Welcome to Stambia MDM.
This guide contains information about publishing data into an MDM hub generated by Stambia MDM and consuming data from this hub.
Preface
Audience
| If you want to learn about MDM or discover Stambia MDM, you can watch our tutorials. |
| The Stambia MDM Documentation Library, including the development, administration and installation guides is available online. |
Document Conventions
This document uses the following formatting conventions:
| Convention | Meaning |
|---|---|
boldface |
Boldface type indicates graphical user interface elements associated with an action, or a product specific term or concept. |
italic |
Italic type indicates special emphasis or placeholder variable that you need to provide. |
|
Monospace type indicates code example, text or commands that you enter. |
Other Stambia Resources
In addition to the product manuals, Stambia provides other resources available on its web site: http://www.stambia.com.
Obtaining Help
There are many ways to access the Stambia Technical Support. You can call or email our global Technical Support Center (support@stambia.com). For more information, see http://www.stambia.com.
Feedback
We welcome your comments and suggestions on the quality and usefulness
of this documentation.
If you find any error or have any suggestion for improvement, please
mail support@stambia.com and indicate the title of the documentation
along with the chapter, section, and page number, if available. Please
let us know if you want a reply.
Overview
Using this guide, you will:
-
Understand the Integration Component and Jobs of Stambia MDM.
-
Learn how to publish data into an MDM hub through an external load.
-
Learn how to consume data from an MDM hub.
-
Learn how to interact with applications and workflows programmatically.
Introduction to Integration
What is Stambia MDM?
Stambia MDM is designed to support any kind of Enterprise Master Data Management initiative. It brings an extreme flexibility for defining and implementing master data models and releasing them to production. The platform can be used as the target deployment point for all master data of your enterprise or in conjunction with existing data hubs to contribute to data transparency and quality with federated governance processes. Its powerful and intuitive environment covers all use cases for setting up a successful master data governance strategy.
Stambia MDM is based on a coherent set of features for all Master Data Management projects.
Integration Capabilities
Stambia MDM certifies golden data from source applications’ data and allows applications to consume this golden data.
Integration with Stambia MDM is performed in several ways:
-
Publishing source data in an MDM hub deployed by Stambia MDM, and have the hub certify golden records from this data. This is performed through SQL or web service interfaces.
-
Consuming golden or master data from the MDM hub through SQL queries or web services.
-
Interacting with Activities using web Services.
Integration Methods
Stambia MDM provides several integration services, including:
-
Web Services, accessible from the Stambia MDM application for SOA systems to publish and consume data as well as to interact with workflows and activities.
-
SQL Interfaces, that is a PL/SQL Package, and a set of tables stored in the Data Location Schema: Using these components, data integration and ETL products can consume and publish data in the hub in Batch.
Integration Concepts
Publishers and Consumers
In the context of integration, we refer to applications publishing source data into the hub as Publishers.
We also refer to application consuming golden data from the hub as Consumers.
These roles are not exclusive. An application can publish data into the MDM hub and consume certified golden data from the hub to update its records.
For example, a business intelligence application is typically a consumer-only as it consumes only golden records for reporting purposes. An operational application may publish its contact information to the MDM hub for certification and update its contact information with the certified golden records.
Publishers
This term refers to the original application from which the data originates, and not necessarily to the middleware tool or user-designed program actually doing the data movement. The publisher is typically an operational application such as a Customer Relationship Management (CRM), a Product Lifecycle Management (PLM) or an Enterprise Resource Planner (ERP).
A middleware tool may be an Extract-Transform-Load (ETL), Enterprise Service Bus (ESB) or any other data integration product. It may also be a user-designed program or script implemented in SQL, Java, etc. The middleware tool or user-designed program communicates with the publisher to extract data and communicates with the MDM Hub using the publishing methods described in this guide to load this data.
Consumers
Similarly to the publisher, this term refers to the applications consuming data from the hub. This consumption usually takes place via a middleware tool or a user-designed program, and uses the consumption methods described in this guide.
| For the rest of this guide, we will refer to the middleware tool or user-defined product used for publishing or consuming data as the middleware. |
Data Consumption
Data consumption is available via the web services or SQL through the tables stored in the Data Location Schema.
Various views on the data can be used for consumption, including:
-
Golden Data enriched, standardized, validated, deduplicated and certified in the hub.
-
Master Data pushed in the hub by source systems.
-
Errors raised by records pushed in the hub when violating the data quality rules defined in the model.
Data Consumption is always done on a specific Data Edition, to access either the latest, or an historized data version.
Data Publishing
Publishing Concepts
Publishing source data for certification into golden data is performed as a transaction. Such publisher transaction is called an External Load. It is a Stambia MDM transaction identified by a sequential Load ID.
An External Load represents a source data load transaction.
When an External Load is submitted with an Integration Job Name, a Batch - identified by a Batch ID - is created, and the Job starts processing the data published in this load.
A Batch represents a transaction certifying loaded data and writing in the hub the resulting golden data.
| Data publishing is always performed on the latest data edition, as previous data editions are read-only. |
| Both Loads and Batches can be reviewed from the Data Location perspective in the Stambia MDM Workbench. |
External Load Lifecycle
An external load lifecycle is described below:
-
Initialize the External Load
-
The middleware uses either the SQL Interface or Web Services to initialize an external load.
-
It receives from the platform a Load ID identifying the external load.
-
At that stage, an external load transaction is open with the platform.
-
-
Load Data
-
The middleware inserts data into the landing tables in the data location schema. This done using either the SQL Interface or the Web Services.
-
When loading data, the middleware provides both the Load ID and a Publisher Code corresponding to the publisher application.
-
-
Submit the External Load
-
The middleware uses either the SQL Interface or Web Services to submit the external load.
-
It provides the Load ID as well as the name of the Integration Job to trigger with this submission.
-
The platform creates a Batch to process the data published in this external load.
-
It receives from the platform a Batch ID identifying the batch that is processed by the platform for this external load.
-
At that stage, the external load transaction is closed.
-
The middleware can also Cancel the External Load to abort the external load instead of submitting it.
| A load is always performed on the most current data edition, which is the only open data edition of the data location. Previous data edition are closed, and cannot be modified. As a consequence, it is not possible to submit loads on these past editions. |
Batch Lifecycle
When an external load is submitted, the following operations take place:
-
The platform creates a batch and returns to the submitter the Batch ID
-
The integration batch poller picks up the batch on its schedule:
-
It creates a Job instance using the Job Definition which name is provided in the submit action.
-
It moves the job into the Queue specified in the job definition
-
-
The Execution engine processes this job in the queue.
-
When the job completes, the batch is considered finished.
Even when multiple loads take place simultaneously, the sequence into which the external loads are submitted defines the order into which the data is processed by the integration jobs and golden data certified from this source data.
Interfaces for Integration
This section describes the interfaces available for integration.
SQL Interface
This interface is available for data integration and ETL products to publish or consume data. It is composed of the INTEGRATION_LOAD PL/SQL Package and the Data Location Database Schema.
The INTEGRATION_LOAD package, stored in the repository schema, contains function to manage the External Load Lifecycle, for the purpose of publishing data in batch mode.
The Data Location Database Schema stores a set of tables that contain the hub data.
This schema contains the landing (or staging) tables used to publish data into the hub. It contains also the golden records tables and the intermediate tables handled by the integration job that create golden
records from the source records. There is a single data structure for the entire hub, and a single set of tables for each entity regardless of the model edition or data edition.
The data location schema is accessed for integration purposes to:
-
Publish data in batch mode in the landing tables.
-
Consume data from the golden data and master data tables.
The structure of the tables stored in the data location schema is detailed in the Table Structures section.
Web Services
Several web services are available for the purpose of integration:
-
The Integration Load Web Service is available at platform level. It allows loading data into the hub in a generic way in all the data editions.
-
The Data Services provide access specific to the data editions stored in the data locations attached to an application instance. These data services are generated per data edition, and their capabilities and payloads depend on the underlying deployed model edition.
The data services for each data edition include:
-
The Data Access service, named after the model, that provides read access to the various views storing golden data, master data, errors detected, etc. The structure of this service depends on the model structure.
-
The Data Edition Integration Service that allows loading data in a given open data edition of the hub.
-
The Activity Service that allows SOA applications to manage instances of workflows defined in applications.
-
The Generic Data Service that allows applications to interact (read/write) with data in the hub in a generic way. Unlike the Data Access service, this web service provides a generic (model-independent) structure.
Data Certification
This section explains the artifacts involved when certify data published into the hub.
Integration Job
The integration job processes the data submitted in an external load and runs this data through the Certification Process, which is a series of steps to create and certify golden data out of this source data.
This job is generated from the integration rules defined at design time, and it uses the data structures automatically created in the MDM hub when deploying the model edition.
| Although understanding the details of the process is not needed for publishing source data or consuming golden data, it is necessary to have complete understanding of this process to drill down into the various structures between the source and the golden data. For example, to review the rejects or the duplicates detected by the integration job for a given golden record. |
An integration job is a sequence of tasks used to certify golden data for a group of entities. Each data model edition deployed in the data location has integration several jobs definitions attached to it. Each of these job definitions is designed to certify data for a group of entities.
Integration jobs definitions as well as integration job logs are stored in the repository
For example, a multi-domain hub contains entities for the PARTY domain and for the PRODUCTS domain, and has two integration jobs definition:
-
INTEGRATE_CUSTOMERS certifies data for the Party, Location, etc… entities.
-
INTEGRATE_PRODUCTS certifies data for the Brand, Product, Part, etc… entities.
Integration jobs are started when source data has been loaded in the landing tables and is submitted for golden data certification.
Certification Process
Each integration job is the implementation of the overall certification process template. It may contain all or some of the phases of this process. The following section details the various phases of the certification process.
The following figure describes the Golden Data certification process and the various Table Structures involved in this process.
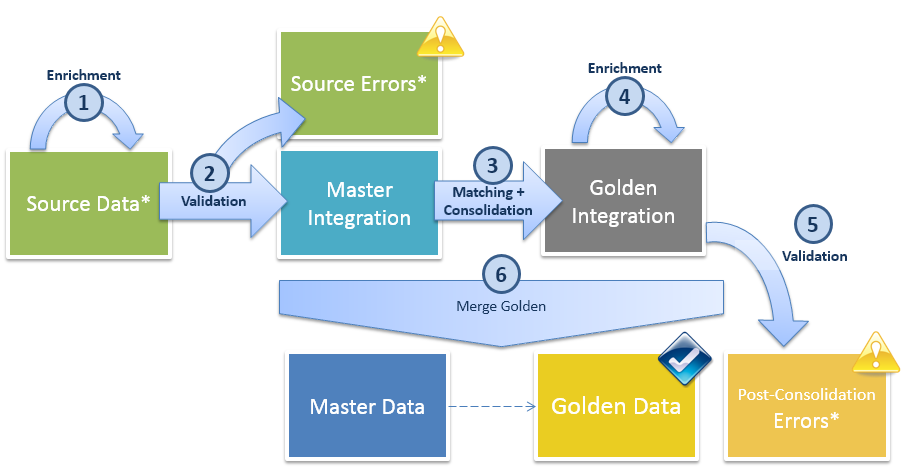
-
Enrichment: This phase of the process enriches and standardizes source data using SemQL or plug-ins. This phase updates the data in the Source Data (SD) tables.
-
Validation (Pre-Consolidation): This phase checks the enriched source data from the Source Data (SD) tables against the rules and constraints defined in the model, using SemQL or plug-ins. The records not conforming to the rules are rejected from the flow, and the errors (with the erroneous data) are tracked in a Source Error (SE) tables. Valid records are moved to the Master Integration (MI) tables.
-
Matching: This phase creates matching groups according to the SemQL matching expression. Note that this phase runs in two steps. First, a binning step creates - using the binning expression - small sets of records into which the matching - using the SemQL matching condition - takes place. This phase involves the Master Integration (MI) tables where duplicate records are flagged.
-
Consolidation: This phase creates (consolidates) a single record out of the various duplicates of a group, using the field-level or record-Level consolidation rules. This phase consolidates the data from the Master Integration (MI) tables in the Golden Integration (GI) tables.
-
Enrichment (Post-Consolidation): This phase of the process enriches and standardizes consolidated data using SemQL or plug-ins. This phase updates the data in the Golden Integration (GI) tables.
-
Validation (Post-Consolidation): This phase checks the Golden Integration (GI) - candidate golden - records against the rules and constraints defined in the model, using SemQL or plug-ins. The records not conforming to the rules are rejected from the flow, and the errors (with the erroneous data) are tracked in a Post Consolidation Error (or Golden Error - GE) tables.
-
Merge Golden: Finally, Golden Integration (GI) records as well as the Master Integration (MI) records are merged in the Golden Data (GD) and Master Data (MD) tables.
For more information about these various phase and how the certification process is designed, refer to the Integration Process Design chapter in the Stambia MDM Developer’s Guide.
Table Structures
This section describes the general structure of the tables involved in the certification process.
Tables
For each entity, a pre-defined set of tables is created. These tables are named with the following convention:
<Prefix>_<Physical Table Name>
The prefix is automatically generated depending on the table nature (Source Data, Source Error, etc.), and the Physical Table Name is set in the entity definition.
The following list describes the tables created for a given entity.
| Table | Name | Description |
|---|---|---|
|
Source Data |
This table is loaded by the middleware to publish data into the hub. |
|
Source Errors |
This table contains the errors detected during the pre-consolidation validation phase. |
|
Master Integration |
This table contains the records that have passed the pre-consolidation validation phase and that have been grouped by the matching phase. |
|
Golden Integration |
This table contains the records that have been consolidated but not yet passed through the post-consolidation validation phase. |
|
Golden Errors |
This table contents the errors detected during the post-consolidation validation phase. |
|
Master Data |
This table contains the master records, which are the enriched and validated source records that have participated in the creation of golden records. This table can be accessed to review groups/duplicates or to refer to the source data. |
|
Golden Data |
This table contains the golden records consolidated from the master records. |
For publishing and consuming data, the MI and GI tables are not needed. The structure of these tables is not explained in this document.
Columns
|
About Date Values and Time Zones Date values are stored, read and written in the time zone of the application server. When consuming dates and timestamp values, time zone conversion may be necessary if the client time zone differs from the application server time zone. Similarly, integration processes must convert dates and timestamp values in the application server’s time zone. |
Attribute Columns
Attributes appear in the tables’ structure as follows:
-
Attributes using list of values, built-in and user-defined types are mapped to single columns with a database type and length corresponding to the attribute type. The column name for such a simple attribute is the Physical Column Name value specified in the simple attribute definition.
-
Complex attributes are mapped on columns named with the following convention:
<Complex Attribute Physical Prefix><Definition Attribute Physical Column Name>
For example: The Country (COUNTRY) and City (CITY) definition
attributes of the Geocoded Address complex attribute (Prefix: GEO)
will be mapped to columns named GEOCOUNTRY and GEOCITY.
Built-in Columns
In addition to the attribute columns, built-in columns are added to the tables’ structure, and are used in the integration process.
They track for example:
-
Data Edition information:
B_BRANCHID,B_FROMEDITION,B_TOEDITION -
Batch information:
B_BATCHID -
Cause of a rejected record:
B_CONSTRAINTNAME,B_CONSTRAINTTYPE -
Class/Inheritance information:
B_CLASSNAME -
Match/Merge information:
B_MATCHGRP,B_CONFSCORE,B_HASSUGGMERGE,B_SUGGMERGEID,B_SUGGMERGECONFSCORE,B_SUGGMERGEMASTERSCOUNT,B_CONFIRMATIONSTATUS,B_MASTERSCOUNT,B_ISCONFIRMED
The following list describes these columns.
| Column Name | Datatype | Exists in Tables | Description |
|---|---|---|---|
|
|
SD |
ID of the load that created this record. |
|
|
SD, SE, MD, GD, GE |
ID of the batch that created this record. |
|
|
SD, SD, MD |
Code of the publisher that published this record. |
|
|
SD, SD, MD |
ID of the source record in the source publisher system (Fuzzy Matching entities only). See below for a detailed explanation of the primary key options. |
|
|
SD, SE, MD, GD, GE |
Data Branch containing the data edition(s) storing this record. |
|
|
SD, SE, MD, GD, GE |
Class name of this record. See below for a detailed explanation of class name and inheritance. |
|
|
SE, GE |
Name of the constraint causing this error (Error Records) |
|
|
SE, GE |
Type of the constraint causing this error (Error Records) |
|
|
MD, GD |
Edition from which the Master/Golden record exists. |
|
|
MD, GD |
Edition until which the Master/Golden record exists. If it is null, then the record exists until the latest data edition. |
|
|
MD |
ID of the match group for the master record. This column is set when matching takes place. |
|
|
GD |
Confidence score of the golden record. It is the average of the match scores in the match group. |
|
|
MD |
Exclusion group ID. An exclusion group represents a group of records for which a user has taken split decisions. |
|
|
GI,MI, MD, GD |
Flag indicating that match and merge suggestions are available for this record. |
|
|
GI,MI, MD, GD |
New group ID suggested by the automated matching for this record. |
|
|
GI, MI, GD, MD |
Confidence score for the suggested group. |
|
|
GI, MI, GD, MD |
Number of masters for the suggested group |
|
|
GD, MD |
Confirmation status for duplicate management: either confirmed, unconfirmed or historically confirmed. |
|
|
GD |
Number of master records contributing to this golden record. |
|
|
GD |
Flag indicated whether this golden record has been validated and the matching confirmed by a user (Fuzzy Matching entities only). |
|
|
SD |
Batch identifier of the record when it was originally checked out in a workflow. |
|
|
SD, SE, MD, GD, GE |
Creation date of the record. |
|
|
SD, SE, MD, GD, GE |
Last update date of the record. |
|
|
SD, SE, MD, GD, GE |
Creator of the record. |
|
|
SD, SE, MD, GD, GE |
Last updater of this record. |
Primary Keys Columns
The primary key to load depends on the type of the matching behavior of the entity:
ID Matching
When using ID Matching, we assume a common identifier across all systems. In this case, this common identifier is stored in a column named after the Physical Column Name specified in the primary key attribute definition.
This column will exist in all tables. When publishing data into the hub, the middleware loads this column with the primary key from the publishing system. This identifier is simply propagated into the hub, and matching is done using this primary key.
Fuzzy Matching
When using Fuzzy Matching, we assume no common identifier across publishers. There may be two different records with the same ID in different systems. There is a need to match the records and consolidate them under a golden record having a primary key generated by the system.
In this case, the source identifier is stored in the column named
B_SOURCEID, along with the publisher code stored in the B_PUBID.
This is the case for the SD, SE and MD tables.
When publishing data into the hub, the middleware loads this
B_SOURCEID column with a primary key value from the publishing system.
If this primary key is a composite key in the source system, all the
columns of this composite key must be concatenated into B_SOURCEID.
When the records are consolidated in a golden record (GD and GE tables), a System Defined Primary Key is generated and stored in a column named after the Physical Column Name specified in the primary key attribute definition. This key is referred to as the Golden Record ID.
The MD table makes the bridge between the Source ID and the Golden ID as it contains both these values.
Reference Columns
When a reference exists in the source publisher and need to be expressed in the landing table, this reference mapping in the table structure depends on the matching behavior of the referenced entity.
Reference to an ID Matching Entity
For a reference to an ID Matching entity, the referenced key is the
same for all systems. As a consequence, the referenced value is stored
in a single column. This column is named after the Physical Name
provided in the reference definition and is prefixed with F_. For
example, F_EMPLOYEE.
For example: if Customer references Employee and this entity uses ID
Matching, SD_CUSTOMER will contain the following information.
| CUSTOMER_NAME | F_EMPLOYEE |
|---|---|
Gadgetron |
11 |
Roxxon |
56 |
This information means that the customer Gadgetron references the
employee number 11, and Roxxon references employee number 56. This
employee number is the same in all systems.
Reference to a Fuzzy Matching Entity
For a reference to a Fuzzy Matching entity, the referenced key is per publisher.
As a consequence:
-
The referenced value is stored in a column named after the Physical Name provided in the definition of the reference and prefixed with
FS_(for Foreign Source ID). For example,FS_CUSTOMER. -
The referenced publisher is also stored, in a column named after the Physical Name provided in the definition of the reference and prefixed with
FP_(for Foreign Publisher). For example,FP_CUSTOMER.
For example: if Contact references Customer and this entity uses
Fuzzy Matching, SD_CONTACT will contain the following information.
| FIRST_NAME | LAST_NAME | FP_CUSTOMER | FS_CUSTOMER |
|---|---|---|---|
John |
Doe |
CRM |
1235 |
Jane |
Smith |
MKT |
A3251 |
This information means that the contact John Doe references the
customer with the primary key 1235 in the CRM publisher, and
that Jane Smith references the customer with the primary key
A3251 in the MKT publisher.
Class Name and Inheritance
Several entities involved in an inheritance relation have their data
stored in the same set of tables. These tables store the superset of the
attributes of the parent and all its child entities. The B_CLASSNAME
column is used to identify the class (entity) of a record in a table.
For example, when Person and Company inherit from the Party
entity, the resulting table is named after the parent entity
(Party), and will contain all the attributes of Person and
Company as well. In the GD_PARTY table for example, records
representing persons will have B_CLASSNAME='Person'. When publishing
person or company information in the SD_PARTY table, the middleware
must set B_CLASSNAME='Person' or B_CLASSNAME='Company' accordingly.
Constraints
The only constraints enforced in the tables are the primary keys and the not null columns. These constraints apply to system columns only.
For example, on an SD_ table, the following constraints are enforced:
-
primary key on
B_LOADID,B_PUBID,B_SOURCEID(or the primary key column for ID Matching entities) -
B_LOADID,B_CLASSNAME,B_BRANCHID,B_PUBIDandB_SOURCEID(or the primary key column for ID Matching entities) are not null
Other constraints defined in the model (mandatory attributes, references, etc.) are not enforced in the physical model but checked during the validation phase.
Publishing Data Using Web Services
Publishing data can be done using the Integration Web Services to initialize and submit the external load and to load the data into the hub.
Overview
In this approach, external loads are handled via the Integration Load
Web Service or the Data Edition Integration Service.
They work as follows:
-
The external load is initialized using a web service call to the
getNewLoadIDoperation. This call returns a Load ID. -
Data is loaded using the
PersistRowsInLoad(Integration Load Web Service) andPersistRecordsInLoad(Data Edition Integration Service) operations. -
The external load is submitted or cancelled using web service calls:
-
submitLoadsubmits a load identified by its Load ID. This call returns a Batch ID. -
cancelLoadcancels a load identified by its Load ID.
-
| This approach may be preferred when the middleware is an ESB product, or when the load management is part of a business process. This approach is also preferred to avoid granting database access to the repository schema. |
Integration Services
Integration Load Web Service
The Integration Load Web Service provides platform-level control points for external loads. Integrators may use this service to manage the loads.
The Integration Load Web Service is accessed at the following URL:
http://<host>:<port>/<application>/ws/<ws_version>/platform/IntegrationLoadService?wsdl
This web service provides the following bindings:
| Binding Name | Description |
|---|---|
getNewLoadID |
Initializes a new load for the open data edition, identified by a data location and a data branch ID. This service returns a load ID. |
submitLoad |
Submits a load identified by a load ID. This service returns the corresponding batch ID. |
cancelLoad |
Cancels a load identified by a load ID. |
generateNewIds |
Generates a batch of IDs for a given entity. This IDs can be used to persist new records. |
persistRowsInLoad |
Persists one or more rows in a load identified by a load ID. |
queryCountFromLoad |
Counts filtered records in a load. |
queryRowsFromLoad |
Returns a list of rows stored in a load. |
Data Edition Integration Service
The Data Edition Integration Service provides data edition-level control points for external
loads. Integrators may use this service to manage the loads.
The Data Edition Integration Service is accessed at the following URL:
http://<host>:<port>/<application>/ws/<ws_version>/data/<data_location>/<data_branch>.<data_edition>/DataEditionIntegrationService?wsdl
This web service provides the following bindings:
| Binding Name | Description |
|---|---|
getNewLoadID |
Initializes a new load for the current data edition. This service returns a load ID. |
submitLoad |
Submits a load identified by a load ID. This service returns the corresponding batch ID. |
cancelLoad |
Cancels a load identified by a load ID. |
generateNew<entity_name>Ids |
Generates a batch of IDs for a given entity. This IDs can be used to persist new records. |
get<entity_name>ListFromLoad |
Returns a list of records published in an external load for the entity identified by <entity_name>. |
persistRecordsInLoad |
Persists one or more records for one or more entities in a load identified by a load ID. |
loadAndSubmitRecords |
Performs the equivalent of a getNewLoadID, persistRecordsInLoad then a submitLoad. |
Platform-Level vs. Data Edition-Level Service
The platform-level Integration Load Web Service and the Data Edition Integration Service provide similar capabilities to publish data into the hub:
-
The Integration Load Web Service provides these capabilities at platform-level, with generic requests (not dependent on the model structure), it but requires to explicitly specify which data edition you connect to.
-
The Data Edition Integration Service, located at the data edition level, does not requires setting the data edition and provides specific requests that mimic to the structure of the model.
Integration Services Additional Capabilities
No user name required in the web service requests since the Web Service will use the credentials of the connected user (WS_Security).
Accessing the web services require WS-Security authentication with a user having a model privilege granted to one of his role with the Grant access to integration web services option selected.
Both the Integration Load Web Service and Data Edition Integration Service provide operations
that chain the getNewLoadID, data load and submitLoad in a single web service call. These operations
are called loadAndSubmitRows and loadAndSubmitRecords. Using these operations allows publishing records into
the hub without having to manage or store the Load ID.
Both these web services also expose operations to query the records stored in an external load.
These operation are called queryCountFromLoad and queryRowsFromLoad for the Integration Load Web Service, and get<entity_name>ListFromLoad for the Data Edition Integration Service.
Initializing a Load
The following web service sample calls the platform-level getNewLoadID operation (Integration Load Web Service) to initialize an external load and return a Load ID.
<soapenv:Envelope .../>
<soapenv:Header/>
<soapenv:Body>
<ws:getNewLoadID>
<dataLocationName><!-- data_location_name --></dataLocationName>
<dataBranchID><!-- branch_id --></dataBranchID>
<programName><!-- program_name --></programName>
<loadDescription><!-- load_description --></loadDescription>
</ws:getNewLoadID>
</soapenv:Body>
</soapenv:Envelope><soapenv:Envelope .../>
<soapenv:Header/>
<soapenv:Body>
<int:getNewLoadID>
<dataLocationName>CustomerMDMHub</dataLocationName>
<dataBranchID>0</dataBranchID>
<programName>Custom ETL</programName>
<loadDescription>Initial Load for the Hub</loadDescription>
</int:getNewLoadID>
</soapenv:Body>
</soapenv:Envelope><soap:Envelope .../>
<soap:Body>
<ns1:getNewLoadIDResponse ...>
<return>141</return>
</ns1:getNewLoadIDResponse>
</soap:Body>
</soap:Envelope>The same call performed on the data edition-level web service does not require the dataLocationName and dataBranchID parameters, as the call is made on the data edition.
<soapenv:Envelope .../>
<soapenv:Header/>
<soapenv:Body>
<ns:getNewLoadId>
<programName><!-- program_name --></programName>
<loadDescription><!-- load_description --></loadDescription>
</ns:getNewLoadId>
</soapenv:Body>
</soapenv:Envelope>Loading Data
Loading Data is done either with the persistRowsInLoad operation (Integration Load Web Service) or with the persistRecordsInLoad operation (Data Edition Integration Service).
| Both these operations support updating existing records. If using an existing Publisher and an existing Record ID, the loaded record is considered an update of the existing record. |
Loading Data with the Integration Load Web Service
This service exposes a generic interface to persist one or more Entities Rows.
The request exposes the Load ID and a Default Publisher ID (used for all submitted rows), then a sequence of Entities Rows.
Each Entity Row is composed of an Entity Name and one or more Values passed within a tag corresponding to their data type.
PersistRowsInLoad to load a generic data row<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:int="http://www.semarchy.com/xml/ws/1.3/platform/IntegrationLoadService">
<soapenv:Header/>
<soapenv:Body>
<int:persistRowsInLoad>
<loadId><!-- load_id --></loadId>
<payload>
<defaultPublisherId><!-- publisher_code --></defaultPublisherId>
<!--1 or more repetitions:-->
<entityRows>
<entityName><!-- entity_name --></entityName>
<!--1 or more repetitions:-->
<dataRowsToPersist>
<!--Zero or more repetitions:-->
<Value name="?">
<!-- Select and fill one of the datatype tag -->
<binary>cid:88734163910</binary>
<boolean>?</boolean>
...
<!-- All model datatypes are supported here -->
...
<string>?</string>
<uuid>?</uuid>
</Value>
</dataRowsToPersist>
</entityRows>
</payload>
<generateIds>true</generateIds>
</int:persistRowsInLoad>
</soapenv:Body>
</soapenv:Envelope>The following example persists two Customer row and a Contact row, using the CRM Publisher.
PersistRowsInLoad to load two Customers and one Contact.<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:int="http://www.semarchy.com/xml/ws/1.3/platform/IntegrationLoadService">
<soapenv:Header/>
<soapenv:Body>
<int:persistRowsInLoad>
<loadId>550</loadId>
<payload>
<defaultPublisherId>CRM</defaultPublisherId>
<entityRows>
<entityName>Customer</entityName>
<dataRowsToPersist>
<Value name="SourceID"><string>1260</string></Value>
<Value name="CustomerName"><string>Sambalele</string></Value>
</dataRowsToPersist>
</entityRows>
<entityRows>
<entityName>Customer</entityName>
<dataRowsToPersist>
<Value name="SourceID"><string>1261</string></Value>
<Value name="CustomerName"><string>ACME Corp.</string></Value>
</dataRowsToPersist>
</entityRows>
<entityRows>
<entityName>Contact</entityName>
<dataRowsToPersist>
<Value name="SourceID"><string>1261.1</string></Value>
<Value name="FirstName"><string>Bugs</string></Value>
<Value name="LastName"><string>Bunny</string></Value>
<Value name="SourceID_Customer"><string>1261</string></Value>
<Value name="PublisherID_Customer"><string>CRM</string></Value>
</dataRowsToPersist>
</entityRows>
</payload>
<generateIds>false</generateIds>
</int:persistRowsInLoad>
</soapenv:Body>
</soapenv:Envelope>The response of this request contains the IDs of the persisted records, in the same order as the records created.
PersistRowsInLoad call<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/">
<SOAP-ENV:Header xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/"/>
<soap:Body>
<ns2:persistRowsInLoadResponse xmlns:ns2="http://www.semarchy.com/xml/ws/1.3/platform/IntegrationLoadService">
<rows>
<rowId>
<string>1260</string>
</rowId>
<rowId>
<string>1261</string>
</rowId>
<rowId>
<string>1261.1</string>
</rowId>
</rows>
</ns2:persistRowsInLoadResponse>
</soap:Body>
</soap:Envelope>Loading Data with the Data Edition Integration Service
This service exposes a model-specific interface to load data for the different entities of the model.
The request exposes the Load ID and a Default Publisher ID (used for all submitted rows), then a sequence of records specific for the entities. Each record is structured according to the entity definition.
persistRecordsInLoad for the CustomerAndFinancialMDM demo hub.<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:ns="http://www.semarchy.com/xml/ws/1.0/data/CustomerAndFinancialMDM/0.0">
<soapenv:Header/>
<soapenv:Body>
<ns:persistRecordsInLoad>
<loadId>?</loadId>
<payload>
<defaultPublisherId>?</defaultPublisherId>
<!-- You have a CHOICE of the next 4 items at this level-->
<!-- Repeat to create more than one record -->
<Contact>
<PublisherID>?</PublisherID>
<SourceID>?</SourceID>
<FirstName>?</FirstName>
<LastName>?</LastName>
...
<!-- Other attributes for Contact here -->
...
<PublisherID_Customer>?</PublisherID_Customer>
<SourceID_Customer>?</SourceID_Customer>
</Contact>
<CostCenter>
....
<!-- Other attributes for CostCenter here -->
...
</CostCenter>
<Customer>
<PublisherID>?</PublisherID>
<SourceID>?</SourceID>
<CustomerName>?</CustomerName>
<TotalRevenue>?</TotalRevenue>
<InputAddress>
<Address>?</Address>
<PostalCode>?</PostalCode>
<City>?</City>
<Country>?</Country>
</InputAddress>
<GeocodedAddress>
<StreetNum>?</StreetNum>
<Street>?</Street>
<!-- Other fields from the GeocodedAddress complex type below -->
...
<Quality>?</Quality>
</GeocodedAddress>
<FID_AccountManager>?</FID_AccountManager>
</Customer>
<Employee>
...
<!-- Other attributes for Employee here -->
...
</Employee>
</payload>
</ns:persistRecordsInLoad>
</soapenv:Body>
</soapenv:Envelope>Managing IDs
When persisting data, the provided ID defines whether a record creation or a record update operation is performed in the load:
-
For example, persisting a record that already exists in a load (that is with the same Entity, Publisher, and Source ID) consists in updating the record in the load.
-
If the ID does not exist yet in the load, then a new source record is created into the load.
Note that source a record in the load may have already been pushed in the hub, and is an existing master record. In that case the new source record pushed in this load will update this master record and eventually modify its parent golden record during the certification process, after the load is submitted.
To create new records unrelated to existing records from the hub, it is possible to have the web service generate fresh IDs. To do so, you can either:
-
Pass your request with no Source ID, and set the optional
generateIdselement of the request totrue. If the entity does not use a Manual ID generation method, the IDs are automatically generated for records with no IDs specified, and returned in the response. -
Provision a series of IDs for a given entity, using the
generateNewIdsorgenerateNew<entityName>Idsweb service, and then use these IDs in subsequent requests. This method can be used to avoid round trips when creating interrelated records.
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:int="http://www.semarchy.com/xml/ws/1.3/platform/IntegrationLoadService">
<soapenv:Header/>
<soapenv:Body>
<int:persistRowsInLoad>
<loadId>550</loadId>
<payload>
<defaultPublisherId>CRM</defaultPublisherId>
<entityRows>
<!-- No ID provided here ... -->
<entityName>Customer</entityName>
<dataRowsToPersist>
<Value name="CustomerName"><string>Goliath Corp</string></Value>
</dataRowsToPersist>
</entityRows>
</payload>
<!-- ... but IDs will be generated -->
<generateIds>true</generateIds>
</int:persistRowsInLoad>
</soapenv:Body>
</soapenv:Envelope><soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/">
<SOAP-ENV:Header xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/"/>
<soap:Body>
<ns2:persistRowsInLoadResponse xmlns:ns2="http://www.semarchy.com/xml/ws/1.3/platform/IntegrationLoadService">
<rows>
<rowId>
<string>c09bea6e-f16f-4e62-b69f-aea31bcfa5b6</string>
</rowId>
</rows>
</ns2:persistRowsInLoadResponse>
</soap:Body>
</soap:Envelope>Submitting a Load
This web service sample call on the submitLoad operation submits an
external load identified by its Load ID and returns a Batch ID in the
response.
<soapenv:Envelope ...>
<soapenv:Header/>
<soapenv:Body>
<ws:submitLoad>
<loadID><!-- load_id --></loadID>
<jobName><!-- integration_job --></jobName>
</ws:submitLoad>
</soapenv:Body>
</soapenv:Envelope>INTEGRATE_DATA job.<soapenv:Envelope .../>
<soapenv:Body>
<int:submitLoad>
<loadID>125</loadID>
<jobName>INTEGRATE_DATA</jobName>
</int:submitLoad>
</soapenv:Body>
</soapenv:Envelope><soap:Envelope .../>
<soap:Body>
<ns1:submitLoadResponse ...>
<return>456</return>
</ns1:submitLoadResponse>
</soap:Body>
</soap:Envelope>| You can only submit loads from the authenticated user. |
Canceling a Load
This web service sample call on the cancelLoad operation cancels a load identified by its Load ID.
<soapenv:Envelope ...>
<soapenv:Header/>
<soapenv:Body>
<ws:cancelLoad>
<loadID><!-- load_id --></loadID>
</ws:cancelLoad>
</soapenv:Body>
</soapenv:Envelope>| You can only cancel loads from the authenticated user. |
<soapenv:Envelope .../>
<soapenv:Body>
<int:cancelLoad>
<loadID>125</loadID>
</int:cancelLoad>
</soapenv:Body></soapenv:Envelope>Publishing Data Using SQL
Publishing data can be done using PL/SQL to initialize and submit the external load and SQL load the data in the landing (source date - SD) tables.
Overview
In this approach, external loads are handled via PL/SQL and SQL interface. It works as follows:
-
The external load is initialized using a PL/SQL call to the
INTEGRATION_LOAD.GET_NEW_LOADIDfunction on the repository schema. This function call returns a Load ID. -
SD tables are loaded using SQL inserts issued on the data location schema.
-
The external load is submitted or cancelled using PL/SQL function calls on the repository schema:
-
INTEGRATION_LOAD.SUBMIT_LOADto submit a load identified by its Load ID. This function call returns a Batch ID. -
INTEGRATION_LOAD.CANCEL_LOADto cancel a load identified by its Load ID.
-
| This approach is recommended when the middleware is an ETL or data integration product. |
Initializing a Load
Initializing an external load uses the following parameters:
-
data_location_name: name of the data location. This data location is the one hosting the MDM hub into which the external load is performed. -
branch_id: ID of the data edition branch. It should be set to 0 (zero). Note that the ID of the data edition is not required. By default, the external load is initialized on open (latest data edition). -
program_name: This variable is for information only. It is used to identify the middleware performing the external load. For example ’ETL Custom Script’. -
load_description: This variable is for information only. It is used to describe the nature of this load. For example: ’Daily updates for Customers and Contacts’. -
user_name: name of the user initializing the external load. This user may or may not be a user defined in the security realm of the application server.
This function call to INTEGRATION_LOAD.GET_NEW_LOADID initializes an
external load and returns a Load ID. It is performed on the repository
database schema.
vLoad_id := <repository_schema>.INTEGRATION_LOAD.GET_NEW_LOADID(
'<data_location_name>' /* Data Location Name (As in the UI) */
<branch_id> /* Branch ID (0, 1, ...) */
'<program_name>' /* Informational. Identifies the Middleware*/
'<load_description>' /* Informational. Describes the load. */
'<user_name>' /* User initializing the load. */
);The following example performs a function call initializing an external
load on the CustomerMDMHub data location, on the latest data edition
of the data branch 0. The repository schema is REPO. The returned
Load ID is stored in the vLoad_id variable.
vLoad_id := REPO.INTEGRATION_LOAD.GET_NEW_LOADID(
'CustomerMDMHub',
0,
'Custom ETL',
'Initial Load for the Hub',
'John Doe' );Loading Data
Loading data consists in inserting new source records in the SD tables for the set of entities taken into account in the integration job.
When loading data in the SD tables:
-
You use SQL insert commands or your regular ETL/Data Integration Platform.
-
The insert commands are issued on the SD tables stored in the data location schema.
SD Tables to Load
Make sure to all the load tables that will be taken into account in the
integration job. For example, if the integration job processes the
Customer and Contact entities, then you should load the
SD_CUSTOMER and SD_CONTACT tables.
If you insert data into the SD table of an entity that is not taken into
account by the integration job, this data will be ignored. For example,
if the integration job processes the Customer and Contact entities,
data loaded the SD_EMPLOYEE table will not be taken into account by
the integration job to certify golden records for the Employee entity.
Referential Integrity and Load Order
There is no required order to load the SD_ tables, as no foreign keys
are implemented on the SD tables.
Reference validation is performed by the integration job, as a
consequence references between entities must be loaded as indicated in
the SD Columns to Load section.
Using Transactions
It is recommended to use a database transaction when writing to the SD
tables just before submitting the load.
Canceling an external load - using the INTEGRATION_LOAD.CANCEL_LOAD()
function - cancels the load but
does not delete records from the SD tables. Writing for example in an
auto-commit transaction in the SD tables then canceling the load will
leave useless information in the SD tables.
Using a transaction gives the capability to rollback all changes on the
SD_ tables when canceling a load.
SD Columns to Load
This section provides some guidance for loading the columns of the SD tables.
System Columns (Mandatory)
The following system columns must be loaded as indicated:
-
B_LOADID: This column must be loaded with the Load ID provided byINTEGRATION_LOAD.GET_NEW_LOADID()orgetNewLoadID()call. -
B_BRANCHID: This column must be loaded with the ID of the data branch into which data is loaded. This value is usually0(zero). -
B_CLASSNAME: Name of the entity (or class) being loaded. When inheritance is used, the same SD table stores data for all parent and child classes. Set explicitlyB_CLASSNAMEto the name of the entity for which data is being published. For example:Person,Party,Company. See the Class Name and Inheritance section for more details. -
B_PUBID: This column must be loaded with a Publisher Code. For example:CRM,MKT, etc. This publisher code identifies the publisher (application that publishes the data) and should be declared in the model edition. The list of publisher codes is available by double-clicking the Publishers node in the Model Edition view in the Model Design perspective. If the publisher code is unknown to the model, data from this publisher is processed, but this publisher will have the lowest ranking in a Preferred Publisher consolidation strategy.
Publisher codes are case sensitive. Make sure to load B_PUBID with the publisher code as defined in the model. Publisher codes man contain uppercase letters, digits and underscores.
|
Within a single load, you can load the records from various publishers, using the B_PUBID column to identify each publisher
|
Primary Keys (Mandatory)
The primary key that you load in the SD table allows identifying the
source record from the source system - identified by Publisher Code in
B_PUDIB.
The primary key column to load depends on the Matching Behavior of the entity.
ID Matching Entity
If the entity uses ID Matching, then this ID must be loaded in the column representing the attribute defined as the primary key attribute for the entity.
Fuzzy Matching Entity
If the entity uses Fuzzy Matching, then you must load in the
B_SOURCEID column the value of the primary key from the source system.
If this primary key is a composite key, then you must concatenate the
values of the composite primary key and load them in the B_SOURCEID
column.
The B_SOURCEID column is a VARCHAR(128) column. Make sure
to perform the appropriate conversions for loading this column.
|
References (Mandatory)
When loading data for entities that are related by a reference relationship, you must load the referencing entity with the value of the referenced primary key. The columns to load differ depending on the matching behavior the referenced entity.
Reference to an ID Matching Entity
If the referenced entity is an ID Matching entity, then you need to load
the column representing the referencing attribute. This column is
F_<Physical Name of the Reference To Role Name>.
For example, if Customer references Employee and this entity uses ID
Matching, then you must load in SD_CUSTOMER the F_EMPLOYEE column
with the primary key of the source employee record referenced by each
customer record.
Reference to a Fuzzy Matching Entity
If the referenced entity is a Fuzzy Matching entity, then you need to load two columns:
-
FS_<Physical Name of the Referenced To Role Name>: Load this column with the Source ID of the referenced record. -
FP_<Physical Name of the Referenced To Role Name>: Code of the publisher of the referenced record.
Note that these columns should be considered together. You
should not load the FP_ column with a publisher code and leave FS_
to a null value, and vice versa.
|
For example, if Contact references Customer and this entity use
Fuzzy Matching, you must load in SD_CONTACT the following columns:
-
FP_CUSTOMER: Code of the publisher providing the customer referenced by the given contact. E.g.:MKT. -
FS_CUSTOMER: Source ID of the customer referenced by the given contact. E.g.:81239.
Attribute Columns
You should load the attribute columns relevant for the entity that you are loading.
Make sure to load:
-
The attribute columns that make sense for the entity class (
B_CLASSNAME) that you are loading. -
The mandatory attribute columns. If not, pre-consolidation validation may reject source records with null values.
-
The columns for attributes using a list of values type. If these are loaded with values out of the LOV range of values, pre-consolidation validation may reject source records.
| Attributes may be loaded with null or incorrect values if the values are set or modified by the enrichers. Enrichers are executed before any validation. |
Other SD Columns (Optional)
The following columns do not need to be loaded or can be optionally loaded:
-
B_STATUS: This column should not be loaded as it will be internally set by the integration job. -
B_ORIGINALBATCHID: This column is not used for external loads and should not be loaded. -
B_CREATOR,B_UPDATOR: The columns can be optionally loaded. Their value will default to the name of user submitting the load. -
B_CREDATE,B_UPDDATE: The columns can be optionally loaded. Their value will default to the submission timestamp.
Submitting a Load
Submitting an external load uses the following parameters:
-
load_id: Load ID returned by the load initialization. -
integration_job: Name of the integration job to process this load. -
user_name: name of the user who has initialized the external load. This user may or may not be a user defined in the security realm of the application server.
The INTEGRATION_LOAD.SUBMIT_LOAD function call submits an external
load identified by its Load ID and returns a Batch ID. It is performed
on the repository database schema.
vBatch_id := <repository_schema>.INTEGRATION_LOAD.SUBMIT_LOAD(
<load_id> /* Load ID returned by INTEGRATION_LOAD.GET_NEW_LOADID */
'<integration_job>' /* Name of the Integration Job to trigger. */
'<user_name>' /* User who has initialized the load. */
);The following example performs a function call to submit an external
load identified by the Load ID 22. It submits it with the job name
INTEGRATE_DATA. The repository schema is REPO. The returned
Batch ID is stored in the vBatch_id variable.
vBatch_id := REPO.INTEGRATION_LOAD.SUBMIT_LOAD(
22,
'INTEGRATE_DATA',
'John Doe' );Canceling a Load
Canceling a load is performed using the CANCEL_LOAD function with the following parameters:
-
load_id: Load ID returned by the load initialization. -
user_name: name of the user who has initialized the external load. This user may or may not be a user defined in the security realm of the application server.
The INTEGRATION_LOAD.CANCEL_LOAD procedure cancels an external
load identified by its Load ID. It is performed on the repository database schema.
This procedure does not flush the content of the SD_% tables loaded during the external load.
This must be taken care of separately.
|
<repository_schema>.INTEGRATION_LOAD.CANCEL_LOAD(
<load_id> /* Load ID returned by INTEGRATION_LOAD.GET_NEW_LOADID */
'<user_name>' /* User who has initialized the load. */
);INTEGRATION_LOAD.CANCEL_LOAD to cancel an external load identified by the Load ID 22.REPO.INTEGRATION_LOAD.CANCEL_LOAD(
22,
'John Doe' );Consuming Data Using SQL
Consuming Data from Stambia MDM is done in SQL using the tables of the hubs. This chapter covers this type of consumption.
Overview
Consuming the data mainly involves:
-
The Golden Data. Contains the enriched, consolidated, validated and certified golden records
-
The Master Data. Contains the master records linked to the golden records. Master records contain the references to the source records.
Using the golden data in conjunction with the master data allows cross referencing to source data and re-integrating golden data into source systems.
| The examples provided in this section can be executed on the MDM hub deployed in the demonstration and evaluation environment used with the Stambia MDM Getting Started Guide. |
Consuming Golden Data
Golden Data Table Structure
The complete list of system columns available is provided in the Table Structures section of this guide. The following table lists the system columns used when consuming information from the hub:
| Column Name | Datatype | Description |
|---|---|---|
|
|
ID of the batch that created this record. |
|
|
Data branch containing this record. |
|
|
Class name of this record. |
|
|
Edition from which the Master/Golden record exists. |
|
|
Edition until which the Master/Golden record exists. |
|
|
Creation date of the record. |
|
|
Last update date of the record. |
|
|
Creator of the record. |
|
|
Last updater of this record. |
Accessing Golden Data Using SQL
To access golden data using SQL, you query on the GD table. The queries are filtered to access data:
-
for one or more entity classes,
-
stored in a given data branch,
-
and existing in a given data edition.
Accessing Golden Data in a Given Data Edition
The following code sample gives a query to access golden records in the GD table in a given data edition.
select G.* (1)
from GD_<Physical_Table_Name> G (2)
where
G.B_BRANCHID = <branch_id> (3)
and G.B_CLASSNAME in
( <classname_list> ) (4)
and G.B_FROMEDITION< = <edition> (5)
and (
G.B_TOEDITION is null
or
G.B_TOEDITION > <edition> (5)
)Explanation of the query:
| 1 | We select all columns from the golden record. You can select specific columns from the GD record. |
| 2 | The GD table accessed is named after the entity. Replace <Physical Table Name> with the physical table name defined for the entity. |
| 3 | Enter the ID of the data branch storing the data to access. |
| 4 | Provide the list of entity classes stored in this table that you want to access. For example, Person,Company. |
| 5 | Provide the ID of the data edition that you are accessing. This edition value can be a closed or an open data edition.
If you want to see records existing between two editions, you can
provide different values for B_FROMEDITION and B_TOEDITION. |
CONTACT_ID, FIRST_NAME and LAST_NAME golden data for the Contact entity in the data branch 0 and in the data edition 1.select CONTACT_ID, FIRST_NAME, LAST_NAME
from GD_CONTACT G
where
G.B_BRANCHID = 0
and G.B_CLASSNAME = 'Contact'
and G.B_FROMEDITION <= 1
and (
G.B_TOEDITION is null
or
G.B_TOEDITION > 1
)Accessing Golden Data in the Latest Data Edition
The following code sample gives a query to access the latest version of the data, which is the data in the latest data edition.
select G.* (1)
from GD_<Physical_Table_Name> G (2)
where
G.B_BRANCHID = <branch_id> (3)
and G.B_CLASSNAME in
( <classname_list> ) (4)
and G.B_TOEDITION is null (5)Explanation of the query:
| 1 | We select all columns from the golden record. You can select specific columns from the GD record. |
| 2 | The GD table accessed is named after the entity. Replace <Physical Table Name> with the physical table name defined for the entity. |
| 3 | Enter the ID of the data branch storing the data to access. |
| 4 | Provide the list of entity classes stored in this table that you want to access. For example, Person,Company. |
| 5 | There is no need to provide a specific data edition. The records available in the latest data edition are those with B_TOEDITION is null. |
CONTACT_ID, FIRST_NAME and LAST_NAME golden data for the Contact entity in latest data edition of data branch 0.select CONTACT_ID, FIRST_NAME, LAST_NAME
from GD_CONTACT G
where
G.B_BRANCHID = 0
and G.B_CLASSNAME = 'Contact'
and G.B_TOEDITION is nullGolden Data Primary Key
The primary key for a golden data table depends on the matching behavior of the entity and the ID Generation for the entity. A column named after the Physical Column Name of the primary key attribute stores the golden record primary key for the GD table and has the following datatype:
-
For ID Generation - Sequence:
NUMBER(38,0) -
For ID Generation - UUID_:
RAW -
For ID Generation - Manual, the datatype is the one defined for the primary key attribute.
Consuming Master Data
Accessing master data uses queries similar to those used to access the
golden data.
Starting from the golden data, we can refer to the master data using the
golden record primary key. The master data table (MD) includes a column
that references this primary key. As the master data also stores the
primary key of the publisher, it is possible to refer back to the source
data from the golden data via the master data.
Depending on the entity matching behavior (ID Matching or Fuzzy Matching), access to the master data differs:
Accessing Master Data Using SQL (ID Matching)
With ID Matching, the master data table has a structure similar to the
golden data table, and contains in addition the publisher code. The same
primary key is stored in the golden and master data in a column named
after the physical column name of the primary key attribute
(<primary_key_column> in the sample below)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
select M.B_SOURCEID, G.*
from MD_<Physical_Table_Name> M
inner join GD_<Physical_Table_Name> G on
( G. <primary_key_column> = M. <primary_key_column>
and G.B_BRANCHID = <branch_id>
and G.B_CLASSNAME in ( <classname_list> )
and G.B_FROMEDITION <= <edition>
and ( G.B_TOEDITION is null or
G.B_TOEDITION > <edition> )
)
where
M.B_BRANCHID = <branch_id>
and M.B_CLASSNAME in ( <classname_list> )
and M.B_FROMEDITION <= <edition>
and ( M.B_TOEDITION is null or
M.B_TOEDITION > <edition> )
and M.B_PUBID = '<publisher_code>'
and M.<primary_key_column> = '<searched_source_id>'
In this code, access is filtered with the branch ID, the class name and edition number for both the golden data (lines #5 to #9) and the master data (lines #13 to #16). The two tables are joined on their common primary key (line #4). In addition, the master data is filtered by source publisher (line #17) and ID of the source record (line #18).
EMPLOYEE_NUMBER=100 in the HR system (ID Matching).select M.EMPLOYEE_NUMBER, G.FIRST_NAME, G.LAST_NAME
from MD_EMPLOYEE M
inner join GD_EMPLOYEE G on
( G.EMPLOYEE_NUMBER = M.EMPLOYEE_NUMBER
and G.B_BRANCHID = 0
and G.B_CLASSNAME = 'Employee'
and G.B_FROMEDITION <= 1
and ( G.B_TOEDITION is null or G.B_TOEDITION > 1 )
)
where
M.B_BRANCHID = 0
and M.B_CLASSNAME = 'Employee'
and M.B_FROMEDITION <= 1
and ( M.B_TOEDITION is null or M.B_TOEDITION > 1 )
and M.B_PUBID = 'HR'
and M.EMPLOYEE_NUMBER = '100'The resulting information can be used to update the source record with golden data.
Accessing Master Data Using SQL (Fuzzy Matching)
With Fuzzy Matching, the master data table has a structure similar to the golden data table. It contains a reference to the golden data primary key, but the master data primary key (for a given edition) consists of two columns:
-
B_PUBID(VARCHAR2(30 CHAR)) contains the code of the publisher that published this record. -
B_SOURCEID(VARCHAR2(128 CHAR)) contains the ID of the source record in that publisher
As a consequence, the link between golden and master records is done
using the primary key column as in ID Matching, but the link to the
source is done using the B_SOURCEID column.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
select M.B_SOURCEID, G.*
from MD_<entity> M
inner join GD_<entity> G on
( G. <primary_key_column> = M. <primary_key_column>
and G.B_BRANCHID = <branch_id>
and G.B_CLASSNAME in ( <classname_list> )
and G.B_FROMEDITION <= <edition>
and ( G.B_TOEDITION is null or
G.B_TOEDITION > <edition> )
)
where
M.B_BRANCHID = <branch_id>
and M.B_CLASSNAME in ( <classname_list> )
and M.B_FROMEDITION <= <edition>
and ( M.B_TOEDITION is null or
M.B_TOEDITION > <edition> )
and M.B_PUBID = '<publisher_code>'
and M.B_SOURCEID = '<searched_source_id>'
In this code, the golden and master data tables are joined on their
golden record primary key (line #4), but the master data is restricted
by source publisher (line #17) and ID of the source record (line #18),
using the B_SOURCEID column.
27030 in the CRM system (Fuzzy Matching).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
select M.B_SOURCEID, G.FIRST_NAME, G.LAST_NAME
from MD_CONTACT M
inner join GD_CONTACT G on
( G.CONTACT_ID = M.CONTACT_ID
and G.B_BRANCHID = 0
and G.B_CLASSNAME = 'Contact'
and G.B_FROMEDITION <= 1
and ( G.B_TOEDITION is null or G.B_TOEDITION > 1 )
)
where
M.B_BRANCHID = 0
and M.B_CLASSNAME = 'Contact'
and M.B_FROMEDITION <= 1
and ( M.B_TOEDITION is null or M.B_TOEDITION > 1 )
and M.B_PUBID = 'CRM'
and M.B_SOURCEID = '27030'
Example: Select side by side the duplicates detected for a given source
Contact record with the ID 27030 in the CRM system (Fuzzy
Matching). In this example, the master data table is used twice (aliased
as M and MM) to retrieve the two sides of a duplicate pair.
select
M.B_PUBID DUP1_PUBLISHER, M.B_SOURCEID DUP1_ID, M.FIRST_NAME DUP1_FIRST_NAME, M.LAST_NAME DUP1_LAST_NAME,
MM.B_PUBID DUP2_PUBLISHER, MM.B_SOURCEID DUP2_ID, MM.FIRST_NAME DUP2_FIRST_NAME, MM.LAST_NAME DUP2_LAST_NAME,
G.CONTACT_ID GOLD_ID, G.FIRST_NAME GOLD_FIST_NAME, G.LAST_NAME GOLD_LAST_NAME
from MD_CONTACT M
inner join GD_CONTACT G on
( G.CONTACT_ID = M.CONTACT_ID
and G.B_BRANCHID = 0
and G.B_CLASSNAME = 'Contact'
and G.B_FROMEDITION <= 1
and ( G.B_TOEDITION is null or G.B_TOEDITION > 1 ) )
inner join MD_CONTACT MM on
( MM.CONTACT_ID = M.CONTACT_ID
and MM.B_BRANCHID = 0
and MM.B_CLASSNAME = 'Contact'
and MM.B_FROMEDITION <= 1
and ( MM.B_TOEDITION is null or MM.B_TOEDITION > 1 ) )
where
M.B_BRANCHID = 0
and M.B_CLASSNAME = 'Contact'
and M.B_FROMEDITION <= 1
and ( M.B_TOEDITION is null or M.B_TOEDITION > 1 )
and M.B_PUBID = 'CRM' /* Publisher ID */
and M.B_SOURCEID = '27030' /* Source ID */
/* and M.B_PUBID = MM.B_PUBID */
/* Uncomment the previous line to restrict the duplicates
to those within the CRM application */Consuming Errors
Accessing Pre-Consolidation Errors Using SQL
Pre-consolidation errors can be accessed via the Source Errors (SE)
tables.
These tables store the erroneous source data information, as well as the
information about the constraints that caused the records to fail the
validation. The latter is stored in the B_CONSTRAINTNAME (name of the
constraint) and B_CONSTRAINTTYPE (type of the constraint) columns.
Example: Select the errors for the latest batch in the branch 0 for
the Contact entity.
In this example, incorrect foreign references would appear. To identify
them, we retrieve the incorrect referenced IDs from FP_CUSTOMER and
FS_CUSTOMER.
0 for the Contact entityselect SE.B_BATCHID,
SE.B_CONSTRAINTNAME, SE.B_CONSTRAINTTYPE,
SE.B_PUBID, SE.B_SOURCEID, SE.FIRST_NAME, SE.LAST_NAME,
SE.FP_CUSTOMER, SE.FS_CUSTOMER
from SE_CONTACT SE
where
SE.B_BRANCHID = 0
and SE.B_CLASSNAME = 'Contact'
and SE.B_BATCHID = ( select max(B_BATCHID)
from SE_CONTACT
where SE.B_BRANCHID = 0 )Accessing Post-Consolidation Errors Using SQL
Post-consolidation errors can also be accessed via the Golden Errors
(GE) tables.
These tables store the erroneous records that were consolidated but not
certified as golden data, as well as the information about the
constraints that caused the records to fail the validation. The latter
is stored in the B_CONSTRAINTNAME (name of the constraint) and
B_CONSTRAINTTYPE (type of the constraint) columns.
Example: Select the errors for the latest batch in the branch 0 for
the Employee entity. In this example, wrong values for the
CostCenter would appear. We retrieve these values from the
F_COST_CENTER column for review.
0 for the Employee entity.select GE.B_BATCHID,
GE.B_CONSTRAINTNAME, GE.B_CONSTRAINTTYPE,
GE.EMPLOYEE_NUMBER, GE.FIRST_NAME, GE.LAST_NAME,
GE.F_COST_CENTER, GE.F_MANAGER
from GE_EMPLOYEE GE
where
GE.B_BRANCHID = 0
and GE.B_CLASSNAME = 'Employee'
and GE.B_BATCHID = ( select max(B_BATCHID)
from GE_EMPLOYEE
where GE.B_BRANCHID = 0 );Consuming Data Using Web Services
SOA-enabled applications use Stambia MDM Web Services to interact with the platform and the data in the MDM Hub.
Overview
The data services provide access to the data editions known to the application instance. These data services are generated per data edition, and their capabilities depend on the underlying deployed model edition.
The data services for each data edition include:
-
The Data Access service, named after the model, that provides read access to the various views storing golden data, master data, errors detected, etc. The structure of this service is dependent of the model structure.
-
The Activity Service that allows SOA applications to manage instances of workflows defined in applications. This service is explained in the Managing Activities Using Web Services chapter.
-
The Generic Data Service that allows applications to interact (read/write) with the data in the hub in a generic way. Unlike the Data Access service, this web service provides a generic structure that is model-independent.
Data Services URL
Data access services are accessed at the following URL:
http://<host>:<port>/<application>/ws/<ws_version>/data/<data_location>/<data_branch>.<data_edition>/<web_service_name>?wsdl
where:
-
<host>,<port>,<application>is the location of the Stambia MDM application instance deployed in the application server. -
<ws_version>is the version of the Stambia MDM data access services: Set this value to1.0 -
<data_location>is the name of the data location into which the data edition is stored. -
<data_branch>is the ID of the data branch of the data edition. -
<data_edition>is the ID of the data edition in this branch. -
<web_service_name>is the name of the data access service: ActivityService, GenericDataService, or the Model Name for the Data Access service.
For example:
http://127.0.0.1:10080/ws/1.0/data/CustomerAndFinancialMDM/0.0/GenericDataService?wsdl
| Make sure that the data access web services are started before attempting to access them. They are not started by default when the data edition is created. You must start them and optionally configure them to automatically start using the Web Service Manager editor in the Administration Console perspective. See the Managing Web Services section in the Stambia MDM Administration Guide for more information about web service management. |
| When a web service is started, you can access its WSDL by double-clicking its WSDL URL in the services list in the Web Service Manager editor. In the Web Service Details dialog that opens, click the WSDL URL link to view the WSDL content. |
Data Access Service
This service is named after the model, and its structure depends on the model structure. It provides read-only access to the various views storing golden data, master data, errors detected, etc.
Data Access Web Services Structure
For a given data edition, the data access service is organized as follows:
-
Each entity has two operations for each structure available for this entity. Structures are Master Data, Golden Data, Duplicates, etc….
-
These two operation allow:
-
Requesting a list of record. The operation is named:
get<Entity Name>_<Structure>_List. For example: getCustomer_MasterData_List.-
The list can be filtered using a SemQL Condition.
-
The list is paginated using a StartIndex and a PageSize. For example, if the list contains 200 records, you can read the 30 first records by using a StartIndex of 1 and a PageSize of 30.
-
-
Requesting a specific record. The operation is named
get<Entity Name>_<Structure>_Record. For example: getCustomer_GoldenData_Record -
The specific record is requested using the primary key fields of the given data structure.
-
Requests Examples
getCustomer_GoldenData_List operation to retrieve the first 20 Golden Customers named like G%.<soapenv:Envelope
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:ns="http://www.semarchy.com/xml/ws/1.0/data/CustomerAndFinancialMDM/0.0">
<soapenv:Header/>
<soapenv:Body>
<ns:getCustomer_GoldenData_List>
<query>
<SemQLCondition>CustomerName LIKE 'G%'</SemQLCondition>
<StartIndex>0</StartIndex>
<PageSize>20</PageSize>
</query>
</ns:getCustomer_GoldenData_List>
</soapenv:Body>
</soapenv:Envelope>getCustomer_GoldenData_Record operation to retrieve the Golden Customer with CustomerID=20<soapenv:Envelope
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:ns="http://www.semarchy.com/xml/ws/1.0/data/CustomerAndFinancialMDM/0.0">
<soapenv:Header/>
<soapenv:Body>
<ns:getCustomer_GoldenData_Record>
<recordKey>
<CustomerID>20</CustomerID>
</recordKey>
</ns:getCustomer_GoldenData_Record>
</soapenv:Body>
</soapenv:Envelope>Responses Examples:
getCustomer_GoldenData_Record call.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/">
<soap:Body>
<ns1:getCustomer_GoldenData_RecordResponse ... >
<return>
<BatchID>41</BatchID>
<BranchID>0</BranchID>
<FromEdition>1</FromEdition>
<ClassName>Customer</ClassName>
<CreationDate>2011-09-21T09:37:42.738+02:00</CreationDate>
<Creator>joeletaxi</Creator>
<CustomerID>20</CustomerID>
<CustomerName>GENERAL SERVICES CORPORATION</CustomerName>
<TotalRevenue>9111</TotalRevenue>
<InputAddress>
<Address>1 TERRITORIAL DRIVE</Address>
<City>BOLINGBROOK</City>
<Country>USA</Country>
</InputAddress>
<GeocodedAddress/>
<FDN_Employee>Adam FRIPP</FDN_Employee>
<FID_Employee>121</FID_Employee>
</return>
</ns1:getCustomer_GoldenData_RecordResponse>
</soap:Body>
Note that the returned payload includes:
-
Lines #5 to #10: Internal and process-specific information.
-
Lines #11 to #13: Simple attributes as simple elements.
-
Lines #14 to #18: Complex attributes as complex type elements (e.g. InputAddress).
Generic Data Service
The Generic Data Service allows applications to interact (read/write) with the data in the hub in a generic way. Unlike the Data Access service, this web service provides a generic structure that is model-independent.
Generic Data Service Bindings
This web service provides the following bindings:
| Binding Name | Description |
|---|---|
queryRows |
Queries a view for a given entity, optionally in the context of a load ID. This web service returns a recordset corresponding to the query. See Querying Rows for more details about queries. |
queryCount |
Returns the count of records for a given query. See Querying Rows for more details about queries. |
checkoutRows |
Checkouts records - retrieved using a query - in a transaction attached to a data entry workflow task. The checked out records can be inserted in the transaction under a given node of a business object. See Checking Out Rows for more details. |
PersistRow |
Inserts or updates records in a transaction attached to a workflow task. See Inserting and Updating Records for more information. |
RemoveRowFromTx |
Remove records from a transaction attached to a workflow task. |
| The queryCount operations is explained in this chapter. The other operations use for manipulating data are explained in the Managing Activities Using Web Services chapter. |
Querying Rows
A query in the generic data service is composed of:
-
Several Select Expressions. Each expression is a SemQL expression returning a value. Note that these expressions may use aggregate operators.
-
Zero or one Where Condition. This condition is a SemQL condition used to filter the records for the query.
-
Zero or more Group By Expression and Zero or one Having Expressions. These expressions are used when the select expressions use aggregate operators.
-
Zero or more Order By Criteria expressions.
Note that the expressions mentioned above can use bind variables.
Variables used in bind mode in the expressions (through the
:<variable_name> syntax) can be specified in the request through
Bindings. Bindings are named and typed.
Optionally, the generic data service supports pagination for the resultsets (through a Page Index and a Page Size)
The following code is a query to retrieve the golden customer revenue
per country and employees, with a filter on employee names through the
EMP binding.
<soapenv:Envelope>
<soapenv:Header/>
<soapenv:Body>
<gen:RowQuery>
<QuerySource>
<!-- Golden Data view for the Customer entity -->
<gen:EntityName>Customer</gen:EntityName>
<ViewType>GD</ViewType>
</QuerySource>
<!-- Select Expressions, incl. an aggregate (SUM) -->
<SelectExpression>AccountManager.FirstName || ' ' || AccountManager.LastName
</SelectExpression>
<SelectExpression>InputAddress.Country</SelectExpression>
<SelectExpression>SUM(TotalRevenue)</SelectExpression>
<!-- Filter applied on the data, using the EMP biding. -->
<WhereCondition>AccountManager.FirstName||' '||AccountManager.LastName LIKE :EMP
</WhereCondition>
<!-- The SUM calls for a group by on the other expressions -->
<GroupByExpression>InputAddress.Country</GroupByExpression>
<GroupByExpression>AccountManager.FirstName || ' ' || AccountManager.LastName
</GroupByExpression>
<!-- Ordering the results -->
<OrderByCriteria descending="true">SUM(TotalRevenue)
</OrderByCriteria>
<!-- Definition for the EMP biding with the value -->
<Binding name="EMP">
<String>S%</String>
</Binding>
<!-- Result pagination -->
<PageCriteria>
<StartIndex>0</StartIndex>
<PageSize>10</PageSize>
</PageCriteria>
</gen:RowQuery>
</soapenv:Body>
</soapenv:Envelope><soap:Envelope>
<soap:Header/>
<soap:Body>
<ns2:RowQueryResponse>
<Row>
<Value name="AccountManager.FirstName || ' ' || AccountManager.LastName">
<String>Steven King</String>
</Value>
<Value name="InputAddress.Country">
<String>FRANCE</String>
</Value>
<Value name="SUM(TotalRevenue)">
<Decimal>62904</Decimal>
</Value>
</Row>
<Row>
<Value name="AccountManager.FirstName || ' ' || AccountManager.LastName">
<String>Shanta Vollman</String>
</Value>
<Value name="InputAddress.Country">
<String>USA</String>
</Value>
<Value name="SUM(TotalRevenue)">
<Decimal>52978</Decimal>
</Value>
</Row>
...
...
</ns2:RowQueryResponse>
</soap:Body>
</soap:Envelope>Managing Activities Using Web Services
Overview
The Activity Service that allows SOA applications to manage workflow instances defined in applications. This Web Service can be used in conjunction with the Generic Data Service to edit the contents of the MDM hub through data entry workflows.
This web service provides the following bindings:
| Binding Name | Description |
|---|---|
startActivity |
Starts an activity based on a given workflow and returns the activity and first task’s UUIDs. See Starting an Activity for more details. |
getActivity |
Returns the information about an activity (including the current active task) from its UUID. |
getTask |
Returns the information about a task (including information about the activity) from its UUID. |
listTasks |
List tasks and activities in an application with filtering options. See Listing Tasks for more details. |
countTasks |
Count tasks and activities in an application with filtering options. See Listing Tasks for more details. |
claimTask/unclaimTask |
Claims/unclaims a task identified by its UUID. See Claiming Tasks for more details. |
completeTask |
Completes a task and moves the activity to a subsequent task. The same operation is used to submit/cancel the activity. See Completing Tasks for more details. |
Starting an Activity
The following example starts the ContactsCreationProcess in the DemoApplication, and claims the CreateOrModifyContacts startup task.
<soapenv:Envelope
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:act="http://www.semarchy.com/xml/ws/1.0/activity/ActivityService">
<soapenv:Header/>
<soapenv:Body>
<act:StartActivity>
<ApplicationName>DemoApplication</ApplicationName>
<HumanWorkflowName>ContactsCreationProcess</HumanWorkflowName>
<StartTaskName>CreateOrModifyContacts</StartTaskName>
<ActivityLabel>Create a new Contact</ActivityLabel>
<StartComments>Please create a new contact</StartComments>
<NotifyAssignee>false</NotifyAssignee>
<ClaimTask>true</ClaimTask>
<Priority>NORMAL</Priority>
</act:StartActivity>
</soapenv:Body>
</soapenv:Envelope>This request returns the following information.
<soap:Envelope
xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/">
<soap:Header/>
<soap:Body>
<ns2:StartActivityResponse
xmlns:ns2="http://www.semarchy.com/xml/ws/1.0/activity/ActivityService">
<Activity>
<ActivityUUID>34f86f93-d467-4fc3-b8b9-42f779f52335</ActivityUUID>
<ActivityLabel>Create a new Contact</ActivityLabel>
<ApplicationName>DemoApplication</ApplicationName>
<WorkflowName>ContactsCreationProcess</WorkflowName>
<LoadID>62</LoadID>
<Type>DATA_ENTRY</Type>
<Priority>NORMAL</Priority>
<CreationDate>2013-11-12T14:34:12.569+01:00</CreationDate>
<Initiator>mdmadmin</Initiator>
<StartComments>Please create a new contact</StartComments>
<Status>RUNNING</Status>
</Activity>
<Task>
<TaskUUID>84d5db16-0b8c-4c28-af53-df61e5e521a6</TaskUUID>
<ApplicationName>DemoApplication</ApplicationName>
<WorkflowName>ContactsCreationProcess</WorkflowName>
<TaskName>CreateOrModifyContacts</TaskName>
<ActivityUUID>34f86f93-d467-4fc3-b8b9-42f779f52335</ActivityUUID>
<TaskSequence>0</TaskSequence>
<TaskCreationDate>2013-11-12T14:34:12.569+01:00</TaskCreationDate>
<TaskCreationUser>mdmadmin</TaskCreationUser>
<TaskPerformer>mdmadmin</TaskPerformer>
<TaskRevision>17082</TaskRevision>
<TaskAssigneeRole>DemoSalesRep</TaskAssigneeRole>
<TaskClaimDate>2013-11-12T14:34:12.569+01:00</TaskClaimDate>
<TaskRoleNotified>false</TaskRoleNotified>
</Task>
</ns2:StartActivityResponse>
</soap:Body>
</soap:Envelope>Note that when working with activities and tasks, the UUID is used to identify the task, including when manipulating transaction data through the Generic Data Service.
Listing Tasks
The following request lists the tasks claimed by the connected user in the DemoApplication application.
<soapenv:Envelope
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:act="http://www.semarchy.com/xml/ws/1.0/activity/ActivityService">
<soapenv:Header/>
<soapenv:Body>
<act:ListTasks>
<ApplicationName>DemoApplication</ApplicationName>
<!-- Possible filter types are CLAIMED_BY_ME,
CLAIMED_BY_OTHERS, ALL, PENDING -->
<FilterType>CLAIMED_BY_ME</FilterType>
</act:ListTasks>
</soapenv:Body>
</soapenv:Envelope>Claiming Tasks
The following request claims a task identified by its UUID.
<soapenv:Envelope
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:act="http://www.semarchy.com/xml/ws/1.0/activity/ActivityService">
<soapenv:Header/>
<soapenv:Body>
<act:ClaimTask>
<TaskUUID>50baf56e-a97d-43a1-a5f6-b8d2f2108828</TaskUUID>
</act:ClaimTask>
</soapenv:Body>
</soapenv:Envelope>This same task can be unclaimed using the following request.
<soapenv:Envelope
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:act="http://www.semarchy.com/xml/ws/1.0/activity/ActivityService">
<soapenv:Header/>
<soapenv:Body>
<act:UnclaimTask>
<TaskUUID>50baf56e-a97d-43a1-a5f6-b8d2f2108828</TaskUUID>
<NotifyAssignee>false</NotifyAssignee>
</act:UnclaimTask>
</soapenv:Body>
</soapenv:Envelope>Managing Data Into Tasks
The Generic Data Service can be used in conjunction with the Activity Service to manipulate the contents of the transactions managed through the Activity Service.
Checking Out Rows
Records are checked out for a data entry workflow using a query as
defined above.
When checking out rows, it is necessary to specify the unique ID (UUID)
of the task for which the records are checked out.
Besides, these records are inserted in a given target business object
(managed by this workflow). The name of this Business Object must be
provided.
In certain cases, the checked out records are in a sub-element of the
business object. In this context, the Parent Data Row must be specified
as the target of the check out operation.
The following example checks out in the context of a data entry task
master data (MD) for the Customer entity, filtered with
CustomerName like 'S%'.
<soapenv:Envelope>
<soapenv:Header/>
<soapenv:Body>
<gen:CheckoutRows>
<!-- Task UUID -->
<DETaskUUID>c2c3e188-650e-4608-b501-d7df832f9ca0</DETaskUUID>
<CheckoutQuery>
<QuerySource>
<gen:EntityName>Customer</gen:EntityName>
<ViewType>MD</ViewType>
</QuerySource>
<WhereCondition>CustomerName like 'S%'</WhereCondition>
</CheckoutQuery>
<Target>
<BusinessObject>CustomerBO</BusinessObject>
</Target>
</gen:CheckoutRows>
</soapenv:Body>
</soapenv:Envelope>Inserting and Updating Records
New records can be added to a transaction attached to an activity, and records checked out in this activity can also be modified.
To insert or update records, you must provide the unique ID (UUID) of the task, the name of the target entity of the insert/update operation. The New tag must be set to true/false to indicate whether it is a new record or an update.
Finally, you must provide in one or more datarows the various records that you want to update/insert. A datarow is composed of several values (named after the data entry form fields). For an insert, you should provide the Source ID or primary key and the mandatory data fields. For an update you should provide the Source ID or primary key and the data fields to update.
The following request adds a new Customer record through the task identified by the UUID.
<soapenv:Envelope>
<soapenv:Header/>
<soapenv:Body>
<gen:PersistRow>
<!-- Task UUID -->
<DETaskUUID>c2c3e188-650e-4608-b501-d7df832f9ca0</DETaskUUID>
<!-- Datarow to insert -->
<DataRow>
<!-- Target entity -->
<gen:EntityName>Customer</gen:EntityName>
<!-- Identifies an insert (new record) -->
<New>true</New>
<!-- Content of the data row -->
<DataRow>
<Value name="SourceID">
<String>654564</String>
</Value>
<Value name="CustomerName">
<String>SAMBALELE</String>
</Value>
<Value name="TotalRevenue">
<Integer>200020</Integer>
</Value>
</DataRow>
</DataRow>
</gen:PersistRow>
</soapenv:Body>
</soapenv:Envelope>Removing Rows from a Transaction
You can only remove records from an identified transaction. You must provide the unique ID (UUID) of the task, the name of the target entity of the insert/update operation. Provide one or more datarows containing the various records that you want to remove. A datarow is composed of several values (named after the data entry form fields). You should provide the Source ID or primary key or the records to remove.
Completing Tasks
The following request completes the task and passes it to the VerifyDataBeforeSubmit transition.
<soapenv:Envelope
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:act="http://www.semarchy.com/xml/ws/1.0/activity/ActivityService">
<soapenv:Header/>
<soapenv:Body>
<act:CompleteTask>
<TaskUUID>50baf56e-a97d-43a1-a5f6-b8d2f2108828</TaskUUID>
<CompletionComments>Ready for verification</CompletionComments>
<TransitionName>VerifyDataBeforeSubmit</TransitionName>
<CompletionOptions>
<NotifyNextTaskAssignee>false</NotifyNextTaskAssignee>
<ClaimNextTask>true</ClaimNextTask>
</CompletionOptions>
</act:CompleteTask>
</soapenv:Body>
</soapenv:Envelope>Using web services, it is possible to manage an activity until completion.