are a customized composite type made of several Definition Attributes using Built-in Type, User-Defined Type or a List of Values.
For example, an Address complex type has the following definition attributes: Street Number, Street Name, Zip Code, City Name and Country.
To create a complex type:
-
Right-click the Complex Types node and select Add Complex Type…. The Create New Complex Type wizard opens.
-
In the Create New Complex Type wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
-
Click Finish to close the wizard. The Complex Type editor opens.
-
In the Description field, optionally enter a description for the complex type.
-
Select the Definition Attributes item in the editor sidebar.
-
Repeat the following steps to add definition attributes to this complex type:
-
Select the Add Definition Attribute… button. The Create New Definition Attribute wizard opens.
-
In the Create New Definition Attribute wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
Physical Column Name: Name of the physical column containing the values for this attribute. This column name is prefixed with the value of the Physical Prefix specified on the entity complex attribute of this complex type.
-
Type: List of values, built-in or user-defined type of this complex attribute.
-
Length, Precision, Scale. Size for this definition attribute. The fields available depend on the built-in type selected. For example a String built-in type will only allow entering a Length. If a list of values or a user-defined type was selected, these values cannot be changed.
-
Mandatory: Check this box to make this definition attribute mandatory when the complex type is checked for mandatory values.
-
-
Click Finish to close the wizard. The new definition attribute appears in the list. You can double-click the attribute in the list to edit it further and edit its advanced properties (see below).
-
-
Press CTRL+S to save the Complex Type editor.
-
Close the editor.
A complex type has the following advanced properties that impact its behavior:
-
Mandatory: When an entity attribute is checked for mandatory values, and this attribute uses a complex type, each of the definition attributes of this complex type with the mandatory option selected are checked.
-
Searchable: This option defines whether this attribute is used for searching.
-
Translated: Options reserved for a future use.
-
Multi-Valued: This option applies to definition attributes having the type list of values. Checking this box allows the definition attribute to receive several codes in the list of values, separated by the Value Separator provided. For example, a multi-valued Diplomas field can receive the DM, DP, DPM codes meaning that that contact is Doctor of Medicine, Pharmacy and Preventive Medicine.
Entities
Entities are the key components of the logical modeling. They are not database tables, but they represent Business Entities of the domain being implemented in the MDM Project. Example of entities: Customers, Contacts, Parties, etc.
Entity Characteristics
Entities have several key characteristics. They are made of Attributes, have a Matching Behavior and References. They also support Inheritance.
Attributes
Entities have a set of properties, called Attributes. These attributes can be either:
-
Simple Attributes using a built-in types, user-defined types or a list of values created in the model.
-
Complex Attributes using complex types created in the model.
For example, the Contact entity may have the following attributes:
-
FirstName and LastName: Simple attributes using the user-defined type called GenericNameType
-
Comments: Simple attribute using the built-in type LongText.
-
Gender: Simple attributes based on the GenderLov list of values.
-
Address: Complex Attribute using the GeocodedAddress complex type.
Matching Behavior
Each entity has a given a matching behavior. This matching behavior expresses how similar instances (duplicates) of this entity are detected:
-
ID Matching (formerly known as UDPK): Records in entities using ID Matching are matched if they have the same ID. This matching behavior is well suited when there is a true unique identifier for all the applications communicating with the MDM hub and for simple Data Entry use cases.
-
Fuzzy Matching (formerly known as SDPK): Records in entities using Fuzzy Matching are matched using a set of matching rules defined in a Matcher.
| The choice of a Matching Behavior is important. Please take into account the following differentiators when creating an entity. |
ID Matching
-
ID Matching means that all applications in the enterprise share a common ID. It may be a Customer ID, an SSID, etc.. This ID can be used as the unique identifier for the golden records.
-
This ID is stored into a single attribute which will be the golden data Primary Key. If the ID in the information system is composed of several columns, you must concatenate these values into the PK column.
-
As this ID is common to all systems, matching is always be made using this ID.
-
A Matcher can be defined for the entity, for detecting potential duplicates when manually creating records in the hub via a data entry workflow.
Use ID Matching only when there is a true unique identifier for all the applications communicating with the MDM Hub, or for simple data entry use cases.
Fuzzy Matchings
-
Fuzzy Matching means that applications in the enterprise have different IDs, and Stambia MDM needs to generate a unique identifier (Primary Key - PK) for the golden records. This PK can be either a sequence or a Unique ID (UUID).
-
Similar records may exist in the various systems, representing the same master data. These similar records must be matched using fuzzy matching methods that compare their content.
-
A Matcher must be defined in such entity to describe how source records are matched as similar records to be consolidated into golden records.
Use Fuzzy Matching only when you do not have a shared identifier for all systems, or when you want to perform fuzzy matching and consolidation on the source data.
ID Generation
The matching behavior impacts the method used for generating the values
for the Golden Record Primary Key:
-
ID Matching Entities: The Golden Record Primary Key is also the ID that exists in the source systems. It may be generated in the MDM hub only when creating new records in data entry workflows. In this case, the ID may be generated either manually (the user enters it in the form), or automatically using a Sequence or a Universally Unique Identifier generator.
-
Fuzzy Matching Entities: The Golden Record Primary Key is managed and always generated by the system, using a Sequence or a Universally Unique Identifier generator. When creating records in data entry workflows, a Source ID is automatically generated and can be manually modified by the user.
| When generating IDs automatically using a Sequence in data entry forms for an ID Matching entity, you must take into account records pushed by other publishers (using for example a data integration tool). These publishers may use the same IDs for the same entity, and in this case the records will match by ID. If you want to separate records entered manually from other publishers’ records and avoid unexpected matching, configure your sequence using the Start With option to start beyond the range of IDs used by the other publishers. |
References
Entities are related using Reference Relationships. A reference relationship defines a relation between two entities. For example, an Employee is related to a CostCenter by a EmployeeHasCostCenter relation.
Constraints
Data quality rules are created in the design of an entity. These constraints include:
-
Mandatory columns
-
List of Values range check
-
Unique Key
-
Record level Validations.
-
Reference Relationships
These constraints are checked on the source records and the consolidated records as part of the integration process. They can also be checked to enforce data quality in data entry workflows .
Inheritance
Entities can extend other entities (Inheritance). An entity (child) can
be based on another entity (parent).
For example, the PersonParty and OrganizationParty entities inherit
from the Party entity.
They share all the attributes of their parent but have specificities.
When inheritance is used:
-
The child entity inherits the following elements: Attributes, Unique Keys, Validations, Enrichers, References and Display Name.
-
Matchers and Consolidators are not inherited
-
It is not possible to modify the matching behavior. The child inherits from the parent’s behavior.
-
It is possible to add elements to the child entity: Attributes, Unique Keys, Validations, Enrichers and References.
-
The display name defined for the parent entity can be amended in a child entity by appending additional attributes from the child. The separator can be changed.
When using inheritance, the underlying physical tables generated for the child entities and parent entity are the same. They contain a superset of all the attributes in the cluster of entities.
Display Options
Entities also have display options, including:
-
A Display Name defining how the entity is display in compact format.
-
Translations to display the entities information in a client’s locale.
Integration Rules
In addition to the display characteristics, an entity is designed with integration rules describing how master data is created and certified from the source data published by the source applications.
These characteristics are detailed in the Integration Process Design chapter.
Creating an Entity
Creating a New Entity
To create an entity:
-
Right-click the Entities node and select Add Entity…. The Create New Entity wizard opens.
-
In the Create New Entity wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
Plural Label: User-friendly label for this entity when referring to several instances. The value for the plural label is automatically generated from the Label value and can be optionally modified.
-
Extends Entity: Select an entity that you want to extend in the context of Inheritance. Leave this field to an empty value if this entity does not extend an existing one.
-
If the entity extends an existing one, the remaining options cannot be changed as they are inherited. Click Finish to close the wizard and then press CTRL+S to save the editor.
-
If you do not use inheritance, proceed to the next step.
-
-
Physical Table Name: This name is used to name the physical table that will be created to store information about this entity. For example, if the physical table is CUSTOMER, then the golden data is stored in a GD_CUSTOMER table.
-
Matching Behavior: Select the matching behavior for this entity. ID Matching or Fuzzy Matching. See Matching Behavior for more information.
-
-
Click the Next button.
-
In the Primary Key Attribute screen, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the primary key attribute.
-
Label: User-friendly label for this primary key attribute.
-
Physical Column Name: This name is used to name the physical column that will be created to store values for this attribute.
-
ID Generation: Select the method for generating the primary key:
-
Sequence: Use this option to generate the ID as a sequential number. You can specify a startup value for the sequence in the Starts With field.
-
UUID: Use this option to generate the ID as a Universally Unique Identifier.
-
Manual: Use this option to type in the ID manually. This option is only possible for ID Matching entities. When this option is selected, you can choose the Type and Length for the primary key attribute.
-
-
-
Click Finish to close the wizard. The Entity editor opens.
-
In the Description field, optionally enter a description for this entity.
-
Press CTRL+S to save the editor.
When an entity is created, it contains no attributes. Simple Attributes and Complex Attributes can be added to the entity now.
| You cannot modify the entity matching behavior, primary key or inheritance from the Entity editor. To change such key properties of the entity after creating it, you must use the Alter Entity option. See Altering an Entity for more information. |
Adding a Simple Attribute
To add a simple attribute:
-
Expand the entity node, right-click the Attributes node and select Add Simple Attribute…. The Create New Simple Attribute wizard opens.
-
In the Create New Simple Attribute wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
Physical Column Name: This name is used to name the physical column that will be created to store values for this attribute.
-
Type: Select the type of the attribute. This type can be a built-in type, a user-defined type or a list of values.
-
Length, Precision, Scale. Size for this definition attribute. The fields available depend on the built-in type selected. For example a String built-in type will only allow entering a Length. If a list of values or a user-defined type was selected, these values cannot be changed.
-
Mandatory: Check this box to make this attribute mandatory.
-
Mandatory Validation Scope: This option is available if the Mandatory option was selected. Select whether this attribute should be checked for null values pre and/or post consolidation. For more information, refer to the Integration Process Design chapter.
-
LOV Validation Scope: This option is available if the selected type is a list of values. It defines whether the attribute’s value should be checked against the codes listed in the LOV. For more information, refer to the Integration Process Design chapter.
-
-
Click Finish to close the wizard. The Simple Attribute editor opens.
-
In the Description field, optionally enter a description for the simple attribute.
-
Press CTRL+S to save the editor.
Adding a Complex Attribute
To add a complex attribute:
-
Expand the entity node, right-click the Attributes node and select Add Complex Attribute…. The Create New Complex Attribute wizard opens.
-
In the Create New Complex Attribute wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
Physical Prefix: This name is used to prefix the physical column that will be created to store values for this complex attribute. The column name is
<Physical Prefix>_<Definition Attribute Physical Column Name> -
Complex Type: Select the complex type of the attribute.
-
Mandatory Validation Scope: This option is available if the Mandatory option was selected for at least one of the definition attributes of the selected complex type. Select whether the mandatory definition attributes of the complex type should be checked for null values pre and/or post consolidation. For more information, refer to the Integration Process Design chapter.
-
LOV Validation Scope: This option is available if at least one of the definition attributes of the complex type is a list of values. It defines whether the definition attribute’s value should be checked against the codes listed in the LOV. For more information, refer to the Integration Process Design chapter.
-
-
Click Finish to close the wizard. The Complex Attribute editor opens.
-
In the Description field, optionally enter a description for the complex attribute.
-
Press CTRL+S to save the editor.
Working with Attributes
It is possible to edit, order or delete attributes in an entity from the Attributes list in the entity editor.
To order the attributes in an entity:
-
Open the editor for the entity.
-
Select the Attributes item in the sidebar.
-
Select an attribute in the Attributes list and use the Move Up and Move Down buttons to order this attribute in the list.
| With entities inheriting attributes from a parent in the context of Inheritance and have additional (not inherited) attributes, you can perform this ordering from the Inherited Attributes (All) section. Note that it is not possible to order additional attributes before the inherited attributes. |
To delete attributes from an entity:
-
Open the editor for the entity.
-
Select the Attributes item in the sidebar.
-
Use the Delete buttons to remove the attribute from the list.
-
Click OK in the confirmation dialog.
| With entities inheriting attributes from a parent in the context of Inheritance and have additional (not inherited) attributes, you can delete attributes from the Inherited Attributes (All) section. |
| Deleting an inherited attribute on a child entity removes it from the parent entity, and by extension from all the child entities inheriting this attribute from the parent. |
Altering an Entity
Altering an entity allows modifying the key properties of an entity, including its matching behavior, inheritance and primary key attribute.
To alter an entity:
-
Select the entity node, right-click and select Alter Entity. The Modify Entity wizard opens.
-
In the wizard, modify the properties of the entity using the same process used for Creating a New Entity
Reference Relationships
Reference Relationships functionally relate two existing entities. One
of them is the referenced, and one is referencing.
For example:
-
In an EmployeeHasCostCenter reference, the referenced entity is CostCenter, the referencing entity is Employee.
-
In a CostCenterHasParentCostCenter reference, the referenced entity is CostCenter, the referencing entity is also CostCenter. This is a self-reference.
They are used for:
-
Displaying Hierarchies: For example, a hierarchy of cost centers is built as CostCenter has a self-reference called CostCenterHasParentCostCenter.
-
Displaying Lists of Child Entities to navigate the list of entities referring a master entity. For example, a CostCenter can appear with a list of Employee belonging to this cost center according to the EmployeeHasCostCenter relation.
-
Display Links to navigate to the parent entity in a similar relation. The Employee entity will list a link to the CostCenter he belongs to.
-
Referential Integrity. It is enforced as part of the golden data certification process. References are also constraints on entities.
A reference is expressed in the model in the form of a foreign attribute that is added to the referencing attribute.
To create a reference relationship:
-
Right-click the Reference Relationships node in the model and select Add Reference…. The Create New Reference Relationship wizard opens.
-
In the Create New Reference Relationship wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Physical Name:Name of the database indexes created for optimizing access via this reference.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
Validation Scope: Select whether the referential integrity should be checked pre and/or post consolidation. For more information, refer to the Integration Process Design chapter.
-
-
In the Referencing [0..*] group, enter the following values:
-
Referencing Entity: Select the entity which references the referenced (parent) entity. For example, in an EmployeeHasCostCenter relation, it is the Employee entity.
-
Referencing Role Name: Name used to refer to this entity from the referenced entity. For example, in an EmployeeHasCostCenter relation, it is the Employees.
-
Referencing Role Label: User-friendly label to refer to one record of this entity from the referenced entity. For example, in an EmployeeHasCostCenter relation, it is the Reporting Employee .
-
Referencing Role Plural Label: User-friendly label to refer to a list of records of this entity from the referenced entity. For example, in an EmployeeHasCostCenter relation, it is the Reporting Employees (plural) .
-
Referencing Navigable: Check this box to display the navigation items to this entity from the parent entity. For example, in an EmployeeHasCostCenter relation, selecting this option will make visible the Reporting Employees node under each CostCenter in the outline, and a list of Reporting Employees in the CostCenter master/detail page.
-
-
In the Referenced [0..1] group, enter the following values:
-
Referenced Entity: Select the entity which is referenced. For example, in an EmployeeHasCostCenter relation, it is the CostCenter entity.
-
Referenced Role Name: Name used to refer to this entity from the referencing entity. For example, in an EmployeeHasCostCenter relation, it is the CostCenter . This name is also the name given to the foreign attribute added to the referencing entity to express this relation.
-
Referenced Role Label: User-friendly label to refer to this entity from the referencing entity. For example, in an EmployeeHasCostCenter relation, it is the Cost Center.
-
Referenced Navigable: Check this box to display the navigation items to this entity from a child entity. For example, in an EmployeeHasCostCenter relation, selecting this option will make visible the link to open a parent CostCenter from an Employee page. Note that this link will show the Display Name defined for the CostCenter entity.
-
Mandatory: Define whether the reference to this entity is mandatory for the child. For example, in an EmployeeHasCostCenter relation, this option must be checked as an employee always belong to a cost center. For a CostCenterHasParentCostCenter reference, the option should not be checked as some cost centers may be at the root of my organization chart.
-
Physical Name: Name of the physical column created for the foreign attribute in the tables representing the referencing entity.
-
-
Click Finish to close the wizard. The Reference Relationship editor opens.
-
In the Description field, optionally enter a description for the Reference Relationship.
-
Press CTRL+S to save the editor.
-
Close the editor.
Data Quality Constraints
Data Quality Constraints include all the rules in the model that enforce a certain level of quality on the entities. These rules include:
-
Mandatory Attributes: An attribute must not have a null value. For example, the Phone attribute in the Customer entity must not be null.
-
References (Mandatory References): An entity with a non-mandatory reference must have a valid referenced entity or a null reference (no referenced entity). For mandatory references, the entity must have a valid reference and does not allow null references.
-
LOV Validation: An attribute with an LOV type must have all its values defined in the LOV. For example, the Gender attribute of the Customer entity is a LOV of type GenderLOV. It must have its values in the following range: [M:Male, F:Female].
-
Unique Keys: A group of column that has a unique value. For example, for a Product entity, the pair ProductFamilyName, ProductName must be unique.
-
Validations: A formula that must be valid on a given record. For example, a Customer entity must have either a valid Email or a valid Address.
The Mandatory Attributes and LOV Validations are designed when creating
the Entities. The references are defined when creating
Reference Relationships.
In this section, the Unique Keys and Validations are described.
Refer to the previous sections of the chapter for the other constraints.
More information:
-
Refer to the Integration Process Design chapter for more information about checking these constraints in the integration process.
-
Refer to the Creating Human Workflows section for more information about enforcing these constraints in the workflows.
Unique Keys
A Unique Key defines a group of attributes should be unique for an entity.
-
Expand the entity node, right-click the Unique Keys node and select Add Unique Key…. The Create New Unique Key wizard opens.
-
In the Create New Unique Key wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
Validation Scope: Select whether the unique key should be checked pre and/or post consolidation. For more information, refer to the Integration Process Design chapter.
-
-
Click Next.
-
In the Key Attributes page, select the Available Attributes that you want to add and click the Add >> button to add them to the Key Attributes.
-
Use the Move Up and Move Down buttons to order the selected attributes.
-
Click Finish to close the wizard. The Unique Key editor opens.
-
In the Description field, optionally enter a description for the Unique Key.
-
Press CTRL+S to save the editor.
-
Close the editor.
| In the data certification processes unique keys are checked after the match and consolidation process, on the consolidated (merged) records. Possible unique key violations are not checked on the incoming (source records). |
| Unique keys can be checked in data entry workflows to verify whether records with the same key have been entered previously by a user. This option is available only for entities using ID Matching. Besides, source records submitted to the hub via external loads (not via workflows) are not taken into account in such check. A unicity check enforced in a workflow will behave similarly to the check performed in the data certification process only if the consolidation rule gives precedence to the data submitted by users via workflows over data submitted by applications via external loads, of if data is only submitted via workflows. |
Validations
A record-level validation validates the values of a given entity record against a rule. Several validations may exist on a single entity.
There are two types of validation:
-
SemQL Validations express the validation rule in the SemQL language. These validations are executed in the hub’s database.
-
Plug-in Validations use a Plug-in developed in Java. These validations are executed by Stambia MDM. Controls that cannot be done in within the database (for example that involve calling an external API) can be created using plug-in validations.
SemQL Validation
To create a SemQL validation:
-
Expand the entity node, right-click the Validations node and select Add SemQL Validation…. The Create New SemQL Validation wizard opens.
-
In the Create New SemQL Validation wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
Description: optionally enter a description for the SemQL Validation.
-
Condition: Enter the SemQL condition that must be true for a valid record. You can use the
 Edit Expression button to open the SemQL Editor .
Edit Expression button to open the SemQL Editor . -
Validation Scope: Select whether the SemQL Validation should be checked pre and/or post consolidation. For more information, refer to the Integration Process Design chapter.
-
-
Click Finish to close the wizard. The SemQL Validation editor opens.
-
Press CTRL+S to save the editor.
-
Close the editor.
Plug-in Validation
| Before using a plug-in validation, make sure the plug-in was added to the platform by the administrator. For more information, refer to the Stambia MDM Administration Guide. |
To create a plug-in validation:
-
Expand the entity node, right-click the Validations node and select Add Plug-in Validation…. The Create New Plug-in Validation wizard opens.
-
In the Create New Plug-in Validation wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
Plug-in ID: Select the plug-in from the list of plug-ins installed in the platform.
-
Validation Scope: Select whether the Validation should be checked pre and/or post consolidation. For more information, refer to the Integration Process Design chapter.
-
-
Click Finish to close the wizard. The Plug-in Validation editor opens. The Plug-in Params and Plug-in Inputs tables show the parameters and inputs for this plug-in.
-
You can optionally add parameters to the Plug-in Params list:
-
In the Plug-in Params table, click the Define Plug-in Parameters button.
-
In the Parameters dialog, select the Available Parameters that you want to add and click the Add >> button to add them to the Used Parameters.
-
Click Finish to close the dialog.
-
-
Set the values for the parameters:
-
Click the Value column in the Plug-in Params table in front a parameter. The cell becomes editable.
-
Enter the value of the parameter in the cell, and then press Enter.
-
Repeat the previous steps to set the value for the parameters.
-
-
You can optionally add inputs to the Plug-in Inputs list:
-
In the Plug-in Inputs table, click the Define Plug-in Inputs button.
-
In the Input Bindings dialog, select the Available Inputs that you want to add and click the Add >> button to add them to the Used Inputs.
-
Click Finish to close the dialog.
-
-
Set the values for the inputs:
-
Double-Click the Expression column in the Plug-in Inputs table in front an input. The SemQL editor opens.
-
Edit the SemQL expression using the attributes to feed the plug-in input and then click OK to close the SemQL Editor.
-
Repeat the previous steps to set an expression for the inputs.
-
-
Optionally, you can use Advanced Plug-in Configuration properties to optimize and configure the plug-in execution.
-
Press CTRL+S to save the editor.
-
Close the editor.
Diagrams
A Diagram is a graphical representation of a portion of the model or the
entire model.
Using the Diagram, not only you can make a model more readable, but you
can also create entities and references in a graphical manner, and
organize them as graphical shapes.
It is important to understand that a diagram only displays shapes which are graphical representations of the entities and references. These shapes are not the real entities and reference, but graphical artifacts in the diagram:
-
When you double click on a shape from the diagram, you access the actual entity or reference via the shape representing it.
-
It is possible to remove a shape from the diagram without deleting the entity or reference.
-
You can have multiple shapes representing the same entity in a diagram. This is typically done for readability reasons. All these shapes point to the same entity.
-
If you delete an entity or reference, the shapes representing it automatically disappear from the diagrams.
Creating Diagrams
To create a diagram:
-
Right-click the Diagrams node and select Add Diagram…. The Create New Diagram wizard opens.
-
In the Create New Diagram wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
In the Description field, optionally enter a description for the Diagram.
-
-
Click Finish to close the wizard. The Diagram editor opens.
Working with Entities and References
In this section, the creation/deletion of entities and references from the diagram is explained.
To create an entity using the diagram:
-
In the Palette, select Add Entity.
-
Click the diagram. The Create New Entity wizard opens.
Follow the entity creation process described in the Creating an Entity section.
The entity is created and a shape corresponding to this entity is added
to the diagram.
Note that you can also create, edit and delete attributes from the
diagram. Select an attribute or entity and use the context menu options.
To create a reference using the diagram:
-
In the Palette, select Add Reference.
-
Select the referencing entity in the diagram. Keep the mouse button pressed, and move the cursor to the referenced entity.
-
Release the mouse button. The Create New Reference wizard opens. It is pre-filled based on the two entities.
Follow the reference relationship process described in the Reference Relationships section.
The reference is created and a shape corresponding to this reference is added to the diagram.
To delete a reference or an entity from the diagram:
-
In the diagram, select the entity of reference that you want to delete.
-
Right-click and select Delete.
-
Click OK in the Confirm Delete dialog.
The reference or entity, as well as the shape in the diagram disappear.
| Deleting an entity or reference cannot be undone. |
Working with Shapes
In this section, the creation/deletion of shapes in the diagram without changing the real entity or reference is explained.
To add existing entities to the diagram:
-
In the Palette, select Add Existing Entity.
-
Click the diagram. The Selection Needed dialog opens showing the list of entities in the diagram.
-
Select the entities to add to the diagram.
-
Click OK. The shapes for the selected entities are added to the diagram.
You can repeat this operation if you want to add multiple shapes for an entity in the diagram.
To add existing references to the diagram:
It is not possible to manually create a shape for reference in a
diagram.
When an entity is added to the diagram, shapes for the references
relating this entity to entities already in the diagram are
automatically added.
To remove a shape from the diagram:
-
In the diagram, select the shape representing the entity of reference that you want to delete.
-
Right-click and select Remove Shape.
The shape disappears from the diagram. The entity or reference is not deleted.
Database Reverse-Engineering
Reverse-engineering can be used to quickly populate a model from table
structures stored in a schema.
During this process, entities are created with attributes named after
the column names.
| This process connects to a database schema using a JDBC datasource that must be previously configured on the application server for the Stambia MDM application. Please contact the application server administrator for declaring this datasource. |
| Reverse-engineering is provided as a one-shot method to quickly populate the initial model from a database schema. The entities created using a reverse-engineering are by default fuzzy matching entities. Foreign keys existing between the tables in the schema are not reverse-engineered as references in the model. Besides, the reverse-engineering process is not incremental. |
To perform a database reverse-engineering:
-
Select the Entities node in the model.
-
Right-click and select Database Reverse-Engineering. The Reverse-Engineer Tables to Entities appears.
-
Select the Datasource to Reverse-Engineer from the list.
-
Click Next . The list of tables and columns is reverse-engineered. At issue, an Entity Preview page shows the list of tables and columns and the suggested logical names for these.
-
The Logical Name column correspond to the internal names of the entities and attributes generated by the reverse-engineering process.
-
The Physical Name columns is filled in with the physical name of the table and column in the database
-
-
Select only those of the entities and attributes that you want to reverse-engineer.
-
Modify the logical and physical names in this page.
-
Press Finish . The entities and attributes are created according to your definition.
| The entities created via a reverse-engineering process are provided as is. It is recommended to review their definition, particularly the Matching Behavior . |
Model Variables
Model variables store values retrieved from remote servers (declared as Variable Value Providers). Variable values are local to each user session, and are refreshed when the user accesses Stambia MDM. Model variables can be used in SemQL filters and expressions created at design and run-time to adapt the experience to the connected user.
For more information about Variable Value Providers, see the Configuring Variable Value Providers section in the Stambia MDM Administration Guide.
Creating Model Variables
| Before creating model variables, make sure that the variable value providers from which you want to retrieve information are declared for your Stambia MDM instance. |
To create a model variable:
-
Right-click the Model Variables node and select Add Model Variable…. The Create New Model Variable wizard opens.
-
In the Create New Model Variable wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Variable Type: select the data type of the variable: boolean, number or string.
-
Variable Value Provider: select the variable value provider that will be queried to retrieve the values for this variable.
-
-
Click Next.
-
Select the
Edit Expression button. -
In the Variable Lookup Query dialog, enter the query to retrieve the variable value:
-
For a Datasource Variable Value Provider, enter a SQL Query. You can use the
:V_USERNAME(connected user name) as a bind variable in this query. -
For an LDAP Variable Value Provider, enter the parameters of the LDAP search:
-
Base DN: The name of the base object entry (or possibly the root) relative to which the search is to be performed. For example:
dc=myCompany. -
Filter: Criteria to use for selecting elements within the scope. For more information about LDAP filters, see LDAP Search Filter Syntax.
-
Attribute: The attribute from the returned result to set in the variable value.
-
Search Scope: The depth of the search. Possible search scope values are Base Object (search just the object specified in the Base DN), Single Level (search entries immediately below the base DN), or Whole Subtree (the entire sub-tree starting at the base DN).
-
-
-
Click Finish to close the wizard. The Model Variable editor opens.
-
Press CTRL+S to save the editor.
-
Close the editor.
Variable Lookup Queries
The variable lookup query defined in a model variable retrieves
information from a variable value provider. This information can be made
specific to the connected user using the V_USERNAME variable.
The built-in variable called V_USERNAME stores the connected user
name, and can be referred to in the variable lookup queries using the
following syntax:
-
:V_USERNAMEin SQL queries. For example,SELECT COUNTRY FROM USERINFO WHERE USER=:V_USERNAMEretrieves the COUNTRY for the connected user name (variable binding using the:V_USERNAMEsyntax) from a USERINFO table. -
{V_USERNAME}in LDAP Filters. For example, the filter(&(objectClass=person)(cn={V_USERNAME}))will select persons (elements of the objectClass person) for which the common name ( cn) contains the currently connected user name (variable binding using the{V_USERNAME}syntax).
| Lookup queries should return a single value (column) and a single result (record). If the query returns multiple results or multiple values, only the first value of the first result is taken into account and set in the variable value. |
| It is not possible to use a variable in the lookup query of another variable. |
Testing Model Variables
After creating a new model variable, it is recommended to test it.
To test a model variable:
-
In the Model Edition view, double-click the model variable. The Model Variable editor for this variable opens.
-
In the editor toolbar, click the
 Retrieve Current Value button.
Retrieve Current Value button. -
The variable value refreshed for the current session appears in the Current Value field of the editor. If the variable cannot be refreshed, an error is issued.
Using Model Variables
Model Variable can be used in the following SemQL expressions:
-
User’s search filters defined when accessing the data.
-
Root and transition filters for Business Objects.
-
Attributes expressions for Form and Table Views.
-
Row-level security filters defined in the Model Privileges.
In these SemQL expressions, you can bind the model variable using the
:<variable name> syntax. You can also use in these expressions the
built-in :V_USERNAME bind variable.
For example, to create a privilege grant allowing the connected user to see only his own record in the Employee master data:
-
In the model, we create a variable called
CurrentUserEmail, refreshed from the LDAP directory attribute email filtered with(&(objectClass=person)(cn={V_USERNAME})). -
We create the privilege grant on the Employee entity, filtered with the following SemQL Expression:
EmailAddress=:CurrentUserEmail
The connected user will be granted these privileges only for the master data record matching this expression.
| Variable values are not persisted. They are retrieved when the user connects, and disposed at the end of the user session. If the content of the Variable Value Provider (Remote LDAP Directory or Database) is modified, the changes are taken into account only when the user re-connects to Stambia MDM. |
Display Names
Certain display properties are defined as part of the logical modeling
effort.
The Labels and Descriptions provided when creating and editing the
entities, attributes, types and references are are used when displaying
the entities of the model in the context of applications, and as default
labels and descriptions when using attributes from these entities. Other
artifacts specific to displaying a model can be defined in the model.
They include the Entity Display Names and Complex Types Display
Names, described in the following sections.
Entity Display Names
An entity is a structure containing several attributes (simple and complex). When an entity value needs to be displayed in a compact form (for example, in a table, or in a single field), the Display Name is used.
The display name defines how an entity is displayed in compact form. It
is a concatenation of several attributes, separated by a
Separator.
For example, a Contact entity is shown as <first name>˽<last name>..
To create or modify an entity display name:
-
Right-click the entity node and select Define Display Name…. The Modify Display Name wizard opens.
-
In the Modify Display Name wizard, enter the following values:
-
Separator: String that will separate the selected attributes in the display name.
-
-
Click Next.
-
In the Display Name Attributes page, select the Available Attributes that you want to add and click the Add >> button to add them to the Selected Attributes.
-
Use the Move Up and Move Down buttons to order the selected attributes.
-
Click Finish to close the wizard.
-
Press CTRL+S to save the Display Name editor.
-
Close the editor.
| Only one display name can be created for a given entity. |
|
The default display name of the entity can be customized when the entity is used:
Both these customizations are expressed as SemQL expressions that use the attributes of the entity. |
Complex Type Display Name
A complex type is a structure containing several attributes. When a complex attribute value needs to be displayed in a compact form (for example, in a table, or in a single field), the Display Name is used.
The display name defines how a complex attribute is displayed in compact
form. It is a concatenation of several definition attributes, separated
by a Separator.
For example, the GeocodedAddress complex type contains a large number
of attributes, from the simple StreetNumber down to the longitude
and latitude. A display name would be for example: StreetNumber
StreetName City Country .
To create or modify a complex attribute display name:
-
Right-click the complex attribute node and select Define Display Name…. The Modify Display Name wizard opens.
-
In the Modify Display Name wizard, enter the following values:
-
Separator: String that will separate the selected definition attributes in the display name.
-
-
Click Next.
-
In the Display Name Attributes page, select the Available Attributes that you want to add and click the Add >> button to add them to the Selected Attributes.
-
Use the Move Up and Move Down buttons to order the selected attributes.
-
Click Finish to close the wizard.
-
Press CTRL+S to save the Display Name editor.
-
Close the editor.
| Only one display name can be created for a given complex type. |
Integration Process Design
Introduction to the Integration Process
The Integration Process transforms Source Records pushed in the hub by several Publishers into consolidated and certified Golden Records. This process is automated and involves several phases, generated from the rules and constraints defined in the model. The rules and constraints are defined in the model based on the functional knowledge of the entities and the publishers involved.
Integration Process Overview
The integration process involves the following steps:
-
Source Enrichment: During this step, the source data is enriched and standardized using SemQL and Plug-in Enrichers configured to run on the source data.
-
Source Validation: The quality of the enriched data is checked against the various Constraints to be executed Pre-Consolidation.
-
Matching: This process matches pair of records either using their ID (for ID Matching entities) or (for Fuzzy Matching entities) a Matcher:
-
A matcher runs a set of Match Rules. Each rule has two phases: first, a binning phase creates small groups of records and a matching phase performs the matching within these smaller bins and detects duplicates.
-
Each match rule has a corresponding Match Score that expresses how strong the match is. A pair of records that matches according to one or more rules is given the highest Match Score of all the rules that have caused these records to match.
-
When a cluster of duplicate records is created, an overall Confidence Score is computed for that cluster. According to this score, the cluster is ready to be consolidated and confirmed. These automated actions are configured in the Merge Policy and Auto-Confirm Policy of the matcher.
-
-
Consolidation: This process consolidates (and possibly confirms) duplicates clusters detected during the matching phase into single golden records. It performs field-level or record-level consolidation. The rule for defining how the cluster consolidates is called the Consolidator.
-
Post-Consolidation Enrichment: Those of the SemQL and Plug-in Enrichers configured to run on the consolidated records run to standardize or add data to consolidated records.
-
Post-Consolidation Validation: This process is similar to the pre-consolidation validation, but is executed on the consolidated records.
Rules Involved in the Process
These rules involved in the process include:
-
Enrichers: Sequence of transformations performed on the source and/or consolidated data to make it complete and standardized.
-
Data Quality Constraints: Checks done on the source and/or consolidated data to isolate erroneous rows. These include Referential Integrity, Unique Keys, Mandatory attributes, List of Values, SemQL/Plug-in Validations
-
Matcher: This rule applies to Fuzzy Matching entities only. It is a set of matching rules that bin (group) then match similar records to detect them as duplicates. The resulting duplicates clusters are merged (consolidated) and confirmed depending on their confidence score.
-
Consolidator: Process for data reconciliation from duplicate records (detected by the matcher) into a single (golden) record.
Integration Jobs
When all the rules are defined, one of more Integration Jobs can be
defined for the model.
The integration job will run to perform the integration process, using
the hub’s database engine for most of the processing (including SemQL
processing) and Stambia MDM for running the plug-ins
code.
Integration jobs are triggered to integrate data published in batch by data integration/ETL tools, or to process data handled by users in human workflows.
When pushing data in the hub, a data integration or ETL product performs the following:
-
It requests a Load ID to identify the data load and initiate a transaction with Stambia MDM.
-
It loads data in the landing tables of Stambia MDM, possibly from several sources identified as Publishers.
-
It submits the load identified by the Load ID, and when submitting the load, it provides the name of the Integration Job that must be executed to process the incoming data.
Similarly, when a user starts a human workflow for data entry and duplicate management:
-
A transaction is created and attached to the workflow instance and is identified by a Load ID.
-
The user performs the data entry and duplicate management operations in the graphical user interface. All the data manipulations are performed within the transaction.
-
When the activity is finished, the transaction is submitted. This triggers the Integration Job specified in the workflow definition.
Human Workflows
Human Workflows allows users to perform data entry or duplicate management operations in the MDM hub:
-
In a Data Entry Workflow, a user enters new master data or modifies existing master data. For such workflow, the user is identified with a given Publisher, and the data provided by this publisher is processed normally using the integration job. Note that to modify existing master data sent by another publisher, the data entry workflow creates a copy of the other publisher’s data, and publishes this data as a copy with his own publisher’s name.
-
In a Duplicate Management Workflow, a user validates or invalidates matches automatically detected by the matching process. He is able to create or split matching groups. Such operation overrides the matching rule and is not identified with a publisher. A user decision taken in a duplicate management workflow is enforced in subsequent integration jobs execution.
When a human workflow completes, an integration job is triggered to process the data entered or the duplicate management choices made by the user.
Publishers
Publishers are application and users that provide source data to the MDM
Hub. They identify themselves using a code when pushing batches of
data.
The publisher does not represent the technical provider of the data (the
ETL or Data Integration product), but the source of the data (The CRM
Application, the Sales Management system, etc.). Examples of publishers:
CRM, Sales, Marketing, Finance, etc.
Consolidation performs certain choices depending on the publishers, and the publishers are tracked to identify the origin of the golden data certified by Stambia MDM.
| Identifying clearly and declaring the publishers is important in the design of the integration process. Make sure to identify the publishers when starting an MDM project. |
| As a general rule, use dedicated publishers for data entry operations. Such publisher can be used as a preferred publisher for all consolidation rules to enable the precedence of user entered data over application provided data. |
To create a publisher:
-
Right-click the Publishers node and select Add Publisher…. The Create New Publisher wizard opens.
-
In the Create New Publisher wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Code: Code of the publisher. This code is used by the integration process pushing data to the hub, to identify records originating from this publisher.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
-
Active: Check this box to make this publisher active. An inactive publisher is simply declared but not used in the consolidation rules.
-
Click Finish to close the wizard. The Publisher editor opens.
-
In the Description field, optionally enter a description for the Publisher.
-
Press CTRL+S to save the editor.
-
Close the editor.
Enrichment
Enrichers normalize, standardize and enrich Source Data pushed by the Publishers in the hub or Consolidated Data resulting from the match and merge process.
Enrichers have the following characteristics:
-
Several enrichers can be defined for an entity, and are executed in a sequence. The order in which they are defined in the model will be the order in which they will be executed
-
Enrichers can be enabled or disabled for integration jobs. Enrichers disabled for the jobs can be used in data entry workflows.
-
Enrichers can be configured to run on the source data and/or the consolidated data.
-
Enrichers running on source data apply to data from all publishers. It is possible to define a filter on each enricher. Only the filtered records are modified by the enricher.
There are two types of enrichers:
-
SemQL Enrichers express the enrichment rule in the SemQL language. These enrichers are executed in the hub’s database.
-
Plug-in Enrichers use a Plug-in developed in Java. These enrichers are executed by Stambia MDM. Transformation that cannot be done in within the database (for example that involve calling an external API) can be created using plug-in enrichers.
Creating SemQL Enrichers
A SemQL Enricher enriches several attributes of an entity using
attributes from this entity, transformed using SemQL expressions and
functions.
You will find SemQL examples for enrichers in the Introduction to the Stambia MDM Workbench chapter.
To create a SemQL enricher:
-
Expand the entity node, right-click the Enrichers node and select Add SemQL Enricher…. The Create New SemQL Enricher wizard opens.
-
In the Create New SemQL Enricher wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
-
Click Next.
-
In the Enricher Expressions page, select the Available Attributes that you want to enrich and click the Add >> button to add them to the Used Attributes.
-
Click Next.
-
Optionally click the
Edit Expression button to open the expression editor to define a filter. The enricher will only enrich those of the records respecting this filter. Skip this task if you want to enrich all the records. -
Click Finish to close the wizard. The SemQL Enricher editor opens.
-
In the Description field, optionally enter a description for the SemQL Enricher.
-
Select the Enrichment Scope for this enricher. The scope may be Pre-Consolidation Only, Post-Consolidation Only, Pre and Post Consolidation or None (not executed in the jobs).
-
Set the enricher expressions:
-
In the Enricher Expressions table, select the Expression column for the attribute that you want to enrich and then click the
Edit Expression button. The SemQL editor opens. -
Create a SemQL expression to load the attribute to enrich, and then click OK to close the SemQL Editor. This expression may use any attribute of the current entity.
-
Repeat the previous steps to set an expression for each attribute to enrich.
-
-
Press CTRL+S to save the editor.
-
Close the editor.
Creating Plug-in Enrichers
A Plug-in Enricher enriches several attributes of an entity using attributes from this entity, transformed using a plug-in developed in Java.
A plug-in enricher takes:
-
a list of Plug-in Inputs: These are attributes possibly transformed using SemQL.
-
a list of Plug-in Parameters values.
It returns a list of Plug-in Outputs which must be mapped on the entity attributes.
Attributes are mapped on the input to feed the plug-in and on the output to enrich the entity with the resulting data transformed by the plug-in.
| Before using a plug-in enricher, make sure the plug-in was added to the platform by the administrator. For more information, refer to the Stambia MDM Administration Guide. |
To create a plug-in enricher:
-
Expand the entity node, right-click the Enrichers node and select Add Plug-in Enricher…. The Create New Plug-in Enricher wizard opens.
-
In the Create New Plug-in Enricher wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
Plug-in ID: Select the plug-in from the list of plug-ins installed in the platform.
-
-
Click Next.
-
Optionally click the
Edit Expression button to open the expression editor to define a filter. The enricher will only enrich those of the records respecting this filter. Skip this task if you want to enrich all the records. -
Click Finish to close the wizard. The Plug-in Enricher editor opens. The Plug-in Params, Plug-in Inputs and Plug-in Outputs tables show the parameters and inputs/outputs for this plug-in.
-
Select the Enrichment Scope for this enricher. The scope may be Pre-Consolidation Only, Post-Consolidation Only, Pre and Post Consolidation or None (not executed in the jobs).
-
You can optionally add parameters to the Plug-in Params list:
-
In the Plug-in Params table, click the Define Plug-in Parameters button.
-
In the Parameters dialog, select the Available Parameters that you want to add and click the Add >> button to add them to the Used Parameters.
-
Click Finish to close the dialog.
-
-
Set the values for the parameters:
-
Click the Value column in the Plug-in Params table in front a parameter. The cell becomes editable.
-
Enter the value of the parameter in the cell, and then press Enter.
-
Repeat the previous steps to set the value for the parameters.
-
-
You can optionally add parameters to the Plug-in Inputs list:
-
In the Plug-in Inputs table, click the Define Plug-in Inputs button.
-
In the Input Bindings dialog, select the Available Inputs that you want to add and click the Add >> button to add them to the Used Inputs.
-
Click Finish to close the dialog.
-
-
Set the values for the inputs:
-
Click the Expression column in the Plug-in Inputs table in front an input and then click the
Edit Expression button. The SemQL editor opens. -
Edit the SemQL expression using the attributes to feed the plug-in input and then click OK to close the SemQL Editor.
-
Repeat the previous steps to set an expression for the inputs.
-
-
Select the attributes to bind no the Plug-in Outputs:
-
In the Plug-in Outputs table, click the Define Plug-in Outputs button.
-
In the Output Bindings dialog, select the Available Attributes that you want to enrich and click the Add >> button to add them to the Attributes Used.
-
Click Finish to close the dialog.
-
-
For each attribute in the Plug-in Outputs table, select in the Output Name column the plug-in output that you want to use to enrich the attribute shown in the Attribute Name column.
-
Optionally, you can use Advanced Plug-in Configuration properties to optimize and configure the plug-in execution.
-
Press CTRL+S to save the editor.
-
Close the editor.
Advanced Plug-in Configuration
The enrichers and validations plug-ins provide options for optimizing and configuring their execution.
The following properties appear in the Advanced Configuration section of the editor:
-
Max Retries: If the execution of the plug-in fails, it is repeated for this number of times.
-
Behavior on Error: If the execution still fails after the Max Retries have been attempted, the plug-in either Skip the current record, skips the entier enrichment task, or stops the whole job, depending on this property.
-
Thread Pool Size: This property defines the number of parallel threads used by this plug-in. This option is taken into account if the plug-in used is thread safe and declared as such.
Pre and Post-Consolidation Validation
Several validations can be defined per Entity. Validations check
attribute values and reject invalid records. All validations are
executed on each record.
Validations can take place (and/or):
-
Pre-Consolidation: Applies to source data pushed by any publishers, after the Enrichment phase, before the Consolidation Phase. All the source records pass through all the pre-consolidation checks and records failing one check are isolated from the integration flow. All the errors for each record are raised.
-
Post-Consolidation: Applies to the data de-duplicated consolidated from the various sources. All the consolidated records pass through all the post-consolidation checks and records failing one check are isolated from the integration flow. All the errors for each record are raised.
| Unique Keys are only checked post-consolidation, as they only make sense on consolidated records. |
Pre vs. Post Validation
Pre-Consolidation Validation is done on the data from all publishers to this entity, after enrichment.
Post-Consolidation Validation is done on data de-duplicated and consolidated.
Choosing a validation to be done pre and/or post validation has an
impact on the behavior of the integration hub.
The following examples will illustrate the impact of the choice of the
pre or post consolidation validation.
Example #1:
-
The CheckNullRevenue validation checks that
Customer.revenue is not null. -
Customer data is published from the CRM and Sales applications.
-
Only the Sales publisher loads revenue data. CRM leaves it null.
-
The consolidation needs critical information from the CRM application (email, name, address, etc…)
-
-
If CheckNullRevenue is executed pre-consolidation, all data from the CRM will be rejected, as revenue is null.
-
At consolidation, no data will be consolidated from the CRM.
In this example, CheckNullRevenue should be done Post-Consolidation to avoid rejecting information required later in the integration process.
Example #2:
-
The matching process for Customer uses the GeocodedAddress to match customers from all the sources.
-
An IsValidGeocodedAddress validation checks that GeocodedAddress is not empty and GeocodedAddress.Quality is high enough.
-
Enrichers will create a GeocodedAddress, if possible.
-
If the resulting GeocodedAddress is empty or not good enough, then these customers should not be processed further.
-
In this example, IsValidGeocodedAddress should be done Pre-consolidation to avoid the performance cost of matching records with addresses not meeting the entity requirements.
Matching
The matching phase detects the duplicates in order to consolidate them into a single golden record.
Matching works differently for Fuzzy Matching and ID Matching entities.
-
Fuzzy Matching Entities use a Matcher to automatically detect duplicates using fuzzy matching algorithms.
-
ID Matching Entities perform an exact match on the user-provided ID value, as this ID is a primary key that is unique across all systems.
| You can define a matcher on ID Matching Entities. It is used for the sole purpose of detecting duplicates when creating new records in a data entry workflow. Such a matcher interactively warns the user when his new entry matches existing records. |
Understanding Match and Merge
When using ID Matching, the outcome of the matching process is extremely predictable. Indeed, two records with the same ID will match and will be merged according to the Consolidator.
When using Fuzzy Matching, the outcome of the matching process is less predictable, as it is based on fuzzy matching rules and algorithms that depend on the data in the record. This section explains how match and merge work in this context.
Matching Rules and Scoring
First, the matching must detect the duplicates, that is pairs of records that match because they are somehow similar.
Multiple Match Rules in a matcher allow you to define several conditions for considering two records a match. Each condition has a different Matching Score. This score represents the percentage of confidence you put in a match that occurs thanks to a rule.
For example, the following rule (MATCH_RULE_1) defines two businesses that are exactly similar, and may have a score of 100:
Record1.CustomerName = Record2.CustomerName and Record1.InputAddress.Address = Record2.InputAddress.Address and ... Record1.InputAddress.City = Record2.InputAddress.City
The following rule (MATCH_RULE_2) would have for example a score of 85, as it detects businesses that have large number of similarities:
SEM_EDIT_DISTANCE_SIMILARITY( Record1.CustomerName, Record2.CustomerName ) > 85 and SEM_EDIT_DISTANCE_SIMILARITY( Record1.InputAddress.Address, Record2.InputAddress.Address ) > 65 and SEM_EDIT_DISTANCE_SIMILARITY( Record1.InputAddress.City, Record2.InputAddress.City ) > 65
The following rule (MATCH_RULE_3) would have a score of 20, as it detects two businesses with vaguely similar names in the same city:
SEM_EDIT_DISTANCE_SIMILARITY( Record1.CustomerName, Record2.CustomerName ) > 50 Record1.InputAddress.City = Record2.InputAddress.City
When two records match, they receive a match score equal to the highest score of all the rules that matched them (highest confidence).
For example, two records matching by the MATCH_RULE_2 (score 85) and MATCH_RULE_3 (score 20) would have a match score of 85 (the highest of 85 and 20)
Matching Groups & Group Confidence Score
Matching Groups re-group duplicate records that have matched. These groups are created using matching transitivity.
|
The matching mechanism is transitive, which means that: If A matches B and B matches C, then A, B and C are in the same matching group. |
Each matching group has a Confidence Score that expresses how confident you can be with that group of matching records.
This score is the average of the match scores in the group. Pairs in the group that have not matched by any rule are considered as having a score of zero.
For example:
-
A matches B according to MATCH_RULE_1 with a match score of 100
-
B matches C according to MATCH_RULE_3 with a match score of 20
-
A did not match C so their match score is 0.
A, B and C are in the same matching group according to the matching transitivity.
The matching group confidence score is 40: (100 + 20 + 0) / 3 = 40
Merging Groups into Golden Records
Depending of the confidence score, you may let the matcher automatically merge the match group. This operation creates a Golden Record from the group, then applies the Consolidator rule to the group of records to define the values that are consolidated in the golden record.
If a match group is not merged automatically, because its confidence score is not high enough, it is flagged as a Merge Suggestion. In that case:
-
Incoming records are kept as singleton golden records.
-
Existing group of records and golden records remain untouched.
Merge Suggestions can be reviewed by data stewards in duplicate management workflows, to decide whether or not to merge groups and create golden records.
The Merge Policy set when Creating a Matcher defines the confidence scores required to automatically merge groups in a variety of situations. See Automating Merge and Confirmation for more information about the merge policy.
Confirming Golden Record
As the values change in the source records, the match groups and golden records may change.
For example, renaming a business from "Micro Soft Incorporated" to "Micro Soft" is likely to have it match and merge with an existing "Microsoft" record, if we fuzzy-match by business name. The original "Micro Soft Incorporated" golden record would then cease to exist, as it would be merged within the "Microsoft" record.
Confirming a Golden Record consists in "freezing" the match group to avoid having it reconsidered every time data changes. This is typically done by a data steward in the context of a duplicates management workflow. The steward manually confirms the correct match groups and fixes the incorrect match groups.
Depending of the confidence score computed for a match group, you may also want to automatically confirm the golden record to avoid having the steward reviewing all the data.
The Auto-Confirm Policy set when Creating a Matcher defines the confidence score required to automatically confirm golden records. It also allows you to set whether singletons (golden records composed of a single master record) should be automatically confirmed.
Over time, records may have the following Confirmation Status:
-
Not Confirmed: The golden record was not confirmed by the matcher or a user.
-
Confirmed: The golden record was confirmed by the matcher or a user.
-
Partially Confirmed: Part of the match group that composes the golden record was confirmed by a user, but some masters in this match group are still not marked as confirmed.
-
Previously Confirmed: A golden record that was confirmed but which group has been modified by a user.
| Regardless of the Confirmation status of a record, a data stewards is always able in a duplicate management workflow to manually split and merge duplicates. |
Understanding Match Rules
Each Match Rule runs as a two phase process:
-
Binning: This phase uses a set of expressions to group the records into bins. Binning is a Divide and Conquer approach to avoid an excessive number of comparisons.
-
Matching: This phase uses a SemQL condition that compare all the pairs of record (record1 is compared with record2) within a bin. When this condition returns true, the pair of records are considered as duplicates.
The Binning Phase
The binning phase divides the source records into bins to allow the matching phase to run only within a given bin. As the matching phase can be a resource consuming one, reducing the number of comparisons is important for high performance matching.
Examples:
-
Instead of trying to match all customers, we will try to match customers only when they are located in the same country. Binning will take the Country attribute as the binning expression.
-
If we want again to make the matching phase more efficient, we could match customers with the same Country and SalesRegion.
Binning is done using several expressions defined in the matcher. The
records for which all binning expressions give the same results belong
to the same bin.
For example, to perform binning for Customers with the same Country and
Region’s first letter in the GeocodedAddress complex field, we would
use:
-
Binning Expression #1:
GeocodedAddress.Country -
Binning Expression #2:
SUBSTR(GeocodedAddress.Region,1,1)
|
Smaller Bins will mean faster processing, but, you must make sure that binning does not exclude possible
matches. For example, binning by Customer’s first four letters of the last name will split Mr. Bill Jones-Smith from Mr. Bill Jonnes-Smith into different bins. These two duplicates caused by a typo will never be matched. For this specific case, you may consider a different attribute, or a SOUNDEX on the name. If it recommended for binning to use preferably very accurate fields, such as CountryName, ZipCode, etc. |
The Matching Phase
The matching phase uses a condition that compares two records.
This condition uses two pseudo records named Record1 and Record2
corresponding to the two records being matched. If this condition is
true, then the two records are considered as matched.
For example, the following matching condition matches customer having Customer names meeting the two following requirements
-
Sounding the same in English (SOUNDEX) OR with a similar name (using edit distance) by more 80%.
-
Similar City name and address (using edit distance) by more 65%
( SOUNDEX (Record1.CustomerName) = SOUNDEX (Record2.CustomerName)
OR
SEM_EDIT_DISTANCE_SIMILARITY(Record1.CustomerName,Record2.CustomerName)>80 )
and SEM_EDIT_DISTANCE_SIMILARITY(Record1.InputAddress.Address, Record2.InputAddress.Address) > 65
and SEM_EDIT_DISTANCE_SIMILARITY( Record1.InputAddress.City, Record2.InputAddress.City ) > 65Automating Merge and Confirmation
The Merge Policy and Auto-Confirm Policy available when Creating a Matcher allow you to automatically merge and confirm detected match groups in certain situations.
Merge Policy Situations
In the merge policy, you define a confidence score threshold above which the match group is automatically merged into a golden record.
For example, if you set the value for Creating a golden record from new master records to 80, and a match group with a confidence score higher than 80 appears only from new master records, it is merged into a new golden record.
If a match group of new master records with a confidence score of 80 or lower appears, then is not merged automatically. It is proposed for merging to the data steward.
The various situations under which an automated merge may take place are listed and explained below:
-
Create a golden record from new master records: This is a frequent situation when new master records are loaded into the hub and matched/merged. The initial data loads enter in this situation.
-
Merge unconfirmed golden records: This situation occurs when existing master records attached to golden records that have not been confirmed automatically or by a data steward are modified, causing the existing golden records to possibly merge all together. In this situation, if the two unconfirmed golden records merge, one ceases to exist, and the survivor may see its values modified.
-
Merge confirmed golden records: This situation occurs when existing master records attached to golden records that have been confirmed automatically or by a data steward are modified, causing the existing golden records to possibly merge all together. In this situation, if the two golden records merge, a confirmed golden record may cease to exist, and the other one may see its values modified.
-
Merge unconfirmed with confirmed golden records: This situation occurs when existing unconfirmed golden records are about to merge with a golden record that has been confirmed automatically or by a data steward. In this situation, unconfirmed golden records may cease to exist, and the confirmed golden record may see its values modified.
-
Add new master record to an unconfirmed golden records: This situation occurs when a new master record is about to be merged with a golden record that has not been confirmed automatically or by a data steward. In this situation, the golden record values may change. This is typically the case for loads following the initial load.
-
Add new master record to a confirmed golden records: This situation occurs when a new master record is about to be merged with a golden record that has been confirmed automatically or by a data steward. In this situation, the golden record values may change. This is typically the case for loads following the initial load.
-
Merge golden records previously split by the user: This situation occurs when two groups manually split by a data steward re-matches due a new record matching both groups. In this situation, existing golden records reviewed by the data steward may cease to exist.
| A group may fall into several situations. In that case, its confidence score must exceed all the thresholds for the automated merge to happen. |
Auto-Confirm Situations
There are two situations for automatically confirming merged golden records:
-
When the match group’s confidence score is above a certain threshold, the resulting golden record can be automatically marked as confirmed.
-
Singletons, that is golden records composed of a single master record, can be automatically confirmed. Note that singletons that have match suggestions (records matched but with a score not high enough to automatically merge) are not automatically confirmed.
For example, if a match group with a confidence score of 80 was automatically merged, and the Auto-Confirm Golden Record threshold was set to 79, then this group is also marked as confirmed. If the threshold is set to 85, then this group is merged but not marked as unconfirmed.
Pattern for Automating Merge & Confirmation
Pattern #1: No Unmonitored Change
In this pattern, the data steward should review all records. All of them are treated with the same importance. No change is made and no record is created without having a user confirming it.
Solution:
-
Set all the values in the Merge Policy and Auto-Confirm Policy to 100
-
Un-select Auto-Confirm Singletons.
Pattern #2: No Stewardship
In this pattern, the hub merges and confirms all content. Fixes will take place on demand on confirmed golden records.
Solution:
-
Set all the values in the Merge Policy and Auto-Confirm Policy to 0
-
Select Auto-Confirm Singletons.
Pattern #3: Delayed Stewardship
In this pattern, the hub merges all content and confirms no record. The steward monitors and confirms all records after they are merged.
Solution:
-
Set all the values in the Merge Policy to 0
-
Set Auto-Confirm Golden Records to 100
-
Un-select Auto-Confirm Singletons.
Alternately, to reduce stewardship overheard, you may select Auto-Confirm Singletons to avoid reviewing the singletons.
Pattern #4: Merge All then Review Suspicious Matches
In this pattern, the hub merges all content but the steward must review suspicious matches.
Solution:
-
Set all the values in the Merge Policy to 0
-
Set Auto-Confirm Golden Records to 80 (adjust this value to your match rules scores)
-
Select Auto-Confirm Singletons.
The steward will be able to review suspicious unconfirmed golden records (those under the 80% confidence score).
Pattern #5: Manually Merge Suspicious Matches
In this pattern, the hub merges and confirms confident matches but the steward must manually merge others.
Solution:
-
Set all the values in the Merge Policy to 80 (adjust this value to your match rules scores)
-
Set Auto-Confirm Golden Records to 80 (adjust this value to your match rules scores)
-
Select Auto-Confirm Singletons.
Pattern #6: Prevent Golden Deletion
In this pattern, the hub must prevent golden records from ceasing to exist without the steward approval, but allows other confident merge operations to take place automatically.
Solution:
-
Set the Merge confirmed golden records, Merge unconfirmed golden records, Merge unconfirmed with confirmed golden records, Merge golden records previously split by the user to 100.
-
Set other values in the Merge Policy to 80 (adjust this value to your match rules scores)
-
Set Auto-Confirm Golden Records to 80 (adjust this value to your match rules scores)
-
Select Auto-Confirm Singletons.
Creating a Matcher
| Only one matcher can be created for each entity. |
To create a matcher:
-
Expand the entity node, right-click the Matcher node and select Define SemQL Matcher…. The Create New SemQL Matcher wizard opens.
-
In the Description field, optionally enter a description for the Matcher.
-
Click Finish to close the wizard. The SemQL Matcher editor opens.
-
Define the Match Rules:
-
Click the Add Match Rule button in the Match Rules tables. The Match Rule: NewRule editor opens.
-
Give a Name, Label and Description to the match rule.
-
Define the Binning Expressions:
-
In the Binning Expressions table, click the Add Binning Expression button. The SemQL editor opens.
-
Create a SemQL expression used to bin records for this entity, and then click OK to close the SemQL Editor. This expression may use any attribute of the current entity.
-
Repeat the previous steps to create all your binning expressions.
-
-
Define the Match Condition and Match Score:
-
In the Matching section, click the
Edit Expression button. The SemQL editor opens. -
Create a SemQL condition used to match records for this entity, and then click OK to close the SemQL Editor. This condition may use any attribute of the current entity.
-
Enter a value for the Match Score. This value should be between 1 and 100.
-
-
Press CTRL+S to save the editor.
-
Use the breadcrumb on top of the editor to return to the matcher. The new match rule appears in the list.
-
Repeat the previous steps to create all the match rules.
-
-
Define the Merge Policy: Set the minimum confidence score required for a match group to be merged in the various Merge Policy Situations.
-
Define the Auto-Confirm Policy:
-
Auto-confirm golden records: Minimum confidence score required for a match group to be automatically confirmed.
-
Auto-confirm singletons: Select this option to have singletons (un-matched records) automatically confirmed.
-
-
Press CTRL+S to save the editor.
-
Close the editor.
Consolidation
Consolidation merges fields from all the duplicates detected into a single golden record. It is defined in the Consolidator defined in the entity.
Consolidation Type
Consolidation uses one of the following methods:
-
Record Level Consolidation: Using this method, all fields are consolidated from one of the duplicates using a given strategy.
-
Field Level Consolidation: Using this method, a strategy can be defined for each attribute of the entity.
Consolidation Strategies
A consolidation strategy defines how to choose the best record or field value in the consolidation process. The consolidation strategies available differ depend on the consolidation method.
Record Level Consolidation
Record Level Consolidation supports the following strategies:
-
Any Value: The first record in the list.
-
Custom Ranking: A SemQL expression is used to ranks duplicates, and the value of the first duplicate is used for all fields. The expression is an order by clause and can contain the specification of the ascending (ASC) or descending (DESC) order.
-
Preferred Publisher: Publishers are manually ordered. The first one in the list returning a record is used.
Record level consolidation uses an Additional Order By option. This option is a SemQL Expression used to sort records in the event of an ambiguity after the first strategy. For example, when two records are duplicates from the same publisher and Preferred Publisher strategy is used.
Field Level Consolidation
With this method, a different strategy can be selected for each attribute
Field Level Consolidation supports the strategies listed in the table below. This table indicates the behavior for each strategy whether null values are skipped in the strategy or taken into account. It also shows the equivalent SemQL expression for the strategy.
| Strategy | Description | Nulls | Expression |
|---|---|---|---|
Any Value |
The first value in the list ordered by Publisher and SourceID. |
Preserved |
|
Custom Ranking |
A SemQL expression is used to ranks duplicates, and the first value by rank is used. |
User choice |
|
Largest/Smallest Value |
Values are sorted using their type-specific sort method (alphabetical for strings, for example). |
Skipped |
|
Longest/Shortest Value |
The lengths of the values are ordered. |
Skipped |
|
Most Frequent Value |
The first most frequent non null value. |
Skipped |
Specific |
Preferred Publisher |
Publishers are manually ordered. The first one returning a value for the field is used. |
User choice |
Specific |
A global Additional Order By option stores a SemQL Expression used to sort records in the event of an ambiguity after the first strategy, for example, when two fields having different values are duplicates from the same publisher and a Preferred Publisher strategy is used. The expression is an order by clause and can contain the specification of the ascending (ASC) or descending (DESC) order. Note that the additional order by clause is not supported for a Most Frequent Value consolidation strategy.
Defining a Consolidator
Every entity is created with a default Record Level Consolidator using the Any Value consolidation strategy. This default consolidation strategy should be modified to reflect the entity requirements.
To define a record-level consolidator:
-
Expand the Consolidator node under the entity and then select the child Consolidator node.
-
Right-click and select Open Object. The Consolidator editor opens.
-
Select Record Level Consolidation in the Consolidator Type.
-
In the Description field, optionally enter a description for the Consolidator.
-
In the Record Level Consolidation Strategy , select the consolidation strategy.
-
Set the parameters depending on the selected strategy.
-
Any Value: No parameter is required.
-
Custom Ranking:
-
On the Custom Ranking Expression field, click the
Edit Expression button. The SemQL editor opens. -
Create a SemQL expression used to rank the records, and then click OK to close the SemQL Editor.
Note that this expression is an order by clause and can contain the specification of the ascending (ASC) or descending (DESC) order.
-
-
Preferred Publisher:
-
In the Publisher Ranking table, click the Add Publisher Ranking button. The Manage Consolidators dialog opens.
-
Double-click the first publisher in the Available Publishers list to add to the Publishers list.
-
Repeat this operation to add the other publishers in the preference order.
-
Use the Move Up and Move Down buttons to order the publishers.
-
Click Finish to close the dialog.
-
-
-
Set the Additional Order By expression.
-
On the Additional Order By field, click the
Edit Expression button. The SemQL editor opens. -
Create a SemQL expression used to handle consolidation disambiguation, and then click OK to close the SemQL Editor.
-
-
Press CTRL+S to save the editor.
-
Close the editor.
To create a field-level consolidator:
-
Expand the Consolidator node under the entity and then select the child Consolidator node.
-
Right-click and select Open Object. The Consolidator editor opens.
-
Select Field Level Consolidation in the Consolidator Type.
-
In the Description field, optionally enter a description for the Consolidator.
-
All the fields appear in the Field Level Consolidators table and are defined with the Most Frequent Value strategy.
To modify the consolidation strategy for a field:-
Double-click the Attribute Name in the Field Level Consolidators table.
-
In the Define Field-Level Consolidator wizard, select a consolidation strategy.
-
Set the parameters depending on the selected strategy:
-
Any Value, Largest Value , Longest Value, Most Frequent Value, Shortest Value and Smallest Value: No parameter is required. Click Finish to close the wizard.
-
Custom Ranking:
-
Click Next.
-
On the Custom Ranking Expression field, click the
Edit Expression button. The SemQL editor opens. -
Create a SemQL expression used to rank the records, and then click OK to close the SemQL Editor.
-
Select the Skip Nulls option if you want to skip null values and pick the highest ranking not null value.
-
Click Finish to close the wizard.
-
-
Preferred Publisher:
-
Click Next.
-
In the Publisher Ranking table, click the Add Publisher Ranking button. The Manage Consolidators dialog opens.
-
Double-click the first publisher in the Available Publishers list to add to the Publishers list.
-
Repeat this operation to add the other publishers in the preference order.
-
Use the Move Up and Move Down buttons to order the publishers.
-
Click Finish to close the dialog.
-
Select the Skip Nulls option if you want to skip null values returned by publishers.
-
Click Finish to close the wizard.
-
-
-
-
Set the Additional Order By expression.
-
On the Additional Order By field, click the
Edit Expression button. The SemQL editor opens. -
Create a SemQL expression used to handle consolidation disambiguation, and then click OK to close the SemQL Editor.
-
-
Press CTRL+S to save the editor.
-
Close the editor.
Creating Integration Jobs
An Integration Job is a job executed by Stambia MDM to integrate and certify source data into golden records. This job uses the rules defined as part of the integration process, and contains a sequence of Tasks running these rules. Each task addresses one entity, and performs several processes (Enrichment, Validation, etc.) for this entity.
Creating Jobs
To create a job:
-
Right-click the Jobs node and select Add Job…. The Create New Job wizard opens.
-
In the Create New Job wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Description: Optionally enter a description for the Job.
-
Queue Name: Name of the queue that will contain this job.
-
-
Click Next.
-
In the Tasks page, select the Available Entities that you want to process in this job and click the Add >> button to add them to the Selected Entities.
-
Click Finish to close the wizard. The Job editor opens.
-
Select Tasks in the editor sidebar. In the list of Tasks, the entities involved in each task are listed, as well as the processes (Enrichers, Matchers, etc.) that will run for these entities.
-
Use the Move Up and Move Down buttons to order the tasks.
-
To edit the processes involved in one task:
-
Double-click the entity Name in the Tasks table. The editor switches to the Task editor.
-
Select the process that you want to enable for this task.
-
Use the editor breadcrumb to go back to the Job editor.
-
-
Press CTRL+S to save the editor.
-
Close the editor.
Jobs Parameters
Jobs can be parameterized for optimizing their execution.
To change a job parameter:
-
In the job editor, select Job Parameters in the editor sidebar.
-
In the Job Parameters table, click the Add Parameter button. The Create New Job Parameter wizard opens.
-
In the Name field, enter the name of the parameter.
-
In the Value field, enter the value for this parameter.
-
Click Finish to close the wizard.
-
Press CTRL+S to save the editor.
-
Close the editor.
The following table lists the parameters available to customize the jobs.
| Parameter Name | Values | Description |
|---|---|---|
|
0 or 1 |
If this parameter is set to 1, error recycling is triggered and rejects from previous job executions are recycled in this job. |
|
0 or 1 |
If this parameter is set to 1, statistics collection is triggered in the MDM hub tables to optimize processing. This open is useful to accelerate the processing of large data sets. |
|
0 or 1 |
If this parameter is set to 1, consecutive SemQL enrichers are merged into a single SQL statement when executed. This applies to all entities. |
|
0 or 1 |
If this parameter is set to 1, consecutive SemQL enrichers are merged into a single SQL statement when executed. This applies only to the entity which name is provided as |
Jobs Sequencing and Parallelism
Jobs are a sequence of task. These tasks must be ordered to handle referential integrity. For example, if you perform all the tasks on Contact then Customer, it is likely that new contacts attached to new customers will not be integrated as the new golden customers are not created yet.
They are themselves executed sequentially in a defined Queues in a
FIFO (First-In First-Out) mode.
If two jobs can run simultaneously, they should be in different queues.
For example, if two jobs address two different areas in the same model,
then these jobs can run simultaneously in different queues.
| It is not recommended to configure jobs processing the same entity to run in different queues. Instances of these jobs running simultaneously in two different queues may write conflicting changes to this entity, causing major data inconsistencies. |
Designing Integration Jobs
It is recommended to create jobs specific to the data loads performed by the data integration batches, and dedicated jobs for human workflows.
Integration Jobs for Data Integration
Data published in batch may target several entities.
It is recommended to define jobs specific to the data loads targeting the hub:
-
Such jobs should include all the entities loaded by the data load process.
-
In addition, it is recommended to include the entities referencing the entities loaded by the data load process.
Integration Jobs for Data Entry Workflows
A data entry workflow uses a Business Object composed of several entities.
It is recommended to define a specific job for each data entry workflow:
-
Such job should process all the entities of the business object involved in the data entry workflow.
-
In addition, if the business object contains fuzzy matching entities, the job should process all the entities referencing these entities.
Integration Jobs for Duplicate Management Workflows
A duplicate management workflow handles duplicates detected on a specific entity.
It is recommended to define a specific jobs for each duplicate management workflow:
-
Such job should process the entity involved in the duplicate management workflow.
-
In addition, if the entity involved in the duplicate management workflow is a fuzzy matching entity, the job should process all the entities referencing this entity.
Working with Applications
Applications provide business users and data stewards with a customized access to the master data and with human workflows for managing this master data.
Introduction to Applications
The model contains entities describing all the master of the enterprise. Business users and data stewards require specific access to the master data the hub, depending on their roles and privileges.
This access should:
-
Display only the relevant information organized in a business-friendly way.
-
Support workflows for master data management operations, such as data entry and duplicate management.
-
Provide dashboard to monitor the data quality as well as the workflows’ performance.
For example, a deployed model contains customer, contact, employee and cost center entities:
-
An HR user would access it and see the cost center and employee data organized with hierarchies of cost centers, hierarchies of managers/employees, and should have access to human workflows for entering or modifying employee information.
-
A Finance user would access it and see the cost center data only through a hierarchy of cost centers, and would be able to perform changes on the cost centers only.
-
A Data Steward would access all these entities to fix errors or manage duplicates, and use dashboards to monitor the status of the master data hub.
Such an access to specific access to the master data is defined in Stambia MDM using Applications.
An application provides the following features:
-
Access to the golden and master data in business-friendly views. These views aggregate data from several entities and display them in forms and hierarchies specific to business roles.
-
Human workflows for duplicates management. Through these workflows, data stewards can validate or invalidate matching decisions taken by the matchers in the automated Integration Process.
-
Human workflows for data entry. These workflows enable data stewards and business users to contribute to the hub and manually publish data that goes through the data certification process. Contribution via data entry workflows includes authoring new data, modifying existing data or fixing rejects.
-
Dashboards to monitor the data quality, the number of duplicates, the data volumes and workflows’ performance.
| From a single holistic model that includes all the master data domains (customers, suppliers, products, HR, etc.), you can define several applications (Customer Data Hub, Product Information Management, HR Hub etc.) for all the business roles and responsibilities of the enterprise. An application will expose to users the data and workflows appropriate to their roles. |
Applications
An application is made up of the following components:
-
A Home page that provides an overview of the hub, including the workflow activities, the data certification jobs and the detailed statistics of the MDM hub.
-
A Search feature to look for records in the business objects or directly in the entities.
-
Business Object Views that provide a business-friendly view of the MDM hub data. These business object views are organized into Folders in the Application Structure.
-
Human Workflows for duplicate management and data entry. These workflows can be started as Activities and follow their lifecycle through Tasks processed by the application’s users.
-
Dashboards include a default Global View dashboard and more detailed dashboards powered by Stambia MDM Pulse.
-
Applications may also provide direct access to the Entities of the MDM hub. This access allows data stewards to view the data at any stage of the certification process, and review the rejects created by this process.
The Home page, Search feature, Dashboards and Entities are automatically generated. The Application Structure, Folders, Business Object Views and Human Workflows are created as part of the application design.
| When a model is created or upgraded from an older Stambia MDM version, a simple application called Default Application is automatically created. This application contains no business object views or workflow. |
| When accessing an MDM hub (a data edition), you can select one of the applications deployed with this data edition. |
Objects and Views
In an application, business users can browse and edit the content of the MDM Hub using user-friendly views called Business Object Views.
A business object view joins several elements:
-
A Business Object, which is composite object made up from a set of related entities. It is described as a Root Entity and a set of navigable Transitions to Entity Objects. For example, the Company Hierarchy business object includes information from the Cost Center and the Employee entities, and uses the relations that link employee to managers, cost centers to parent cost centers, and employees to cost centers for the transitions.
-
Form Views and Table Views that describe the layout used to display the entities involved in business object and workflows as forms (e.g.: one Employee record) or tables (e.g.: a list of Employee records reporting to a cost center).
-
Search Forms that describe customized screens for searching and filtering each node of the business object.
| You can accelerate the design of applications by Duplicating Objects such as the business object, business object, form/table views and search forms. |
Design Process
When creating an application, the designer creates:
-
Various Forms Views and Table Views to define the layout of the entities used in the application.
-
Various Search Forms to define how to search the entities used in the application.
-
Various Business Objects by assembling Entities Objects (from the entities) and organizing them through Transitions (based on the relations).
-
Various Business Object Views that will state how these business objects must be displayed using the configured form and table views.
| Business Objects, Form/Table views and Search Forms can be reused in several Business Object Views across the applications attached to the model. The business object defines a functional group of related entities. The business object view defines how a business object is displayed in a specific application. |
Table Views
Table views are views used to display a list of records for a given entity in the context of a business object view or in a duplicate management workflow.
Such a table has is an ordered list of Table Attributes (columns in the table), and each attribute displays a SemQL expression built from the attributes of the entity. It is possible for all attributes to provide a Custom Label for the table attribute as well as a Display Types.
For example, to display a list of Employee records, we define two table views:
-
The SimpleEmployeeList table view that displays the following attributes:
-
The Employee Name, that is the First Name concatenated with Last Name using the following SemQL expression:
FirstName || ' ' || LastName -
The employee’s Cost Center.
-
-
The FullEmployeeList table view that displays the same attributes plus confidential information such as Salary, Hire Date, etc.
The first view will be used in most cases, and the second view will be relevant for applications dedicated to HR users.
The example below shows a table view in action for an Employee entity.
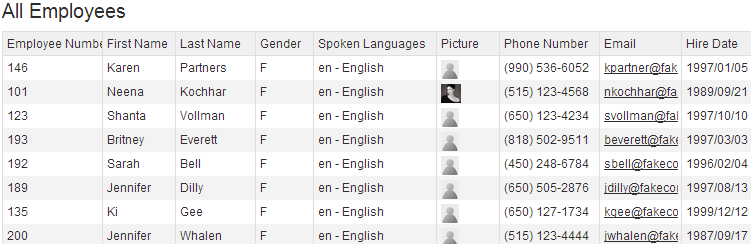
Form Views
Form views are views used to display the details for one record for a given entity.
A form view is organized in ordered Form Sections that contains an ordered list ordered list of Form Section Attributes.
Similarly to the attributes of the Table Views, the form section attributes:
-
Display a SemQL expression built from the attributes of the entity.
-
Support Custom Labels.
-
Support Display Types.
Form views support two types of layout:
-
The Flow Layout shows the sections and the attributes within the sections ordered in a vertical flow. This simple layout can be designed very fast.
-
The Grid Layout shows sections and attributes at a fixed positions in the form. They are positioned and sized on a grid at design-time. This layout required more work at design-time but gives better results for complex forms.
Both a grid and a flow layout can be defined for a form view. Switching from grid to flow is performed by user actions or automatically depending on the size of the browser window.
The figures below show a form view for an employee entity in action with a flow layout, then with a grid layout.
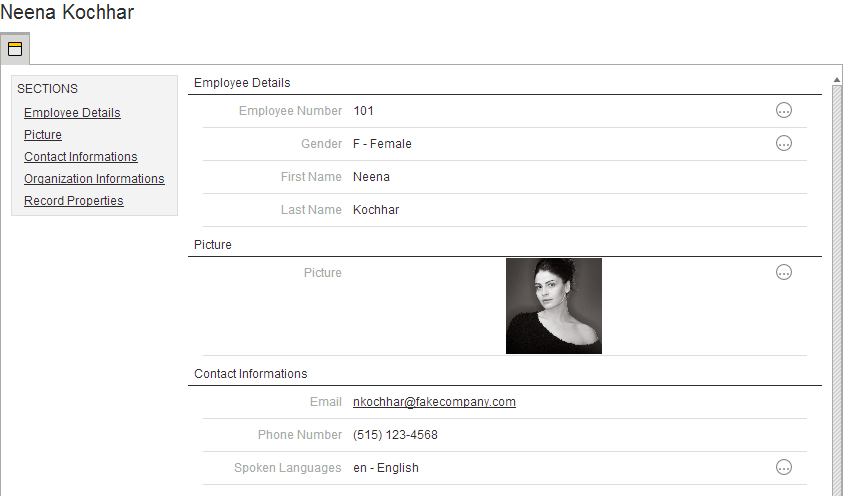
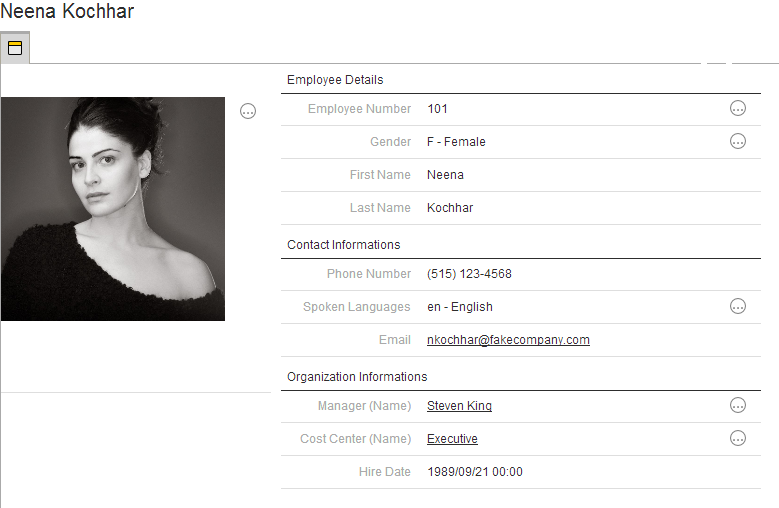
Display Types
Each form or table attribute can be associated with a Display Type. The display type defines the graphical component used to show the attribute’s value in the table or form view. The graphical component can be configured using its display properties.
The available display types are listed in the following table:
| Display Component | Description | Available Properties |
|---|---|---|
Binary Popup |
Displays the content of the binary attribute in a popup dialog. |
CompactMode |
Checkbox |
Displays a checkbox representing the Boolean value of the attribute. |
CompactMode |
Complex |
Displays the complex type’s display name with a button that expands in a popup the list of complex attributes. |
CompactMode |
Content Popup |
Displays the content of the attribute in a popup dialog. |
CompactMode |
Date |
Displays a date chooser. |
CompactMode |
Download Link |
Displays a link to download the content of a binary attribute. |
CompactMode |
Drop-Down List |
Displays the list of values attribute as a drop-down list. |
LovSortMode, LovDisplayMode, CompactMode |
Embedded Binary |
Displays the content of the binary attribute in an embedded frame. |
CompactMode |
Embedded Content |
Displays the content of the attribute in an embedded frame. |
CompactMode |
Embedded URL |
Displays the resource referred to by the attribute value in an embedded frame. The attribute value must be an URL. |
ShowURL, CompactMode |
Hyperlink |
Displays a hyperlink contained in the attribute value. |
CompactMode |
ID |
Displays an ID attribute. This display type replaces and unifies the previous |
NumberFormat, CompactMode |
Image |
Displays the binary data stored in the attribute as an image. |
Scaling Mode, Alignment, CompactMode |
Image Popup |
Displays the binary data stored in the attribute as a popup dialog. |
CompactMode |
Image URL |
Displays the resource referred to by the attribute value as an image. The attribute value must be an URL. |
Scaling Mode, Alignment, CompactMode |
Image URL Popup |
Displays the resource referred to by the attribute value as an image in a popup dialog. The attribute value must be an URL. |
CompactMode |
List Box |
Displays the list of values attribute as a list box. |
LovSortMode, LovDisplayMode, CompactMode |
Long Text |
Displays the attribute value as a long text field. |
Alignment, Multi-line, NumberFormat, CompactMode |
Multi-Value List Box |
Displays the list of values attribute as a list box that supports multiple selection. |
LovSortMode, LovDisplayMode, CompactMode |
Multi-Value Zone |
Displays the list of values attribute as a multi-value zone. |
LovSortMode, LovDisplayMode, CompactMode |
Reference Picker |
Displays the reference as a reference picker. |
CompactMode |
Text |
Displays the attribute value a text field. |
Alignment, Multi-line, NumberFormat, CompactMode |
| Each display type is appropriate for displaying certain data. Only the display types relevant for given attribute are available when editing this attribute in the workbench. |
The display properties available for the display types are described in the table below.
| Display Property | Description |
|---|---|
Alignment |
Defines the alignment of the content in the container. Possible values are |
CompactMode |
Defines whether the field is displayed using a compact form. When set to |
LovSortMode |
Defines how the list of values is sorted in the graphical component, that is by |
LovDisplayMode |
Defines how the list of value is displayed in the graphical component. Possible values are |
Multi-line |
Defines whether the text content is displayed using a multi or a single line widget. |
NumberFormat |
Defines a pattern for displaying numeric values. See Number Formatting for more information. |
ShowURL |
Set this property to |
ScalingMode |
Defines how an image content behaves in a container. Possible values are |
Number Formatting
The Number Format display property defines the pattern used for rendering numeric values.
In this pattern:
-
#corresponds to a digit. -
0corresponds to a digit that is replaced by a zero if not present. -
,corresponds to a grouping separator, (typically, a separator for the thousands). This separator is automatically localized. -
.corresponds to the decimal separator. This separator is automatically localized. -
¤(Unicode character 00A4) corresponds to the localized currency symbol. It can be used as a prefix or postfix. -
%: When used as a prefix or suffix, the value is multiplied by 100 and rendered as a percentage. -
You can specificy two different patterns for positive and negative values, separated by a semi-colon. For example “###.00;(###.##)” renders negative values between parenthesis.
The complete pattern reference (including exponential and scienticic notations) is available in the Java Decimal Format Pattern reference.
Pattern examples (in a US-English Locale):
| Pattern | Value | Result |
|---|---|---|
|
15000000.2 |
15,000,000.2 |
|
15000000.2 |
1500,0000.2 |
|
15.2 |
15.20 |
|
15.2 |
15 |
|
15.2 |
0015 |
|
15.2 |
15.20 |
|
-15.2 |
(15.2) |
|
152 |
152$ |
Built-in Search Types and Search Forms
Stambia MDM provides the following built-in search types to look for data in entities:
-
Text: The text search looks up all attributes marked as Searchable in the model that match your search pattern. You can use the
%wildcard to match a number of characters or_to match a single character. -
By Form: This method shows a default form with all the attributes avaialable, and pickers to select values to filter these attributes.
-
Advanced Search: Advanced search allows you to specify which attributes to search on and the operators you want to use for comparison.
-
SemQL: SemQL search allows you use SemQL queries to search. With SemQL, you can use attributes in parent entities or child entities, as well as the SemQL library of functions.
In addition to these search types, you can design your own Search Forms.
A Search Form exposes several Search Parameters. When the user submits a search form, a search query is issued, using these parameters are bind values.
Business Objects
A Business Object is a composite object made up from a set of related
entities. It is a functional subset of the model.
For example, the Company Hierarchy business object includes
information from the Cost Center and the Employee entities, and uses
the relations that link employees to managers, cost centers to parent
cost centers, and employees to cost centers.
Entities used in the business object are defined as Entity Objects. A given entity may appear several times in the same business object. For example, the Customer entity may be used in a business object twice, once to describe the Domestic Customers and once for the International Customers. An entity object is a direct link to an entity, associated with a Filter.
Transitions enable the navigation between entity objects within a given business object. The transitions are created based on the relationship references defined between the entities. For example, if the Cost Center entity is related to the Employee entity through the Employee has Cost Center reference relationship, it is possible in a business object to create a transition to navigate from the cost center to the reporting employees.
A business object is always defined with a Root Entity Object. This
root entity object is the entry point of the business object.
For example, in the Company Hierarchy business object, the root entity
object is created from the Cost Center entity, filtered to only return
the root cost centers in the hierarchy of cost centers (that is those
with no parent cost center).
Business Object Views
A Business Object View defines how the business object appears and is used in the application:
-
For each entity object, you select a form view to define how one record is displayed. For example, the details of one cost center.
-
For each transition, you select a table view to define how the list of child elements of a transition is displayed. For example, the list of employees reporting to a cost center, or the list of child cost centers attached to a given cost center.
-
For each entity object, you create a Search Configuration to defined the available built-in search methods and configurable search forms.
Business object views are defined within an application, and serve two purposes:
-
They are used to browse and search data in a user friendly way from the Application Structure.
-
They are used to edit data in the hub as part of a Data Entry Activity.
The following example shows one instance of the CostCenter business object, displayed through a business object view. The CostCenter business object uses CostCenter as its root object (filtered to show only the root cost centers), and has transitions to the Child Cost Centers (this transition recurses to show an infinite depth of cost centers) and to the cost center’s Reporting Employees. The form and tables used to display each node of the hierarchy are defined in the business object view.
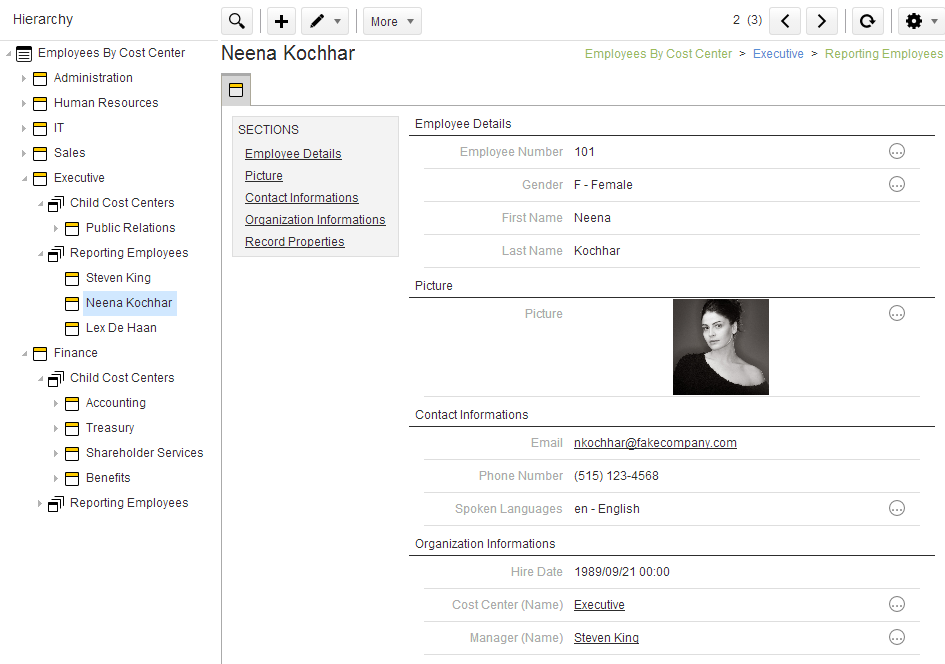
Human Workflows
Human Workflows enable business users to manage the data in the MDM hub
via an application.
When users want to manage the master data, they initiate an Activity
based on a predefined human workflow. This activity follows the workflow
through Transitions and Tasks which are assigned to roles, claimed,
processed and then completed by users. The last task of a workflow can
submit (or cancel) the data changes done in the activity, and start a
data certification process with these changes.
There are two types of human workflows in Stambia MDM:
-
Duplicate Management Workflows: These workflows allow data stewards to override the decisions taken by the matchers running in the hub. Through these workflows, stewards can either manually match unmatched records, or split duplicate groups that were incorrectly matched (false matches).
-
Data Entry Workflows: These workflows allow data stewards or business users to contribute to the hub as manual publishers. The data entered via these workflows goes through the data certification process to create golden data. Contribution via data entry workflows includes authoring new data, modifying existing data or fixing rejects.
| You can accelerate the design of applications by duplicating workflows. |
Workflow Lifecycle
A workflow is a set of tasks, linked by transitions. A running
or completed workflow instance is called an Activity.
An activity is initiated from an Application. When an activity runs, it
executes a single task at a time. A task is assigned to a role
declared in Stambia MDM. Such a task can be claimed by a user having this
role. This user then can perform data entry or duplicate management
operations. When the task is completed, the user completes the task and
moves it through a transition to another task.
The task may finish the activity either via a submit or a cancel operation. The cancel operation cancels any duplicate management or data entry action, and the submit operation submits into the hub the data entry or duplicate management transaction. After a submit operation, an integration job is started to certify the changes performed in the activity.
Transaction
An activity carries along a Load Transaction (equivalent to an external load) which contains the duplicates modified or the records manually entered by the users. This transaction attached to the activity, and is transferred with the activity when a task is assigned to a role. This enables multiple entry/edition points and validations steps as part of the workflow.
Creating an Application
An application provides a customized access to the MDM Hub.
To create an application:
-
Right-click the Applications node and select Add Application…. The Create New Application wizard opens.
-
In the Create New Application wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label for is automatically filled in. Modifying this label is optional.
-
Required Role: The application is by default available for all users. To restrict access to this application to a specific role, select it from the dropdown list.
-
-
Click Finish to close the wizard. The Application editor opens.
-
In the Description field, optionally enter a description for the Application.
-
Configure the Display Properties for the application:
-
Sort Method: Defines the sort method for folders and business object views in this application. They can be automatically sorted alphabetically according to their Label or organized in a fixed Position set at design-time.
-
Auto-Refresh: Enables auto-refresh of the list of activities displayed in the application, at the Refresh Interval (in seconds).
-
-
If you want to add or remove features from the application, or restrict feature access to certain roles, select in the Available Features section the features to activate and the required roles for each activated feature.
-
In the Available Features section, configure the Dashboard Scope for the Pulse dashboards embedded in the application:
-
Model (default): The dashboards display metrics of all entities and workflows in the model.
-
Application: The dashboards only display metrics of the entities used in the application, and of the workflows in the application.
-
-
Save the editor.
|
It is possible to create multiple applications for a single model and to support different views to this model. For example, a simple application for users browsing the hub through the Business Object Views, another application supporting in addition data entry workflows, and a third application for data stewards showing in addition the details of the entities. |
Creating Views and Objects
Views and object define how business users and data stewards see the MDM hub content in an application.
Creating Table Views
A Table View provides a layout for displaying a list of records for a given entity.
To create a table view:
-
Right-click the Table Views node under an entity and select Add Table View…. The Create New Table View wizard opens.
-
In the Create New Table View wizard, enter the following values:
-
Name: Internal name of the object.
-
Default: Select this option if the table view should be used as the default table view for this entity.
-
-
Click Finish to close the wizard. The Table View editor opens.
The table view editor display a list of available attributes and a table showing all the attributes from the table view, with their label and SemQL expression.
To add attributes to a table view:
-
In the Table View editor’s Table tab, drag an attribute from the available Attributes list to the list of table attributes. The new attribute is added to the table attributes table:
-
In the table attributes table, you can modify the Name, Label, or Height or this table attribute.
-
Click the (…) Edit Expression button to create a complex expression for the table attribute.
-
You can also reorder attributes in this table using drag and drop.
-
-
To edit an attribute, select the Properties view, and then select the attribute in the attributes table. The Properties view shows all its properties, including:
-
Name, Label and Description. Note that if the Use Custom Label option is unchecked, then a default label is used: if the SemQL expression is a simple entity attribute, the default label is the label of this attribute, otherwise, the text of the SemQL expressions is used.
-
Display Types used for the table attribute.
-
Help Content: content displayed as the help text for the attribute. This either the attribute metadata or its description.
-
Read-Only: Select this option to make this field read-only. If this form is used for data entry, read-only fields cannot be edited in the form regardless of the user privileges. Use this option for example to make part of the form or the entier form un-editable, or to include form attributes that are loaded only via enrichers.
-
| You can add not only attributes from the entity, but also attributes of entities related to the current entity (For example, an employee’s parent Cost Center name), or any complex SemQL expression. |
| You can alternately select (by pressing the CTRL key) and drag and drop multiple attributes from the attribute list. |
To remove an attribute from a table view:
-
Select the attribute in the attributes table.
-
Click the Delete Selection button in the editor toolbar and confirm the deletion. The attribute is removed from the table.
Creating Form Views
A Form View provides an organized layout for displaying a given entity record in a form. It is composed of several Form Sections, each section containing Form Attributes.
Form view are arranged either using a vertical Flow Layout, where section and attributes are simply ordered, or a Grid Layout, where each section and attribute is positioned on a grid. You may design a form with one or both layouts. When both layouts are available, the form view switches from grid to flow layout either by user action, or automatically when the display falls below a certain width.
To create a form view:
-
Right-click the Form Views node under an entity and select Add Form View…. The Create New Form View wizard opens.
-
In the Create New Form View wizard, enter the following values:
-
Name: Internal name of the object.
-
Default Form View: Select this option if the form view should be used as the default form view for this entity.
-
Default Layout: Select the layout used when opening the form view.
-
User Layout Switch: Select this option to enable the layout switch by the user.
-
Auto Layout Switch: Select this option to enable the automated switch based on the Auto Layout Width.
-
-
Click Finish to close the wizard. The Form View editor opens.
| To design both the flow and grid layouts for the form view, you must have either User Layout Switch or Auto Layout Switch activated. Otherwise, you can only design the layout selected in the Default Layout. |
When working with the Form View editor:
-
The Overview tab shows the global options for the form view.
-
The Outline view shows the sections and attributes available for this form. Those visible in the currently selected (Flow or Grid) view appear in bold font in the Outline.
-
The Properties view shows the properties of the selected section or attribute.
-
The Grid tab shows a grid corresponding to the grid layout for the form, and the Flow tab shows a table with the ordered list of sections and attributes for the flow layout.
Configuring the Form
In the Overview tab, you can configure the following parameters:
-
The Default Layout for the form view (Grid or Flow). If you enable either User Layout Switch or Auto Layout Switch, both layouts will be available to the user. Auto Layout Switch switches the layout to Flow when the display is below the Auto Layout Width in pixels.
-
The Section Navigator for the flow layout appears as a table of content, tabs or a list of links to switch from section to section. Its position and appearance are configured using the Section Navigator Look and Section Nav. Position options. You can also define whether sections should be managed as expandable/collapsible components.
-
The Label alignment defines the position of all the labels in the form view.
-
Attribute Minimum Width and Attribute Maximum Width are values in pixel that limit the resizing of the attributes on large or small displays.
Flow Layout Design
In the flow layout, you define and order form sections containing form attributes.
To add a form section:
-
In the Flow tab of the Form View editor, click the Add Form Section button in the toolbar. A new form section is added to the list.
-
Edit the Name and Label for this section directly in the table or in the Properties view.
-
Optionally, you can:
-
Make the section visible or invisible using the Toggle Selection Visibility button in the toolbar.
-
Reorganize the sections order using drag and drop in the table.
-
| A section or attribute can be visible in the flow and/or grid layout. Changing an attribute or section visibility with the Toggle Selection Visibility button does not remove it from the form, and can be reverted. Using the Remove Selection button deletes the attribute or section from the form entirely, which cannot be undone. |
To delete a form section:
-
In the Flow tab of the Form View editor, select the form section and then click the Delete Selection button.
-
Confirm your choice. The section and all its form attributes are deleted.
To add a form attribute:
-
In the Flow tab of the Form View editor, drag an attribute from the available Attributes list to an existing form section. The new attribute is added under the form section. You can now:
-
Modify the Name, Label and Flow Height (size of the attribute in number of lines) for this attribute.
-
Click the (…) Edit Expression button to create a complex expression for the table attribute.
-
Re-position the attribute using drag and drop.
-
-
Select the Properties view and then select the attribute in the attributes table. The Properties view shows all the attribute properties, including:
-
Name, Label and Description. Note that if the Use Custom Label option is unchecked, then a default label is used: if the SemQL expression is a simple entity attribute, the default label is the label of this attribute, otherwise, the text of the SemQL expressions is used
-
Display Type used for the table attribute.
-
Help Content: Content displayed as the help text for the attribute. This either the attribute metadata or its description.
-
Certain properties available for form attributes are used specifically in the flow layout:
-
Flow Height defines the height of the displayed component in number of lines.
-
Expandable defines whether a complex attribute appears as an expandable attribute by default. Such expandable component is optionally Expanded by Default.
-
Customized Display Name for reference attributes. If it is checked, you can specify a SemQL Display Name Expression that defines the label shown for the reference. Otherwise, the entity display name is used instead.
| You can alternately select (by pressing the CTRL key) and drag and drop multiple attributes from the attribute list. If you drag them into a section, they are added to this section. If you drag them outside of the sections, a new section is automatically created. |
To remove an attribute from a form section:
-
Select the attribute in the attributes table.
-
Click the Delete Selection button and confirm the deletion. The attribute is removed from the form section.
Grid Layout Design
In the grid layout, each section and each attribute is positioned at an absolute position on a grid, and has a defined height and width.
To add a new form section:
-
In the Grid tab of the Form View editor, click the Form Section button or drag the button to a position in the grid. A new form section is added to the grid.
-
In the Properties view set the following properties for the new section:
-
Name, Label and Description.
-
X-Coordinate, Y-Coordinate, Width and Height to position and size the section.
-
Display Label: Un-select this option to hide the label of this section in the grid layout.
-
| Use the toolbar to move and re-size faster the selected form section or attribute. Multiple selection is supported. |
To add an existing form section:
-
Drag an existing form section from the Outline view to the grid. The section is added to the grid and you can edit it from the Properties view.
To delete a form section:
-
Select the form section from the grid and then click the Delete Selection button.
-
Confirm your choice. The section and all its form attributes are deleted.
To add a new form attribute:
-
In the Grid tab of the Form View editor, drag an attribute from the available Attributes list to an existing section in the grid. The new attribute is added to the grid.
-
Select the Properties view and then select the attribute in the grid. The Properties view shows all the attribute properties, including:
-
Name, Label and Description. Note that if the Use Custom Label option is unchecked, then a default label is used: if the SemQL expression is a simple entity attribute, the default label is the label of this attribute, otherwise, the text of the SemQL expressions is used.
-
Display Type used for the form attribute.
-
Help Content: Content displayed as the help text for the attribute. This either the attribute metadata or its description.
-
Customized Display Name for reference attributes. If it is checked, you can specify a SemQL Display Name Expression that defines the label shown for the reference. Otherwise, the entity display name is used instead.
-
X-Coordinate, Y-Coordinate, Width and Height to position and size the attribute. You can also drag the attribute directly in the grid to position within its section.
-
Label Position to define the position of the label for the attributes (top, left or hidden) and Label Wrap to indicate whether the label text should wrap when overflowing. Label Width defines the size of the label.
-
| You can drag and drop multiple attributes from the attribute list to the grid. If they are dropped on an existing section, they are added to the section. If they are dropped on the grid, a section is automatically created around these attributes. |
To add an existing form attribute:
-
Drag an existing form attribute from the Outline view to the grid. The section is added to the grid and you can edit it from the Properties view.
To remove an attribute from a form section:
-
Select the attribute in the grid.
-
Click the Delete Selection button and confirm the deletion. The attribute is removed from the form section.
Creating Search Forms
A Search Form exposes several Search Parameters to look for records in an entity. When the user submits a search form, a search query is issued, using these parameters are bind values.
| New search forms are imediatly available for the entity in the application, but not in the business object views using that entity. You must define a Search Configuration in the business object views to enable or disable both the built-in search types and your own search forms. |
To create a search form:
-
Right-click the Search Forms node under an entity and select Add Search Form…. The Create New Search Form wizard opens.
-
In the Create New Search Form wizard, enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label in this search form.
-
Description: Description of this search form.
-
-
Click Finish to close the wizard. The Search Form editor opens.
-
Define a Search Tip text that will be displayed in the search form.
-
Add a search parameter:
-
In the Search Parameters table, click the Add Search Parameter button. The Create New Search Parameter wizard opens.
-
In the Create New Search Parameter wizard, enter the following values:
-
Name: Internal name of the object.
-
Binding: You use this binding string in the search form SemQL query condition to refer to this parameter. Note that as the Auto Fill box is checked, the Binding is automatically filled in. Modifying the binding is optional.
-
Label: User-friendly label for this search parameter. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
Mandatory: Check this box if this parameter must be set to run the search.
-
Use Type, Length, Scale and Precision to define logical data type of this parameter.
-
-
Click Finish to close the wizard. The parameter appears in the Search Parameters table.
-
To edit a search parameter: Select the Properties view and then select the search parameter in the table. The Properties view shows all its properties, including the Name and Definition as well as the Search Parameters Display Properties.
-
To remove a search parameter, select the search parameter in the search parameters table, click the Delete button and then confirm the deletion.
-
-
Use the Properties view to configure the search parameter.
-
-
Repeat the previous step to create all your search parameters.
-
Reorder search parameters in the table using the Move Up and Move Down buttons.
-
Create a SemQL Condition for the search query by clicking the
Edit Expression button to open the SemQL Editor. Note that the SemQL editor displays the search form parameters bindings in the Variables section.
Search Parameters Display Properties
The Display Type of a search parameter define the component used to display this parameter in the search form. A Display Type is optionally configured through display properties.
The display type available for a search parameter depends on its logical data Type. For example, the Date Picker display type is available only for a DateTime search parameter.
The display types are listed below with their properties:
-
Text Field: Simple text field. This type is available for all logical data types.
-
Checkbox: Simple checkbox. This type is available for the Boolean logical data type.
-
Date Picker: Date selector. This display type is available for the DateTime logical type.
-
Drop Down List: Selectable list of elements. This display type is typically used to select a search parameter value from a list of values. It is configured using the following options:
-
Display Format: Defines whether the label and/or code of the list of values should be displayed.
-
Sort Order: Defines if the list of values should be sorted by the code or label.
-
-
Value Picker: Component opening a popup dialog to select filtered values from a given entity of the model. It is configured using the following options:
-
Lookup Entity: Entity from which the values are selected.
-
Table View: Table view used in the value picker component.
-
Filter Expression: SemQL expression used to filter the entity data. This expression can use other search parameters' values.
-
Bound Select Expression: SemQL expression defining the value returned by a value picker selection.
-
Use Distinct: Check this option to only display distinct values in the value picker.
-
Display Count: Check this option to display the count of records for each distinct value in the picker. This option is available if Use Distinct is selected
-
Sort By Count: If Display Count is selected, this option allows sorting by ascending or descending record count.
-
Default Sort Expression: If Use Distinct is not selected, this SemQL expression defines the sort order of the records in the value picker.
-
SemQL Condition for Search
The SemQL Condition defined for the search form can use attributes from the search entity as well as attributes from related (parent or child) entities. Refer to a search parameter with its Binding prefixed by a colon :.
For example, if a search form on the Customers entity has one parameter labeled Searched Name (binding: SEARCHED_NAME), the following SemQL condition filters customers by their name.
CustomerName like '%' || :SEARCHED_NAME || '%'
If we add to this form a second parameter labeled Has Influencer Contact (Binding: HAS_INFLUENCER_CONTACT), the following SemQL condition filters customers by their name and possibly depending on the fact that they have one or more contacts with IsInfluencer = 1
CustomerName like '%' || :SEARCHED_NAME || '%' and ( :HAS_INFLUENCER_CONTACT = 0 or any Contacts have (IsInfluencer = 1) )
| For a detailed description of the SemQL language with examples, refer to the Stambia MDM SemQL Reference Guide. |
Creating Business Objects
A Business Object is a composite object made up from a set of related entities. It is a functional subset of the model.
To create a new business object:
-
Right-click the Business Objects node and select Add Business Object…. The Create New Business Object wizard opens.
-
In the Create New Business Object wizard, enter the following values:
-
Entity: Select the root Entity Object for this business object. The root entity is the main entity of this business object, or the highest entity in the business object’s hierarchy.
-
Name: Internal name for this root Entity Object. The name default to the name of the entity suffixed with
EO.
-
-
Click Next.
-
In the second page of the Create New Business Object wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the business object. It is named by default after the root entity.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
Plural Label: User-friendly label when referring to several instances of this business object. The value for the plural label is automatically generated from the Label value and can be optionally modified.
-
In the Description field, optionally enter a description for the Business Object.
-
-
Click Next.
-
Enter a Root Filter expression for the Business Object. This filter selects only the records of the root entity that should appear when opening the business object. For example, in a business object representing the hierarchy of Cost Centers, we should filter only the cost centers with no parent cost center. The navigation to child cost centers will be defined later in the business object.
-
Click Finish to close the wizard. The Business Object editor opens.
-
Press CTRL+S to save the new business object.
After creating a business object, only the records of the root entity filtered by the root filter are displayed (for example, the root Cost Centers of the hierarchy). To include more entities in the business object (for example, child Cost Centers or Employees reporting to the cost centers), it is necessary to create Transitions to other Entity Objects.
You can create transitions from the root entity object or from any entity object in the business object.
To create transitions:
-
Create a transition from the root entity object or from another entity object:
-
To create a transition from the root entity object: In the Business Object editor, click the Add Transition button in the Transitions table. The Create New Business Object Transition wizard opens.
-
To create a transition from another entity object: In the Business Object editor, select the entity in the Transitions table and then click the Add Child Transition button. The Create New Business Object Transition wizard opens.
-
-
In the Create New Business Object Transition wizard, enter the following values:
-
Reference: Select a one of the references from the parent entity object. This reference points to one of the entities related to the parent entity object. For example, the reference that links a Cost Center to its child cost center or to its reporting employees.
-
Name: Internal Name of this transition. The default name is the Referencing Role Name for the selected relation.
-
Label: Label for this transition. The default name is the Referencing Role Label for the selected relation. Note that you can set a customized label, plural label and description specific to this transition later. Double-clicking a transition in the editor for a business object opens the transition for edition.
-
-
Click Next.
-
The target of the transition may be either a New Entity Object or an Existing Entity Object:
-
To use an Existing Entity Object:
-
Select Use Existing Entity Object and then click Next.
-
Select an existing entity object as the Target Entity Object of the transition.
-
Click Next.
-
Enter a Filter expression for this transition. This filter select only the records of the target entity object that should appear when navigating through this transition.
-
-
To use a New Entity Object:
-
Select New Entity Object and then click Next.
-
Select in the Entity field an existing entity that will be target of this transition.
-
In Name, enter an internal name for this new entity object. The name default to the name of the entity suffixed with
EO. -
Click Next.
-
Enter a Filter expression for this transition. This filter select only the records of the target entity object that should appear when navigating through this transition.
-
-
It is possible to create hierarchies with infinite depth by
creating a transition from an entity object to itself. For example, to
create a hierarchy of cost centers, create a business object with a
Cost center as the root entity object (call it CostCenterEO) and a
root filter selecting only the cost centers with no parents (e.g.:
ParentCostCenter is null). Then add a transition using the
self-relation linking parent and child cost centers, and transition to
the existing CostCenterEO.
|
Creating Business Object Views
| Before creating the Business Object Views, make sure that the appropriate business objects are created and that forms and table views exist for all the entities involved in these business objects. |
To create a business object view:
-
Right-click the Business Object Views node and select Add Business Object View…. The Create New Business Object View wizard opens.
-
In the Create New Business Object View wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
Business Object: Select an existing business object.
-
Visible: Select or un-select this option to make this business object view visible or not in the application structure. A business object that is invisible can still be used in a data entry workflow.
-
Folder: Optionally select a folder into which this business object view will appear.
-
Required Role: Optionally select a role required to view and open this business object view. This role is required in addition to the privilege grants on the entities composing the business object.
-
-
Click Finish to close the wizard. The Business Object View editor opens.
-
In the Business Object View editor, configure the Display Properties:
-
Use Search on Open: Select this option to open the search dialog when the business object view is accessed. Otherwise, the business object view opens directly either on the first record, or on the list of records at the root of the business object.
-
Open As: Select whether the business object view should open on the Record List or the First Record in the list.
-
Auto-Refresh: Enables auto-refresh for this business object view, at the Refresh Interval (in seconds).
-
Advanced Business Object View Configuration
When the business object view is created, every entity object in the hierarchy of the related business object maps to:
-
A Form View used to display one record of this node when browsing the data. The default form view for the entity is set by default.
-
An optional Data Entry Form View used to edit one record in this node when editing data in a workflow.
-
A Table View used to display the list of records in this node. The default form view for the entity is set by default.
It is also possible to configure a customized Sort Expression for the records in the node, and a customized Display Name for showing the records the hierarchy tree. -
An optional Search Configuration that defines the available built-in and customozed search methods.
If the form views used contain references pointing to other entities, you can define for these references how References Browsing (for browsing data) and References Selection (for data entry) will behave.
To configure the views and the references behavior:
-
In the Business Object View editor, in the Hierarchy section, review the Form/Table Views associated with the business object’s entity objects. To change or set one of these views:
-
Select a node in the hierarchy corresponding to the entity object. The Properties view shows the Entity Object Form View properties.
-
In the Name and Definition section, select a Table View, a Form View and optionally a Data Entry Form View.
-
Select the Customized Sort options and then set a SemQL Sort Expression to define the default sort order.
-
Select User-Defined Sort to allow users to define their own sort order for this node in the hierarchy.
-
-
Optionally configure the references navigation:
-
Select the References Browsing section in the Properties view.
-
Click the Refresh button in the Properties view toolbar to refresh the list of browsable references.
-
For each reference listed, select a Browsing Target: Not Browsable makes the reference not navigable, Default Form View opens a popup with the default form view for the entity and Business Object View opens a business object view that contains in its hierarchy the target of the reference. If you select a Business Object View target, then you can select a Target Business Object View
-
-
Optionally configure the references selection:
-
Select the References Selection section in the Properties view.
-
Click the Refresh button in the Properties view toolbar to refresh the list of selectable references.
-
For each reference listed, select a whether the reference selection component should display a Reference ID Input Field. If this option is not selected, the only way to select a reference is via a reference picker popup dialog.
-
Optionally set for each reference a Reference Picker Filter. This filter restricts the possible selection. Such a filter is used for example when selecting the Customer referenced by a Contact, to filter only those of the Customers located in the same country as the Contact.
-
-
Press CTRL+S to save the editor.
You can also configure for each entity object in the hiearchy the built-in search types and customized search forms available in the search dialog.
To define the search configuration:
-
In the Business Object View editor, in the Hierarchy section, select a node in the hierarchy corresponding to the entity object. The Properties view shows this Entity Object's' properties.
-
Select the Search Configuration section in the Properties view.
-
Click the Refresh button in the Properties view toolbar to refresh the list of available search forms.
-
Select the Available checkbox to enable or disable a built-in search type or a user-defined search form.
-
Define the order of the search types using the Move Up and Move Down buttons.
-
Repeat the previous step to assign the correct view to each entity object and transition.
-
Press CTRL+S to save the editor.
Tips for Creating Views and Objects
| You can accelerate the design of applications by Duplicating Objects such as the business object, business object, form and table views. |
Creating Views for Specific Purposes
It is recommended to create different business objects/table/forms views for specific purposes. From the same business object, it is possible to design several different views that serve a variety of purposes. For example, create different business object views for browsing the same data with a reduced number or attributes for certain users and a more comprehensive set of attributes for power users.
It is not necessary to have business object view dedicated to data entry, as a business object view references different form views for browsing and for data entry. If you want to create business object views that will be used only for data entry, make sure to create them with the Visible flag un-selected, so that they do not appear in the application structure.
Selecting Attributes for Views
The form/table views designed and used in a business object view define the attributes visible when the business object is used.
Key Attributes
The key for a record depends on the context (master record, golden record, source record, etc.) as well as the type of entity (fuzzy or exact matching). To make form design simpler and consistent, you can simply include the primary key attribute for the entity in the form or table view. Depending on the context and entity type, the correct attribute will be displayed. For example, for a source record of a fuzzy matching entity, the SourceID will be displayed. Unless you want to have a specifically one of the key attributes displayed (Golden ID, SourceID, etc.), you should not specifically add one of these in the form or table view.
Data Entry Form Views
For data entry purposes, certain attributes are required in the form views:
-
The entity primary key attribute is required. Depending on the entity type and context, the appropriate attribute is automatically displayed.
-
It is also recommended to include the mandatory fields in the data entry form views unless null values are automatically handled by the enrichers. Otherwise, mandatory value validation may reject data entries.
-
If an entity is attached to a parent entity, it is recommended to include the foreign display name attributes to allow attaching a record to a given parent. For example an employee is attached to a cost center and a manager. The corresponding FDN_CostCenter and FDN_Manager attributes should be added to the form view used to edit the employee, for example to assign the employee to a specific cost center or manager.
| When creating a business object view, make sure that the form views set for data entry include the primary key attribute. |
Organizing the Application with Folders
You can use folders to organize the business object views in the application.
Creating Folders
To create a folder:
-
Double-click the Folders node under the application. The Application opens on the Folders section.
-
Click the Add Root Folders button to create a root folder, or select an existing folder and select Add Child Folder… to create a sub-folder. The Create New Folder wizard opens.
-
In the Create New Folder wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the folder.
-
Label: User-friendly label for this folder. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
-
Click Finish to close the wizard. The Folder is added to the list of folders.
Organizing Business Object Views and Folders
You can select the folder containing a business object view when creating this business object view or change it afterwards.
You can also, if you have selected Position for the application’s Sort Order, define the order of the folders and business object views.
To organize business objects and folders:
-
Double-click the Folders node under the application. The Application opens on the Folders section.
-
Use this view to organize business object views and sub-folders into folders using drag and drop.
You can also use the Move Up and Move Down buttons to position these folders.
| Changing the order of the folders and business object views is possible only if the application’s Sort Order is set to Position. You can modify this value in the Details tab of the application editor. |
Creating Human Workflows
Human Workflows enable business users to manage the data in the MDM hub via an application.
| You can accelerate the design of applications by duplicating existing workflows. |
Creating a New Duplicate Management Workflow
To create a duplicate management workflow:
-
Right-click the Human Workflows node and select Add Duplicate Management Workflow…. The Create New Duplicates Workflow wizard opens.
-
In the Create New Duplicates Workflow wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
Managed Entity: Select the entity whose duplicates can be handled by this workflow. Note that only fuzzy matching entities appear in this list.
-
On Submit Job: Select the job to execute when the workflow completes with a Submit operation.
-
Initiator Role: Role required to create a new activity using this workflow.
-
Admin Role: Role required to administer an activity using this workflow. Users with this role can perform any operation on an activity based on this workflow.
-
Start from HomePage: Select this option if you want to start this workflow from the application’s home page. If this option is not selected, the workflow does not appear on the homepage but may still be started via the context menu to create or modify records.
-
Editable Properties: Select this option to enable initiators to edit the activities' Startup Comment, Label and Priority properties after the activities' creation.
-
-
Click Finish to close the wizard. The Duplicates Workflow editor opens.
Creating a New Data Entry Workflow
To create a data entry workflow:
-
Right-click the Human Workflows node and select Add Data Entry Workflow…. The Create New Data Entry Workflow wizard opens.
-
In the Create New Data Entry Workflow wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
Data Entry Publisher: Select the publisher defined in the model that will used to submit the data entries.
-
On Submit Job: Select the job to execute when the workflow completes with a Submit operation.
-
Initiator Role: Role required to create a new activity using this workflow.
-
Admin Role: Role required to administer an activity using this workflow. Users with this role can perform any operation on an activity based on this workflow.
-
Start from HomePage: Select this option if you want to start this workflow from the application’s home page. If this option is not selected, the workflow does not appear on the homepage but may still be started via the context menu to create or modify records.
-
Editable Properties: Select this option to enable initiators to edit the activities' Startup Comment, Label and Priority properties after the activities' creation.
-
-
Click Next. In the next page, select the actions available for this workflow:
-
Checkout Golden Records: Select this option to allow users to copy existing golden records to this workflow’s transaction. These records will be editable as part of the workflow.
-
Checkout Master Records: Select this option to allow users to check previously authored master records out or copy master records from other publishers to this workflow’s transaction. These records will be editable as part of the workflow.
-
Checkout Rejects: Select this option to allow users to check rejects out into this workflow’s transaction. These records will be editable as part of the workflow.
-
Create New Record: Select this option to allow users to create new records using this workflow.
-
-
Click Next.
-
In the Business Object Views page, select a Business Object View in the Available BO Views list and then click the Add >> button to add it to the Selected BO Views.
-
Repeat the previous operation to add other BO Views to this workflow.
-
Order the Business Object Views using the Move Up and Move Down buttons. The Business Object Views are displayed in this order at run-time.
-
Click Finish to close the wizard. The Data Entry Workflow editor opens.
The Workflow Editor
The workflow editor displays the workflow as a diagram. This diagram is used to configure, add tasks and transitions to the workflow.
This workflow contains by default the following elements:
-
A Start Event that represents the startup point for this workflow. All the start tasks are linked from this event.
-
An End Event that represents the completion point for this workflow. This event is preceded by two built-in tasks called Submit Data and Cancel Data that represent the submit and cancel operations that finish a workflow.
-
A Task that is linked from the Start Event and that links to the Submit Data and Cancel Data built-in tasks. This task is a placeholder that can be removed or modified.
| It is possible to link the start event to your tasks, but your tasks cannot link directly to the end event. They must transition to the built-in Submit Data and Cancel Data tasks that finish the workflow. |
Configuring the Workflow
The workflow can be configured from the Properties view. Click the background of the workflow diagram to open the workflow properties.
All workflow have the following properties sections:
-
Name and Definition: The Name, Label, Description, Initiator Role, Admin Role and On Submit Job options in this section are configured when creating the workflow and can be changed here. For Data Entry workflows, the Data Entry Publisher appears here. The additional Start from Homepage (to define whether the workflow can be started on the homepage) and Editable Properties (to define whether certain properties can be modified after startup) also appear in this section.
-
Tasks: The list of tasks of the workflow.
-
Transitions: The list of transitions of the workflow.
Data Entry workflows have specific properties sections:
-
Actions: The Checkout Golden Records, Checkout Master Records, Checkout Rejects and Create New Records options are configured when creating a data entry workflow.
-
Business Object Views: The list of default business objects managed by this data entry workflow. It is possible to override this list on each task of the workflow.
Duplicate Management workflows have the Managed Entity section with the following properties:
-
Managed Entity: This option lets you choose the entity whose duplicates are handled by this workflow.
-
Table View: The table view used to display the entity records. This table view should include attributes relevant for duplicates management.
Adding a Task
To add a task from the diagram:
-
In the Workflow diagram, select the Add Task tool in the Palette.
-
Click the diagram. The Create New Task wizard appears.
-
In the Create New Task wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
Assigned to Role: Select the role to which this task is automatically assigned.
-
The new task appears in the diagram. If it is the first task added to this workflow, it is linked from the start event.
Configuring a Task
A task selected in the workflow is configured from the Properties view.
The Name and Definition properties section contains the following properties: Name, Label, Description and Assigned to Role.
For data entry workflows’ tasks, it is in addition possible to:
-
Override the list of Business Object Views defined at workflow level with other Business Object views specific to the given task.
-
Configure enrichers and validations triggered when data entry is performed in a task.
| Task-specific Business Object Views help deliver an optimal experience for the data entry process. Enrichers triggered in tasks add interactivity in the data entry. Validations on tasks enforce data quality as part of the data entry process by proactively detecting errors. |
Overriding Business Object Views in Tasks
A task of a data entry workflow can override the default business object views from the workflow and use a different set of business object views.
Setting Business Object Views on tasks allows workflow designers to specialize the data entry experience for each task of the workflow. For example, a first task uses a Business Object View to edit simple attributes, and a second (optional) task uses a different one to edit advanced attributes.
To override business object views in tasks:
-
Select the task in the workflow diagram. The Properties view displays this task’s properties.
-
Select the Business Object Views section in the Properties view.
-
Click the Define Managed Business Object Views button in the Properties view toolbar. The Manage Tasks dialog opens.
-
Select the appropriate Available Business Object Views and click the Add >> button to add them to the Selected Business Object Views
-
Order the Business Object Views using the Move Up and Move Down buttons. The Business Object Views are displayed in this order at run-time.
-
Click Finish to close the dialog.
-
Select the Name and Definition section in the Properties view.
-
Select the Override BO Views option. This option must be selected in order to take into account the BO Views of the task instead of those from the workflow.
Configuring Enrichers and Validations in Tasks
A task of a data entry workflow can provide interactive feedback to the user. This feedback includes:
-
Triggering enrichers to populate or augment attributes automatically.
-
Trigger validations to raise issues to the user as he enters data.
The following sections are available in the Properties view for configuring the interactive feedback for data entry tasks:
-
The Enrichers section contains the list of enrichers applicable to the business objects managed by the workflow. These enrichers may be triggered during the workflow execution.
-
The Validations section contains the list of validations applicable to the business objects managed by the workflow. These validations may be triggered during the workflow execution.
| Enrichers triggered in a task modify the data entered in the transaction. The modified data is persisted in the transaction. |
The triggers for validations and enrichers in a given task are:
-
Keystrokes: Execute the validation or enricher when keystrokes are done in the data edition window.
-
Field Exit: Execute the validation or enricher when the focus goes out of a field.
-
Manual: Execute the validation or enricher when the user clicks the Validate button.
-
Save: Execute the validation or enricher when the user saves data in the transaction or clicks the Validate button.
-
None: The validation or enricher is not executed during this task.
| When they have the same execution trigger, enrichers are always executed before validations. |
| The validations at a task level have an informational purpose, and do not prevent a user from entering incorrect data. You may prevent the user from proceeding with the workflow using transition validations. See Configuring Enrichers and Validations in Transitions for more information. |
Adding a Transition
A transition links to tasks in the diagram.
To add a transition from the diagram:
-
In the Workflow diagram, select the Add Transition tool in the Palette.
-
Select a task the diagram or the Start event. Keep the mouse button pressed, and move the cursor to the next task in the workflow, or the built-in Submit or Cancel tasks.
-
Release the mouse button.
The transition is created and a link appears between the two elements in the diagram.
| Transitions have a direction. If a transition goes from Task_A to Task_B, it only means that you can move in the activity from Task_A to Task_B. If you want to move from Task_B to Task_A, then you must create another transition in the other direction. |
| It is possible to create multiple transitions between two tasks, even in the same direction. For example, you can have two transition path from Task_A to Task_B, each transition having a different configuration. |
Configuring a Transition
A transition selected in the workflow is configured from the
Properties view.
The Name and Definition properties section contains the following task
properties: Name, Label and Description. Label and description
are customized only if the Use Custom Label option is selected. By
default, a transition is named after the target task of this transition.
The Show Task Completion Dialog option allows you to skip the dialog that prompts a user who completes the task using that transition.
Configuring Enrichers and Validations in Transitions
A transition of a data entry workflow can enforce data quality checks. These checks warn the user of possible data issues and can optionally block the transition.
The following sections are available in the Properties view for configuring the checks for data entry transitions:
-
The Validations section contains the list of validations applicable to the business objects managed by the workflow. Each validation is configured to Warn the user, Block the transition, or you can simply Skip it.
-
The Enrichers section contains the list of enrichers applicable to the business objects managed by the workflow. Select the enrichers to execute before the validations.
| Selected enrichers are always executed before validations. |
| Validations marked as Block prevent the workflow from proceeding through the transition. Validation marked as Warn may be ignored by the user. |
Validating an Application
An application or a component of the application (business objects, workflow) must be validated to ensure its correct behavior after deployment and raise possible issues. For example, in a workflow, a task that cannot be reached or a task that cannot lead to the end of the workflow.
To validate the application or one component from the diagram:
-
In the Model Design view, select the node corresponding to your application, business process or human workflow, right-click and then select Validate.
-
The validation process starts. At the end of the process, the list of issues (errors and warnings) is displayed in the Validation Log view. You can click an error or waning to open the object causing this issue.
The workflow is also validated as part of the overall model validation.
Opening an Application
You can connect the deployed applications from the Welcome page.
To open an application:
-
Open a new tab in your web browser and connect to the URL that provided by your administrator. For example
http://<host>:<port>/stambiamdm/where<host>and<port>represent the name and port of the host running the Stambia MDM application. If you are not logged in yet, the Login Form is displayed. -
Enter your user name and password.
-
Click Log In. The Stambia MDM Welcome page opens.
-
In the welcome page, recently connected and available applications and data editions appear as buttons named as follows:
<application_name> [<data edition>] (<data location name>).-
Select a recently opened application in the Recent Application group,
-
Select one of the applications available to you from the Available Applications group.
-
Click the More… button to open a given data edition in a data location, optionally using an application:
-
Select a Data Location from the list
-
Select a Data Edition in this Data Location. By selecting the Latest edition, you always connect to the latest edition.
-
Optionally select an application available in this data edition.
-
Click the Open button.
-
-
The application opens.
| You can bookmark the URL when connected to a given application to return directly to this application. |
| When designing applications, changes made to the views, business objects, applications and workflows are directly applied to the development data location without having to go through a model deployment or update procedure. You simply need to refresh the browser tab connected to the application to see these changes. |
Applications Global Configuration
All applications running in a Stambia MDM instance share configuration properties such as the header logo or the export limits. These properties are configured from the Administration Console. See the Managing the Platform chapter in the Stambia MDM Administration Guide for more information.
Models Management
Stambia MDM supports out of the box metadata versioning.
When working with a model in the Stambia MDM Workbench, the developer works
on a Model Edition, that is a version of the model.
Model management includes all the operations required to manage the versions of the models.
Introduction to Metadata Versioning
A Model Edition is at a given point of time either Open or Closed
for editing.
Branching allows you to maintain two or more parallel Branches (lines)
of model editions.
Model Editions and Branches
-
An Open Model Edition can be modified, and is considered as being designed. When a milestone is reached and the design is considered complete, the model can be closed. When a model edition is closed, a new model edition is created and opened. This new model edition contains the same content as the closed edition.
-
A Closed Model Edition can no longer be modified and cannot be reopened. You can only edit an edition of this model open on the same branch or on a different branch.
-
When a model from a previously closed edition needs to be reopened for edition (for example for maintenance purposes), a new branch based on this old edition can be created and a first edition on this branch is opened. This edition contains the same content as the closed edition it originates from.
Version Numbers
A model has a version number that is automatically generated with the
Branch ID number and Model Edition number. The branch and model numbers
start at zero and are automatically incremented as you create new
branches or model editions.
A model edition appears in the following format:
<Model Name> [<branch>.<edition>]. For example, the first model
edition in the first branch has the version [0.0]. The fourth edition
of the CustomerAndFinancialMDM model in the second branch is named
CustomerAndFinancialMDM [1.3].
A Chronological Example
The following example shows the chronological evolution of a model through editions and branching:
-
January: a new CustomerHub model is created with the first branch and the first edition. This is CustomerHub [0.0].
-
March : The design of this model is complete. The CustomerHub [0.0] edition is closed and deployed. The new model edition automatically opened is CustomerHub [0.1].
-
April: Minor fixes are done on CustomerHub [0.1]. To deploy these to production, the model edition CustomerHub [0.1] is closed, deployed to production and a new edition CustomerHub [0.2] is created and is left open untouched for maintenance.
-
May: A new project to extend the original hub starts. In order to develop the new project and maintain the hub deployed in production, a new branch with a first edition in this branch are created, based on CustomerHub [0.1] (closed). Two models are now opened: CustomerHub [0.2] which will be used for maintenance, and CustomerHub [1.0] into which new developments are done.
-
June: Maintenance fixes need to take place on the hub deployed in production.CustomerHub [0.2] is modified, closed and sent to production. A new edition is created: Customer [0.3].
-
August: Then new project completes. CustomerHub [1.0] is now ready for release and is closed before shipping. A new edition CustomerHub [1.1] is created and opened.
The following schema illustrates the timeline for the edition and branches. Note that the changes is the two branches are totally decoupled. Stars indicate changes done in the model editions:
Month : January March April May June August Branch 0 : [0.0] -***-> [0.1] -*-> [0.2] ----------*-> [0.3] -----------> Branch 1 : +-branching-> [1.0] -**-**-****-> [1.1] --->
At that stage, two editions on two different branches remain and are open: CustomerHub [1.1] and CustomerHub [0.3].
Working with Model Editions and Branches
Model edition and branching can be managed from the Model Administration perspective.
To access the data administration perspective:
-
Select the Overview perspective the toolbar.
-
In the Overview, click the Manage Model Editions… link in the Administration section. The Model Administration perspective opens.
Creating a New Model
Creating a new model creates the model with the first model branch and model edition.
To create a new model:
-
In the menu, select File > New > New Model…. The Create New Model wizard opens.
-
In the Create New Model wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
-
In the Description field, optionally enter a description for the Model.
-
Click Finish to close the wizard. The new model is created, with a root branch and a first edition.
-
Model Edition perspective opens on the new model.
Closing and Creating a New Model Edition
This operation closes the latest open model edition in a branch and opens a new one. The closed model edition is frozen and can no longer be edited, but can be deployed to production environments.
| It is only possible to close an open edition. This edition is the latest one from a branch. |
| It is only possible to close an edition that is valid. |
To close and create a new edition:
-
In the Model Editions view of the Data Administration Perspective, expand the model and the model branch containing the edition that you want to close.
-
Right-click the latest model edition of the branch (indicated as opened) and select Close and Create New Edition.
-
Click OK to confirm closing the model edition.
-
The Enter a comment for this new model edition dialog, enter a comment for the new model edition. This comment should explain why this new edition was created.
-
Click OK. The model is validated, then a new model edition is created and appears in the Model Editions view.
| Be cautious when closing a model edition. Closing an edition cannot be undone, and a closed edition cannot be reopened. |
Branching a Model Edition
Branching a model edition allows restarting modifying a closed edition of a model. Branching creates a new branch based on a given edition, and opens a first edition of this branch.
| It is only possible to branch from closed model editions. |
When creating a model, a first branch named
<model_name>_root is created with the first model edition.
|
To create a new branch:
-
In the Model Editions view of the Data Administration Perspective, expand the model and the model branch containing the edition from which you want to branch.
-
Right-click closed the edition from which you want to branch and select Create Model Branch From this Edition. The Create New Model Branch wizard opens.
-
In the Create New Model Branch wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
-
In the Description field, optionally enter a description for the Model Branch.
-
Click Finish to close the wizard.
-
In the Model Branch Created dialog, click Yes to open the first edition of this new branch.
-
The newly created edition opens.
Model Localization
When designing a model, labels, descriptions and other user-facing text strings are entered to provide a user-friendly experience. These strings are natively externalized in Stambia MDM, and can be translated (localized) in any language.
A user connecting an application created with Stambia MDM will see these strings (label of the entities, attributes, list of values, etc.) translated in the locale of his web browser if such translation is available. If no translation is available in his locale for a given text, the default string (for example, the label or description specified in the model) is used. These default strings are the base translation.
| make sure to translate the entire model in a given language to avoid partially translated user interfaces. |
Translation Bundles
Strings translation is performed using Translation Bundles, attached
to model editions. A translation bundle is a properties file that
contains a list of key/value pairs corresponding to the strings
localized in a given locale. The translation bundle file is named
translations_<locale>.properties, where <locale> is the locale of the
translation.
The following example is a sample of a translation bundle file for the
English language (translations_en.properties). In this file, the label
for the Employee entity is the string Staff Member, and its
description is A person who works for our company.
... Entity.Employee.Label=Staff Member Entity.Employee.Description=A person who works for our company. Attribute.Employee.FirstName.Label=First Name Attribute.Employee.FirstName.Description=First name of the employee Attribute.Employee.Picture.Label=<New Key TODO> ...
Translating a Model
To translate a model:
-
The translation bundles are exported for the language(s) requiring translation in a single zip file.
-
Each translation bundle is translated by a translator using his translation tooling.
-
The translated bundles are re-imported into the model edition (either each file at a time, or as a single zip file).
To export translation bundles:
-
In the Model Editions view (Model Administration perspective), expand the model edition that you want to localize.
-
Right-click and then select Export Translation Bundles…. The Export Translation Bundles wizard opens.
-
Select the languages that you want to translate.
-
Select Export Base Bundle if you also want to export the base bundle for reference. The base bundle contains the default strings, and cannot be translated.
-
Select the Encoding for the exported bundles. Note that the encoding should be UTF-8 unless the language that you want to translate or the translation tooling has other encoding requirements.
-
Select in Values to Export the export type:
-
All exports all the keys with their current translated value. If a key is not translated yet, the value exported is the one specified by the Default Values option.
-
New keys only exports only the keys not translated yet.
-
All expect removed keys exports all keys available, excluding those with no corresponding object in the model. For example, the key for the description of an attribute that was deleted from a previous model edition will not be not exported.
-
-
Select in Default Values the value to set for new keys (keys with no translation in the language).
-
Use values for base bundle sets the value to the base bundle value.
-
Use the defined tag sets the value to the tag specified in the field at the right of the selection (defaults to
<New Key TODO>). -
Leave Empty set the value to an empty string.
-
-
Click OK to download the translation bundles in a zip format and then Close to close the wizard.
To import translation bundles:
-
In the Model Editions view (Model Administration perspective), expand the model edition that you want to localize.
-
Right-click and then select Import Translation Bundles…. The Import Translation Bundles wizard opens.
-
Click the Open button and select the translation file to import. This file should be either a properties file named
translations_<locale>.propertiesor a zip file containing several of these properties files. -
In the Language to Import table, select the language translations that you want to import.
-
Select the Encoding for the import. Note that this encoding should correspond to the encoding of the properties files that you import.
-
Select Cleanup Removed Keys During Import if you want to remove the translations for the keys that are no longer used in the model. This cleanup remove translation no longer used by the model.
-
Click Finish to run the import.
The translations for the model edition in the selected languages are updated with those contained in the translation bundles. If the Cleanup Removed Keys During Import was selected, translations in these languages no longer used in the model are removed.
Translation and Model Edition Lifecycles
The lifecycle of the translations is entirely decoupled from the model edition and deployment lifecycle:
-
It is possible to modify the translations of open or closed model editions, including deployed model editions in production data locations.
-
Translation changes on deployed model editions are taken into account dynamically when a user accesses a data edition based on this model edition.
| Decoupling the translation lifecycle from the model edition avoids binding the critical model development and release process to the translation process, as the latter frequently is managed by a separate team. This also allows adding new translations or fixing translations without having to re-deploy a new model edition. |
| When creating a new model edition, the translations from the previous model edition are not copied to the next edition. It is necessary to export and import translations between editions. |
Deployment
This process is the deployment in a run-time environment (for production or development) of a model designed with its integration process.
Introduction to Deployment
Deployment consist in creating or updating in a Data Location (a database schema accessed via a JDBC datasource) a Model Edition. Once this model edition is deployed, it is possible to create a Data Edition (version of the data) using this model edition (version of the metadata).
In this process, the following components are involved:
-
A Data Location is a database schema into which several Model Editions of the same model will be deployed and Data Editions will be created. This data location is declared in Stambia MDM, and uses a JDBC datasource defined in the application server.
-
In a data location, a Deployed Model Edition is a model version deployed at a given time in a data location. As an MDM Hub model evolves over time, for example to include new entities or functional areas, new model editions are created then deployed. Deployed Model Editions reflect this evolution in the structure of the MDM Hub.
-
Similarly, a Data Edition reflects the evolution of the data stored in the hub over time. You can perform snapshots (editions) of the master data at given points in time. Data Editions reflect the evolution in the content of the MDM Hub.
In the deployment process:
-
You can maintain as many data locations as you want in Stambia MDM, but a data location is always attached to one repository.
-
A data location can contains editions from the one single model .
-
You can deploy several model editions into the same data location.
-
You can only have one open data edition in a data location. You can have old (closed) data editions in the same location. These closed editions are read-only, and can use old deployed model editions.
Data Location Types
There are two types of data location. This type is selected when the data location is created and cannot be changed afterwards:
The data location types are:
-
Development Data Locations: A data location of this type supports installing and updating open or closed model editions. In short, it allows also install/update of models being edited.
-
Production Data Location: A data location of this type supports installing only closed model editions. Updating is not allowed, and deploying an editable model edition (opened) is not allowed.
| Be cautious when choosing the data location type, at is will determine the type of deployment operations that can be done. It is recommended to use only Production Data locations for Production and User Acceptance Test environments. |
Data Location Structures
A Data Edition is based on one of the Model Editions deployed in the location. Many data editions may coexist in the same data location.
The various data editions are stored in the same data structures. The data structures (tables) in a given Data Location are compatible with any of the Model Editions deployed in this data location. When a new model edition is installed, the structures are modified to support this new model edition in addition to the ones previously deployed.
In addition, data duplication is avoided as much as possible. For example: If a Golden Record exists but remains the same for 5 editions, it is only stored once golden data table, and not replicated five times.
Creating a Data Location
A Data Location is a database schema into which several Model Editions will be deployed and Data Editions will be created.
| A data location is a connection to a database schema via a JDBC datasource defined in the application server running Stambia MDM. Make sure to have the administrator of this application server create this datasource, and to have the database administrator create the schema for you before creating the data location in Stambia MDM Workbench. |
To create a new data location:
-
In the menu, select File > New > New Data Location. The Create New Data Location wizard opens.
-
In the Create New Data Location wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
JNDI Datasource Name: Select the JDBC datasource pointing to the schema that will host the data location.
-
In the Description field, optionally enter a description for the Data Location.
-
Select the Location Type for this data location.
-
Select the Root Model: This model is the model for which editions can be deployed into the data location.
-
-
Click Finish to close the wizard. The Data Locations perspective opens and the Data Editions view displays the new data location.
To delete a data location:
-
In the Data Editions view, right-click the data location node and select Delete. The Delete Data Location wizard opens. In this wizard, you only delete the data location definition in Stambia MDM. Deleting the data stored in the data location is optional.
-
If you do not want to delete all the data in the data location schema, click Finish. The data location is deleted but the data is preserved.
-
If you want to delete all the data in the data location schema:
-
Select the Drop the content of the database schema to delete the content of the schema. Note that with this option, you choose to delete all the data stored in the hub, which cannot be undone.
-
Click Next. The wizard lists the objects that will be dropped from the schema.
-
In the next wizard step, enter
DROPto validate the choice, and then click Finish. The data location as well as the schema content are deleted.
-
-
| Deleting a data location is an operation that cannot be undone. |
| Deleting the data location as well as the schema content is convenient mechanism to reset the hub content at the early stages of the model design. |
Deploying a Model Edition
There are two ways of deploying a model edition:
-
Install a Model Edition: This operation creates a new deployed model edition based on a given edition of the data location model. Note that if the data location is a production data location, the model edition must be closed.
-
Update a Model Edition: In a development data location, this option allows updating a deployed model edition that was previously deployed with the possible changes performed since the deployment or latest update operation. This method can be used to deploy and update for testing purposes model being developed at design-time.
Installing a Model Edition
To install a model edition:
-
In the Data Editions view, right-click the data location node and select Install Model Edition…. The Install Model Edition wizard opens.
-
In the Install Model Edition wizard, enter the following values:
-
Model Edition: Select the model edition to deploy into this location. Note that only the editions of the model selected for this data location are displayed.
-
-
In the Description field, optionally enter a description for the Model Edition.
-
Click Next. The changes to perform in the data location to support this new model edition are computed. A second page shows the SQL script to run on the schema to deploy this model edition. This script can be executed by Stambia MDM or you can download, customize and execute it separately.
-
To run this script:
-
Click Finish to run the script and close the wizard.
The model editon deploys first the jobs and then runs the SQL code to create the physical tables. You can follow this second operation in the Console view at the bottom of the Workbench.
-
-
To download the script:
-
Click the download link.
-
Click Cancel to quit the wizard without running the script.
-
Run the script manually.
-
Restart the wizard from Step 1. The wizard should detect no DDL changes.
-
Click Finish to create the integration jobs and register the new deployed model edition.
-
-
In the future, when you perform changes to this model’s structure, you will be able to create new editions of this model (For example [0.2], [0.3], …) and will be able to deploy these new editions in the same data location. These new deployments will generate patching scripts to bring the physical database objects to the level of the new model edition.
| Deploying a model edition does not modify data in the data editions already in place in the data location. |
Updating a Model Edition
To update a model edition:
-
In the Data Editions view, expand the data location node and the Deployed Model Edition node.
-
Right-click the deployed model edition that you want to update and select Update Deployed Model Edition (Design-Time). The Update Deployed Model Edition wizard opens.
-
In the Update Deployed Model Edition wizard, select the items that you want to update: Integration Jobs, Purge Jobs and/or Database schema.
-
Click Next. The list of DDL instructions needed to update the data structures is displayed.
-
Click Finish to run the script and close the wizard.
| Updating the job definitions erases all the logs attached to the previous job definitions. |
|
Although it is recommended to update both the jobs and schemas
at the same time, you may want to update the data structure first then
the jobs later. For example, if the data that you have in the data
editions using this model edition is not fit for the new version of the
jobs. In that case, you may want to run some transformation on the data
with the updated data structures before updating the jobs. Another use case for not deploying the job definition is when you know that the new and old job definition are similar and you want to preserve the existing job logs. |
Creating a Data Edition
Creating a Root Data Edition
To create a data edition:
-
In the Data Editions view, select the data location node, right-click and select Create Root Data Edition. The Create New Root Data Edition wizard opens.
-
In the Create New Root Data Edition wizard, check the Auto Fill option and then enter the following values:
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
-
In the Description field, optionally enter a description for the Root Data Branch.
-
Click Next.
-
In the Data Edition screen, select the Deployed Model Edition that will support the data edition.
-
In the Description field, optionally enter a description for the Root Data Edition.
-
Click Finish to close the wizard. The RootBranch data branch is created and a first data edition is created under this root branch.
This data edition is open. It means that we can perform loads and changes to this edition.
Later on, you will be able to close this edition and open a new one.
Closing an edition freezes its content, creating a snapshot of the MDM
Hub content.
Closing and Creating a New Data Edition
To close and create a new data edition:
-
In the Data Editions view, expand the data location node.
-
Expand the Data Branches > RootBranch node.
-
Right-click the latest data edition (open) and select Close and Create New Edition. The Close and Create New Data Edition wizard opens.
-
In the Close and Create New Data Edition wizard, enter a Description for the new data edition.
-
Select the Deployed Model Edition that will support the data edition.
-
Click Finish to close the wizard. The new data edition under the RootBranch data branch is created. The previous data edition is closed.
| It is possible to close and create a new edition while data entry or duplicate management workflows are in progress in the data edition. Long running workflows can execute across several data editions. A warning is issued workflows are in progress. |
| When closing and opening a new data edition with a different model edition, there is no check performed on the new model to guarantee that the ongoing workflows are supported with the new model. The administrator should check that all ongoing workflows will be able to continue to completion with the new model edition. |
| If integration jobs are currently running for this data edition, you may be prompted to move it to a Maintenance mode. This status allows current jobs to complete while rejecting new submitted jobs. |
| You can automate this operation in production environements using the Administrative Web Service. See the Web Services chapter in the Stambia MDM Integration Guide for more information. |
Advanced Deployment Techniques
Switching Model Edition
This operation allows you to change the deployed model edition
supporting a given data edition without closing the data edition.
This prevent you from creating data snapshots for model changes.
To perform the switch, you must first move the data edition to Maintenance mode.
To swich a data edition to a different model edition:
-
In the Data Editions view, expand the data location node.
-
Expand the Data Branches > RootBranch node.
-
Right-click the latest data edition (open) and select Switch Model Edition. The Switch Model Edition wizard opens.
-
Select the Deployed Model Edition that will support the data edition from now on.
-
Check the option if you want to automatically re-open the data edition after the switch.
-
Click Finish to close the wizard. The data edition is now switched to the new model edition.
If you have not selected the option to automatically re-open the data edition, you must now move it back to Open.
Moving Models at Design-Time
At design-time, it is possible to move models from one repository to another design repository using Export/Import:
-
Export is allowed from a design repository, but also from a deployment repository.
-
Import is possible in a design repository, either:
-
to create a new model from the import
-
or to overwrite an existing open model edition.
-
Exporting a Model Edition
To export a model edition:
-
Open the Model Editions perspective.
-
Expand the model branch containing the model edition that you want to export.
-
Select the model edition that you want to export, right click and select Export Model Edition.
-
In the Model Edition Export dialog, select an Encoding for the export file.
-
Click OK to download the export file on your local file system.
-
Click Close.
Importing to a New Model
To import and create a new model:
-
In the menu, select File > New > New Model from import... The Import to a New Model wizard opens.
-
Click the Open button and select the export file.
-
Click Finish to perform the import.
Click the Refresh button in the Model Editions view. The new model appears in the list.
Importing on an Existing Model
To import and replace an existing model:
-
Open the Model Editions perspective.
-
Expand the model branch containing the model edition that you want to replace.
-
Select the open model edition that you want to replace, right click and select Import Replace…. The Import-Replace Model Edition wizard opens.
-
Click the Open button and select the export file.
-
Click Finish to perform the import.
-
Click OK to confirm the deletion of the existing model.
The existing model edition is replaced by the content of the export file.
Deploying to a Remote Location
Frequently, the deployment environment is separated from the development environment. For example, the development/QA and production sites are located on different networks or locations. In such cases, it is necessary to use export and import to transfer the model edition before performing the deployment in production.
A remote deployment consists in moving a closed model edition:
-
From a design repository or a deployment repository used for Testing/UAT purposes;
-
To a deployment repository.
Remote Deployment Architecture
In this configuration, two repositories are created instead of one:
-
A Design repository for the development and QA site, with Development data locations attached to this repository.
-
A Deployment repository for the production site. Production data locations are attached to this repository.
The process for deploying a model edition in this configuration is given below:
-
The model edition is closed in the design repository.
-
The closed model edition is exported from the design repository to an export file.
-
The closed model edition is imported from the export file into the deployment repository.
-
The closed model edition is deployed from the deployment repository into a production data location.
Exporting a Model Edition
To export a model edition:
-
Open the Model Editions perspective.
-
Expand the model branch containing the model edition that you want to export.
-
Select the closed model edition that you want to export, right click and select Export Model Edition.
-
In the Model Edition Export dialog, select an Encoding for the export file.
-
Click OK to download the export file on your local file system.
-
Click Close.
Importing a Model Edition in a Deployment Repository
To import a model edition in a deployment repository:
-
Open the Model Editions perspective.
-
Select File > New > Import Model Edition. The Import Model Editions wizard opens.
-
Click the Open button and select the export file.
-
Click Next.
-
Review the content of the Import Preview page and then click Finish.
| When importing a model edition, the root model and the branches containing this model edition are automatically created as needed. |
| When importing successive versions of model editions in a deployment repository, it is not recommended to skip intermediate versions, as it is not possible later to import these intermediate versions. For example, if importing version 0.1 of a model, then importing version 0.4, the intermediate versions - 0.2, 0.3 - can longer be imported into this repository. |
Data Edition Statuses
Understanding Data Edition Statuses
This section provided detailed information about the processes involved when closing a data edition.
A data edition can be in three statuses:
-
Open: A data edition in this status can be accessed in read/write mode, accepts incoming batches and processes its current batches.
-
Closed: A closed data edition can be accessed in read mode, does not accept incoming batch (a submit load on this data edition will fail) and no batch is in processing. This status cannot be modified.
-
Maintenance: A data edition in this status can be accessed in read-only mode. It does not accept incoming batches but completes its current batches. New loads cannot be initialized and existing loads cannot be submitted. Unlike the closed status, this status can be reverted to the open status.
When moving a data edition to a closed status, no batch must be in progress. You must first wait for batches to complete before moving the data edition to a closed state. Loads submitted after the data edition is closed will fail as the closed data edition is read only.
When moving a data edition to a Maintenance status, the currently processed batches continue until completion. Loads submitted after the data edition is moved to Maintenance will fail. They can be kept open and submitted later, when the data edition is restored to an open status.
Moving a Data Edition to Maintenance Mode
To set a data edition status to maintenance mode:
-
In the Data Editions view, expand the data location node.
-
Expand the Data Branches > RootBranch node.
-
Right-click the latest data edition (open) and select Set Data Edition Status to Maintenance.
-
Click OK in the confirm dialog.
The data edition is moved to Maintenance mode.
To set a data edition status to open mode:
-
In the Data Editions view, expand the data location node.
-
Expand the Data Branches > RootBranch node.
-
Right-click the latest data edition (open) and select Set Data Edition Status Back to Open.
The data edition is moved to an open state.
Using the Maintenance Mode
The Maintenance status can be used to perform maintenance tasks on the
data edition.
For example, if you want to close the data edition and open a new data
edition on a new model edition with data structure changes that mandate
manual DML commands to be issued on the hub tables, you may perform the
following sequence:
-
Move the data edition to Maintenance mode.
-
Let the currently running batches complete. No batch can be submitted to this edition.
-
Close and open a new data edition, using the updated model edition.
-
Move the new data open edition to a Maintenance mode.
-
Perform your DML commands.
-
Move the data edition from Maintenance to the Open status. Batches can now be submitted to this edition.
Using this sequence, you prevent batches be submitted while the hub is in Maintenance.
Maintenance status is also mandatory when switching a data edition to a different deployed model edition.
Securing Data
Securing Data Access
This section describes how to define the access policies for the data
model. They are implemented in the form of model and entity
privileges.
They are enforced when the user accesses the data through the graphical
user interface, web services and API entry points.
Introduction to Security in Stambia MDM
There are two levels of security in Stambia MDM:
-
Platform-Level Security defines access to features in the platform. This type of security is covered in the Stambia MDM Administration Guide.
-
Model Level Security defines security privileges to access and modify data in the data editions.
Both levels of security are role-based:
-
Privileges are granted to Roles defined in Stambia MDM. These roles map roles defined at the application server level.
-
Roles are given to Users defined in the application server.
-
Stambia MDM does not store users and roles associations. These are provided by the application server which delegate users and roles management to a security provider (SSO, LDAP, etc.)
For more information about role creation and management, refer to the Stambia MDM Administration Guide.
Model Privileges Grants
Model Privileges Grants define the access privileges for users via
their roles.
A Model Privilege Grant is associated to a role and contains a set of
Entity Privileges granted to this role. You can only define a single
Privilege Grant for each role in a model.
Entity Privileges
An Entity Privilege defines the privilege of a role for an entity (or a subset of the entity records) and its attribute.
Entity-Level and Attribute-Level Privileges
An Entity Privileges includes privileges defined at:
-
Entity-level: Such a privilege is the default privilege for all the attributes of the entity.
-
Attribute-level: Such a privilege overrides the default entity-level privilege, allowing specific privileges per attribute.
Examples:
-
Entity-Level Privileges: Users with the Finance role can edit (read/write) cost centers; other users can only see them (read). Users with the Contractor role cannot see (none) this entity.
-
Attribute-Level Privileges: All users can see (read) general information from the employee entity, but they cannot see (none) sensitive information (Personal Email, SSID, Salary, etc. attributes). Only users with the HR role can see these attributes.
Privileges Types
The types of privilege are listed in the table below:
| Privilege Type | Entity-Level | Attribute-Level | Description |
|---|---|---|---|
None |
Yes |
Yes |
No privilege is granted to the user for the entity or attribute. |
Read |
Yes |
Yes |
Allows the user to view the entity or attribute. |
Read/Write |
Yes |
Yes |
Allows the user to view the entity or attribute. In addition, the user can edit the values in data entry workflows. Note that this privilege only allows modifying data. To create new records in a data entry workflow, the Creation privilege is needed. |
Allow Export |
Yes |
N/A |
Allows the user to mass-export records from this entity in Excel format. Note that exported columns are filtered using the privileges granted on attributes. If a user can Export an entity, but does not have read or read/write privileges on certain attributes, these attributes will not appear in the export. |
Allow Creation |
Yes |
N/A |
Allows the user to create new records and remove records for this entity in workflows. |
Allow Checkout |
Yes |
N/A |
Allows the user to checkout records for this entity in workflows. |
| If a user has read or read/write privileges on an attribute and this attribute is used in a display name, the entire display name becomes visible to the user, including those of the attributes for which the user has no privileges. It is recommended to avoid using sensitive attributes as part of a display name. |
| If a user has read or read/write privileges on one attribute of an entity, then he also has read privileges to see the built-in attributes managed by the platform (for example: publisher, update date, etc.). |
|
Checking out a record for a fuzzy matching entity may create a copy of an existing record. This copy would typically match the checked out records and consolidate with them, possibly updating the existing golden record. If this copy is modified in a way that prevents it from matching existing master records, it may then create a new golden record. When allowing users to Checkout and Write records in data entry workflows, administrators should take this into account, as both these privileges may result into record Creation. In that context, administrators may want to prevent - with attribute-level privileges - users from modifying the attributes that partipate to the matcher for the entity. |
Privilege Precedence
Privileges apply in order of precedence: Read/Write then Read then None. As a consequence, a user always has the best privileges associated to his roles
For example: John has several roles given to him:
-
Finance has Read privileges on the Customer entity.
-
HR has None privileges on the Customer entity.
-
Sales has Read/Write and Creation privileges on the Customer entity.
The resulting privilege for John is Read/Write and Creation on the Customer entity.
| Make sure to take into account all the roles of a user when reviewing his privileges. Any given role may grant this user additionnal privileges. |
Row-Level Filtering
Entity privileges support Row-Level Filtering, to apply privileges only to a subset of the records of the entity. The subsets are defined using SemQL filters.
To define different privileges for different subsets of records in the same entity, it is possible to create several entity privileges for the same entity. Each privilege will address a subset of the records, defined by a Filter.
Row-level security filters can use Model Variables to customize the data access privileges for the connected user’s session.
For example, the Privilege Grant for the GenericUser role contains:
-
A first Entity Privilege allowing Read access to the employee entity.
-
A second privilege grant for the same employee entity, allowing Read/Write for certain attributes. This second privilege grant contains the following SemQL filter:
employeeName=:V_USERNAME.
Both these grants apply to the same employee entity and the same GenericUser role. The second one only applies to the filtered subset of records in this entity passing this filter. This subset corresponds to connected user’s employee record.
| Row-Level Filtering is not supported for duplicate management workflows. A user who performs duplicate management operations for an entity must be granted privileges on all the records of the entity. Read privilege is required on all records to view the contents of a duplicate management workflow, and write privilege is required to manipulate duplicates in the workflow. |
Built-in Roles
The following roles are built in the platform:
-
semarchyConnect: This role must be granted for a user to log in. It should be granted by default to all users connecting to Stambia MDM. This role is hardcoded and cannot be modified or used in the model.
-
semarchyAdmin : This role has full access to all the features of the platform. This role is hardcoded and cannot be modified? It can be used in the model, for example in workflows or privilege grants.
| When a creating a new model, a model-level privilege grant is automatically created for the semarchyAdmin role with Grant full access to the model selected. By modifying this privilege grant, the model designer can reduce the privileges of the semarchyAdmin role on the data, and prevent platform administrators from accessing data in the hub. |
How are Privileges Applied?
The Stambia MDM Workbench Data Management user interface layout and actions are automatically modified depending on the user privileges:
-
Entities/Attributes/Records with no read privilege do not appear.
-
Entities/Attributes/Records with no read/write privilege cannot be modified in workflows.
-
Records cannot be added or removed in workflows without the creation privileges.
-
Exporting Data (Excel) is not possible without the export privilege.
The same rules applies when accessing data through Web Services. To access or manipulate data via web services, the Grant access to integration web services must also be selected.
Setting up Model Privileges
| In this section, we assume that roles and users are already defined at the application server level, and that Roles are already defined in Stambia MDM by the administrator. For more information about role creation and management, refer to the Stambia MDM Administration Guide. |
To add a model privilege grant:
-
Connect to an open model edition.
-
In the Model Edition view, right-click the Model Privilege Grants node and select Add Model Privilege Grant…. The Create New Model Privilege Grant wizard opens.
-
In the Create New Model Privilege Grant wizard, check the Auto Fill option and then enter the following values:
-
Role Name: Select a role defined in Stambia MDM by the administrator.
-
Name: Internal name of the object.
-
Label: User-friendly label for this object. Note that as the Auto Fill box is checked, the Label is automatically filled in. Modifying this label is optional.
-
In the Description field, optionally enter a description for the Model Privilege Grant.
-
Check the Grant full access to the model option if you want to give full privileges to this model. Checking this box overrides all privileges granted at the entity or attribute level.
-
Check the Grant access to integration web services option to allow this role to connect to the web service interface for this model. Note that entity/attribute level privileges are also needed. This option only allows connecting to the web service interface.
-
-
Click Next.
-
In the Entities Privileges Grants page, select the Entities for which you want grant privileges and click the Add >> button to add them to the Selected Entities.
-
Click Next.
-
In the next page, select the default privileges for the selected entities:
-
Default Access Type: Select None, Read or Read/Write
-
Allow Creation: Select this option to allow this role to create new entity records or remove entity records from a workflow.
-
Allow Checkout: Select this option to allow this role to checkout entity records into a workflow.
-
Allow Export: Select this option to allow this role to export entity records.
-
Allow Removal: This option is unused..
-
-
Click Finish to close the wizard. The Model Privilege Grant editor opens.
-
Press CTRL+S to save the editor.
In the Model Privilege Grant editor, you can refine the default privileges in the Entity Privileges table:
-
You can modify the Access Type for each entity.
-
You can expand the entities and modify the Access Type for specific attributes.
-
You can change the Creation, Checkout, Removal and Export privileges on entities.
-
You can add privilege grants for more entities, or new privilege grants for entities already present in the grant.
-
You can set a filter for each privilege grant to enable row-level security.
| Be cautious when checking the Grant full access to the model option in a privilege grant, as it overrides all privileges granted at the entity or attribute level. |
Reviewing the Privileges
It is recommended to review the privileges of the users before releasing a model.
To test the security for a given user:
-
Login to the Stambia MDM Workbench using this user’s credentials.
-
Connect to the Data Edition (optionally using an application).
-
In the workbench toolbar, select the user name in the upper right corner and then select User Information.
The platform, entity-level and attribute-level privileges for the connected user, computed from his various roles, are listed in the user information window.
Defining Data Retention
This section describes how to define the retention policies for historical and lineage data.
Introduction to Data Retention
The MDM hub stores the lineage of the certified golden data, as well as
the changes that led to this golden data.
The lineage traces the whole certification process from the golden data
back to the sources. The history traces the source data changes pushed
in the hub - through external loads - or performed into the hub -
through workflows.
Preserving the lineage and history is a master data governance requirement. It is key in a regulatory compliance focus. However, keeping this information may also create a large volume of data in the hub storage.
To keep a reasonable volume of information, administrators will want to schedule Purges for this data. To make sure lineage and history are preserved according to the data governance and compliance requirements, model designers will want to define Data Retention Policy for the model.
Data Retention Policies
Data Retention Polices are defined with:
-
A Model Retention Policy, defining the retention duration for history and lineage data in the hub. This policy applies to all entities with no specific policy.
-
Entity Retention Policies that override the model retention policies for specific entities.
For example:
-
The hub is configured to retain no history at all. This is the general policy.
-
Employee data is retained for 10 years.
-
Product and Financial data is retained forever.
Data Purge
Depending on the retention policy that is defined for the model, data purges take place in the deployed hub.
The purges delete the following elements of the lineage and history:
-
Source data pushed in the hub via external loads
-
Data authored or modified in data entry workflows
-
Errors detected on the source data by the integration job
-
Errors detected on the candidate golden records by the integration job
-
Duplicate choices made in duplicate management workflows. The duplicate management decision still applies, but the time of the decision and the decision maker information are deleted.
Optionally, the job logs can also be deleted as part of the purge process.
| The purges only impact the history and lineage for all data editions. They do not delete golden and master data for the currently open and for previously closed data editions. |
Purges are scheduled by the hub administrator. For more information, refer to the Stambia MDM Administration Guide.
| Regardless of the frequency of the purges scheduled by the administrator, the data history retained is as defined by the model designer in the data retention policies. |
Defining the Data Retention Policies
The model retention policy applies to all the entities with no specific retention policy.
To define the model data retention policy:
-
Connect to an open model edition.
-
In the Model Edition view, double-click the Retention Policies node. The Data Retention Policy editor opens.
-
In the Data Retention Policy editor, set the Default Retention Policy for the model:
-
Retention Period: Select the default retention type: Forever, No Retention or Period.
-
If you have selected Period, set a Time Unit and Time Duration for the retention period.
-
In the Description field, optionally enter a description for the retention policy.
-
-
Press CTRL+S to save the editor.
In addition to the model retention policy, you can also define in this editor the entity-specific retention policies.
To define an entity retention policy:
-
In the Data Retention Policy editor, click the Add Entity Retention Policy. The Create New Entity Retention Policy wizard opens.
-
In the Create New Entity Retention Policy wizard:
-
Select in the Entity field the entity for which you want to define a specific policy.
-
Retention Period: Select the retention type: Forever, No Retention or Period.
-
If you have selected Period, set a Time Unit and Time Duration for the retention period.
-
In the Description field, optionally enter a description for the entity retention policy.
-
-
Click Finish to close the wizard.
-
Press CTRL+S to save the editor.
| You can only have one entity retention policy per entity of the model. |
| The retention policy has no effect unless the administrator of the hub schedules purge jobs for the data location. For more information, refer to the Stambia MDM Administration Guide. |
Working with Stambia MDM Pulse Metrics
Introduction to Pulse Metrics
After designing the MDM Model and deploying it in a Stambia MDM Hub, it is necessary to perform measurements on the data within the hub. Pulse Metrics provides this capability. It gathers historical statistics on Stambia MDM Hubs attached to a Stambia MDM instance, including:
-
Data Analysis
-
Master and golden records overview
-
Golden, master, rejected records number evolution
-
Duplicates analysis, and duplicates by source
-
Data Quality (rejects) by transaction and by source
-
Incoming batch and data entry transactions
-
-
Workflow Performance
-
Data volume
-
Task volume
-
Duration
-
Backlog
-
Using these metrics, business users and data stewards can review and monitor the status and performance of their Master Data Management hub.
Using Pulse Metrics
Pulse Metrics is installed and configured by an administrator. Refer to the Stambia MDM Installation Guide and Stambia MDM Administration Guide for more information.
When Pulse Metrics is configured, metrics are automatically collected in the Pulse Metrics Warehouse. They can be accessed:
-
In the Applications' Embedded Dashboards that appear in the Dashboard node in the application’s Home page
-
Using the Microsoft Excel Metrics Dashboards. These sample Microsoft Excel dashboards connect to the Pulse Metrics Warehouse and allow business users and data stewards to analyze the metrics.
-
Alternately, by connecting a Third-Party BI Platform to the Pulse Metrics Warehouse to create customized dashboards and visualizations
Using the Embedded Dashboards
When Stambia MDM is configured to use Pulse, the dashboards powered by Pulse are automatically available when connecting an MDM application.
| The embedded dashboards appear only if the Dashboard option is activated in the application’s Available Features. |
| The embedded dashboard display metrics for entities and workflows in the application or in the entire model depending on the Dashboard Scope configured for the application. |
To use the Stambia MDM Dashboards:
-
Connect to the Stambia MDM application.
-
In the Home page, expand the Dashboards node in the Navigate view.
-
Double-click one of the dashboards link to open it.
In each dashboard, you can:
-
Change the Detail Level of the dashboard
-
Modify the position of the slicers
-
Show or hide the Slicers, Chart and data Table.
-
Use the slicers to filter the various dimensions of the dashboard. You can select multiple values by clicking CTRL while selecting the values.
See the Pulse Metrics Dashboard Sections for more information about the available dashboards.
Using the Microsoft Excel Dashboards
The Microsoft Excel Metrics Dashboard provide a simple and convinent access to the Pulse Metrics Warehouse from Microsoft Excel.
The METRICS_DASHBOARD.xlsx dashboard file is available in the /pulse/dashboards/ folder in your installation package of Stambia MDM.
To configure a dashboard to connect Pulse:
-
If you want to use ODBC Connections to Oracle, configure the ODBC connections to the Pulse Metrics Warehouse schema.
-
Make a copy of the
METRICS_DASHBOARD.xlsxdashboard file that you want to use, and open it with Microsoft Excel. -
Enable the content and editing mode on this file.
-
Select Data > Connections. There are several workbook connections by default.
-
Open each workbook connection to connect to your Oracle instance.
-
Double-click a connection. The Connection Properties dialog opens.
-
Select the Definition tab.
-
Edit the Connection String to connect to your Oracle instance with the profiling user. Tip: You can create a new connection and copy paste its connection string there. See below some connection string examples.
-
-
Once all the connection strings are reset, the dashboard and content should be refreshed. You may force the refresh using the Data > Refresh All action.
DRIVER={Oracle in XE};SERVER=XE;UID=PULSE_USER;;DBQ=XE;DBA=W;APA=T;EXC=F;XSM=Default;FEN=T;QTO=T;FRC=10;FDL=10;LOB=T;RST=T;BTD=F;BNF=F;BAM=IfAllSuccessful;NUM=NLS;DPM=F;MTS=T;MDI=Me;CSR=F;FWC=F;FBS=60000;TLO=O;MLD=0;ODA=F;
In this example:
-
DRIVERcontains the Oracle Driver name -
SERVERis the XE server name (TNS Alias). -
UIDis the user name of the profiling user. -
DBQis the name of the instance.
DSN=ORACLE_ORA11;UID=PULSE_USER;DBQ=ORA11;DBA=W;APA=T;EXC=F;FEN=T;QTO=T;FRC=10;FDL=10;LOB=T;RST=T;BTD=F;BNF=F;BAM=IfAllSuccessful;NUM=NLS;DPM=F;MTS=T;MDI=F;CSR=F;FWC=F;FBS=64000;TLO=O;MLD=0;ODA=F;
In this example:
-
DSNcontains the name of the ODBC datasource to the Oracle schema -
UIDis the user name of the profiling user. -
DBQis the name of the instance.
Built-in Dashboards
This section describes the various dashboards available in the embedded dashboards or in the Microsoft Excel metrics dashboards.
Understanding Pulses
The Pulse Metrics Warehouse uses different beats to measure time. These beats are relevant with certain metrics, and irrelevant with others.
-
Pulse Date refers to the date when the Pulse Metrics executable has gathered information from Stambia MDM to refresh the Pulse Metrics Warehouse. This represents a regular interval of time, and depends on the execution schedule of the Pulse Metrics executable.
-
Batch Date refers to the date when a load was submitted to the hub. A batch may be caused by a data integration process loading large volumes of master data into the hub, or by a data entry workflow processed by users (usually with smaller volumes).
Pulse Metrics Dashboard Sections
The Pulse Metrics include dashboards related to the data quality and duplicates, and dashboards related to the batches and workflows.
Data Dashboards
These dashboards focus on the data volume, the duplicates and the data errors.
-
Overview (Master and Golden Data): This dashboard shows master and golden record counts by entities. This count is taken by Pulse Date and Data Edition. Use this dashboard to have an overall view of the data volumes over time.
-
Timeline (Master, Golden, Source and Rejected Records Over Time): This dashboard provides a temporal view of the master, golden and rejected records by Pulse Date. Use this dashboard to have a detailed snapshot of the data distribution (golden, master and rejects) and volume for one or more entities over a period of time.
-
Data Quality (Rejected Records by Transaction (Loads and Workflows)): This dashboard shows the number of errors detected by data quality policy and policy type. Use this dashboard for high-level analysis of the rejects.
-
Quality by Source (Rejected Records by Source Application (Loads and Workflows)): This dashboard provides number of the data quality errors, focusing on the source errors and their original publisher. Use this dashboard for detailed analysis of the source rejects.
-
Duplicates (Golden Record Per Duplicates): This dashboard provides a temporal view of the golden and duplicates within or between publishers, by Pulse Date, with their confirmation status. Use this dashboard to perform duplicates analysis over a period of time and assess the duplicate management efforts.
-
Duplicates by Source (Duplicates Detected within a Publisher): This dashboard provides a temporal view of the golden and duplicates within or between publishers, by Pulse Date, with a focus on publisher analysis. Use this dashboard to analyse duplicates in regard to their origin.
Batches & Workflows
These dashboards focus on the incoming batches and user workflows.
-
Batches (Weekly Batches and Data Entry Transactions): Weekly Batches and Data Entry Transactions. Provides a count of records by Batch Date. Use this dashboard to see the volume of data entering the hub, and the source of this data.
-
Workflows - Records Count (Workflows Performance: Weekly Records Manipulated in Data Entry Workflows): This dashboard provides the volume of records submitted, rejected of cancelled by the workflows, organized by workflow start date. Use this dashboard to analyze the performance of your workflows.
-
Workflows - Tasks (Workflows Performance: Weekly Number of Tasks Executed): This dashboard displays the number of tasks processed in the context of the workflows. It also supports workflow activity analysis per person.
-
Workflows - Backlog (Workflows Performance: Pending or Running Tasks Backlog): This dashboard shows the active workflows. Use this dashboard to keep track of the backlog.
-
Workflows - Tasks Duration (Workflows Performance: Weekly Average Tasks Duration (Hours)): This dashboard provides the time spent in the workflows by tasks and by workflow status. Use this dashboard to analyze the performance of your workflows.
Using a Third-Party BI Platform With Pulse
You can use your own BI Tool to connect and perform analysis on Stambia MDM Pulse.
The Pulse Metrics Warehouse is an Oracle schema, accessible via JDBC, ODBC or other connectivity.
Appendix A provides a Pulse Metrics Warehouse Reference to help you build
dashboards from these schemas using your Business Intelligence tools.
| Refer to the built-in dashboards in Microsoft Excel format for sample dashboards based on these schemas. |
| Make sure to access these schemas for SELECT purposes only. Do not attempt to insert or update data in these schemas. |
Appendices
Appendix A: Pulse Metrics Warehouse Reference
The Pulse Metrics Warehouse comes with two views that provide a pre-built access to the data and workflow performance measures.
V_STD_RCOUNT View
This view contains Number of Records counts, organized by several
dimensions.
It is used for Data Analysis.
Primary Key
| Column Name | Description |
|---|---|
Fact ID |
ID of the Fact (Primary Key) |
Metrics Dimension
| Column Name | Description |
|---|---|
Metric Category |
Category of the Metric: Duplicates, Golden Data, Golden Errors, Master Data, Source Errors, Source Data. |
Metric Name |
Name of the Metric. |
Metric Description |
Description of the Metric. |
The following table lists the metrics per category.
| Metric ID | Metric Category | Metric Name | Metric Description |
|---|---|---|---|
GD_COUNT |
Golden Data |
Golden records |
Golden records count at Pulse date. |
MD_COUNT |
Master Data |
Master records |
Master records count at Pulse date. |
SD_LOAD_COUNT |
Source Data |
All source records |
All source records count by load. |
SD_BATCH_COUNT |
Source Data |
Accepted source records |
Accepted source records count by batch. |
SD_BATCH_ERROR_COUNT |
Source Errors |
Rejected source records |
Rejected source records count by batch. |
SE_BATCH_COUNT |
Source Errors |
Source errors |
Source errors count by batch and constraint. |
GE_BATCH_COUNT |
Golden Errors |
Golden errors |
Golden errors count by batch and constraint. |
GD_BATCH_ERROR_COUNT |
Golden Errors |
Rejected golden records |
Rejected golden record count by batch (obtained from GE using a count(distinct golden id)). |
GD_DUPS_COUNT |
Duplicates |
Golden with duplicates |
Golden records count that have more than one master at Pulse date. |
MD_DUPS_COUNT |
Duplicates |
Master duplicates |
Master records count that are not alone contributing to a golden by pulse date. |
MD_PUB_DUPS_COUNT |
Duplicates |
Master duplicates within a publisher |
Master records count within a same publisher that are not alone contributing to a golden record by pulse date (should only apply for SDPK). |
Pulse Dimension
| Column Name | Description |
|---|---|
Pulse Date |
Execution date of the Pulse Load operation. |
Pulse Year |
Year of the Pulse Load operation. |
Pulse Month |
Month of the Pulse Load operation. |
Pulse Day |
Day of the month of the Pulse Load operation. |
Pulse Hour |
Hour in the day of the Pulse Load operation. |
Pulse Week |
Week of the year of the Pulse Load operation. |
Data Locations Dimension
| Column Name | Description |
|---|---|
Data Edition Full Name |
Full name of the Data Edition (with version numbers). |
Data Location Name |
Name of the Data Location. |
Data Branch ID |
Version number of the data branch (0) |
Data Edition ID |
Version number of the data edition. |
Data Location Label |
Label of the Data Location. |
Data Location Description |
Description of the Data Location. |
Data Location Type |
Type of the Data Location (DEV or PROD). |
Data Edition Status |
Status of the data edition (CLOSED or OPEN). |
Model Name |
Name of the model. |
Model Label |
Label of the Model. |
Model Description |
Description of the Model. |
Model Branch ID |
Version number of the model branch (0) |
Model Edition ID |
Version number of the model edition in the branch. |
Model Edition Status |
Status of the model edition (CLOSED or OPEN). |
Entities Dimension
| Column Name | Description |
|---|---|
Entity |
Name of the Entity. |
Entity Label |
Label of the Entity. |
Entity Description |
Description of the Entity. |
Physical Table Name |
Physical Table Name of the Entity. |
Entity Type |
Type of the Entity (SDPK - Fuzzy Matching - or UDPK - Exact Match-) |
PK Attribute |
Name of the Attribute used as the PK of the Entity. |
Publishers Dimension
| Column Name | Description |
|---|---|
Publisher Code |
Code of the Publisher (for Source Metrics) |
Publisher Name |
Name of the Publisher (for Source Metrics) |
Publisher Label |
Label of the Publisher (for Source Metrics) |
Publisher Description |
Description of the Publisher (for Source Metrics) |
Batches Dimension
| Column Name | Description |
|---|---|
Batch ID |
ID of the Batch. |
Batch Status |
Status of the Batch. |
Batch Created By |
Creation User for the Batch. |
Batch Created On |
Creation Date for the Batch. |
Job Type |
Type of the Job. |
Job Queue |
Queue into which the job has run. |
Job Deprecated |
Flag indicating whether a job is deprecated or not. |
Batch Year |
Year of the Batch execution. |
Batch Month |
Month of the Batch execution. |
Batch Day |
Day of the month of the Batch execution. |
Batch Hour |
Hour in the day of the Batch execution. |
Batch Week |
Week of the year of the Batch execution. |
Loads and Workflows
| Column Name | Description |
|---|---|
Load ID |
ID of the Load. |
Load Program Name |
Name of the program that submitted the load. |
Load Status |
Status of the Load (CANCELLED, FINISHED or RUNNING) |
Load Type |
Type of the Load (DATA_ENTRY - data entry workflow, DUPS_MGMT - duplicates management workflow or EXTERNAL - external loads) |
Load Created On |
Creation date of the load. |
Load Submitted On |
Submission date of the load. |
Load Label |
Label of the Load. |
Load Description |
Description of the Load. |
Load Created By |
Creation User for the Load. |
Workflow Application |
Name of the application containing the workflow. |
Workflow Name |
Name of the workflow. |
Workflow Label |
Label of the workflow. |
Workflow Start Date |
Startup date of the workflow. |
Workflow Start Hour |
Startup hour in the day of the workflow. |
Workflow Termination Date |
Termination date of the workflow. |
Workflow Status |
Status of the workflow. |
Workflow Initiator |
Name of the user who initiated the workflow. |
Workflow Submitter |
Name of the user who submitted the workflow. |
Workflow Duration (days) |
Duration of the workflow in days. |
Workflow Duration (hrs) |
Duration of the workflow in hours. |
Workflow Duration (min) |
Duration of the workflow in minutes. |
Workflow Start Year |
Startup year of the workflow. |
Workflow Start Month |
Startup month in the year of the workflow. |
Workflow Start Day |
Startup day in the month of the workflow. |
Workflow Start Week |
Startup week in the year of the workflow. |
Rejects Dimension
| Column Name | Description |
|---|---|
Error Name |
Name of the error. |
Error Type |
Type of error (CHECK, PLUG-IN, UNIQUE, FOREIGN, LOV, MANDATORY). |
Error Label |
Label of the error. |
Error Description |
Description of the error. |
Duplicate Status Dimension
| Column Name | Description |
|---|---|
Dups Conf Status Name |
Duplicate master record or golden record confirmation status. |
Dups Conf Status Description |
Description of the confirmation status. |
Measure
| Column Name | Description |
|---|---|
Number of Records |
Number of records in the metric. |
V_ACT_TASK View
This view contains Task Activity Measures, organized by several
dimensions.
It is used for Workflow Performance analysis.
Primary Key
| Column Name | Description |
|---|---|
Task ID |
ID of the Task |
Data Locations Dimension
| Column Name | Description |
|---|---|
Data Edition Full Name |
Full name of the Data Edition (with version numbers). |
Data Location Name |
Name of the Data Location. |
Data Branch ID |
Version number of the data branch (0) |
Data Edition ID |
Version number of the data edition. |
Data Location Label |
Label of the Data Location. |
Data Location Description |
Description of the Data Location. |
Data Location Type |
Type of the Data Location (DEV or PROD). |
Data Edition Status |
Status of the data edition (CLOSED or OPEN). |
Model Name |
Name of the model. |
Model Label |
Label of the Model. |
Model Description |
Description of the Model. |
Model Branch ID |
Version number of the model branch (0) |
Model Edition ID |
Version number of the model edition in the branch. |
Model Edition Status |
Status of the model edition (CLOSED or OPEN). |
Loads and Workflows
| Column Name | Description |
|---|---|
Load ID |
ID of the Load. |
Load Program Name |
Name of the program that submitted the load. |
Load Status |
Status of the Load (CANCELLED, FINISHED or RUNNING) |
Load Type |
Type of the Load (DATA_ENTRY - data entry workflow, DUPS_MGMT - duplicates management workflow or EXTERNAL - external loads) |
Load Created On |
Creation date of the load. |
Load Submitted On |
Submission date of the load. |
Load Label |
Label of the Load. |
Load Description |
Description of the Load. |
Load Created By |
Creation User for the Load. |
Workflow Application |
Name of the application containing the workflow. |
Workflow Name |
Name of the workflow. |
Workflow Label |
Label of the workflow. |
Workflow Start Date |
Startup date of the workflow. |
Workflow Start Hour |
Startup hour in the day of the workflow. |
Workflow Termination Date |
Termination date of the workflow. |
Workflow Status |
Status of the workflow. |
Workflow Initiator |
Name of the user who initiated the workflow. |
Workflow Submitter |
Name of the user who submitted the workflow. |
Workflow Duration (days) |
Duration of the workflow in days. |
Workflow Duration (hrs) |
Duration of the workflow in hours. |
Workflow Duration (min) |
Duration of the workflow in minutes. |
Workflow Start Year |
Startup year of the workflow. |
Workflow Start Month |
Startup month in the year of the workflow. |
Workflow Start Day |
Startup day in the month of the workflow. |
Workflow Start Week |
Startup week in the year of the workflow. |
Tasks Dimension
| Column Name | Description |
|---|---|
Task Name |
Name of the task in the workflow. |
Task Status |
Status of the Task (Done, Pending or Running) |
Assigned To Role |
Role to which the task is assigned to. |
Performed By |
User who has processed the task. |
Assigned On |
Date when the task was assigned to the role. |
Claimed On |
Date when the task was claimed by the user. |
Completed On |
Date when the task was completed by the user. |
Completion Comments |
Completion comments for the task. |
Is Role Notified |
Flag indicating whether a notification was sent for the task. |
Task Sequence |
Sequence of the task in the workflow. |
Next Task Name |
Name of the Next Task in the workflow. |
Assigned By |
User who has assigned the task to the role. |
Updated By |
User who has updated the task. |
Updated On |
Date when the task was updated. |
Measures
| Column Name | Description |
|---|---|
Pending Duration (days) |
Days spent by the task in pending status. |
Pending Duration (hrs) |
hours spent by the task in pending status. |
Pending Duration (min) |
minutes spent by the task in pending status. |
Total Duration (days) |
Total duration of the task in days. |
Total Duration (hrs) |
Total duration of the task in hours. |
Total Duration (min) |
Total duration of the task in minutes |
Completion Duration (days) |
Days spent by the task in running status. |
Completion Duration (hrs) |
Hours spent by the task in running status. |
Completion Duration (min) |
Minutes spent by the task in running status. |