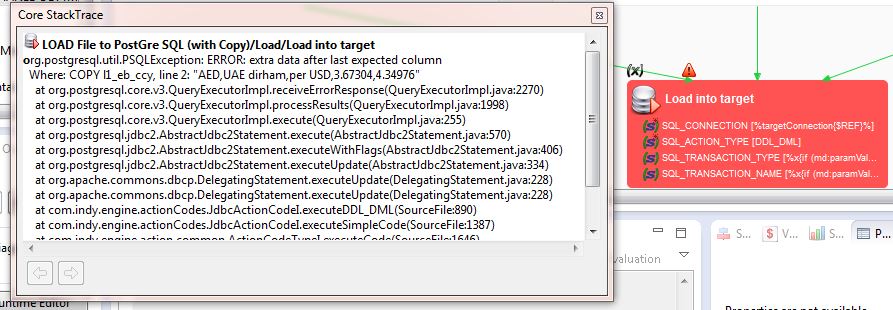
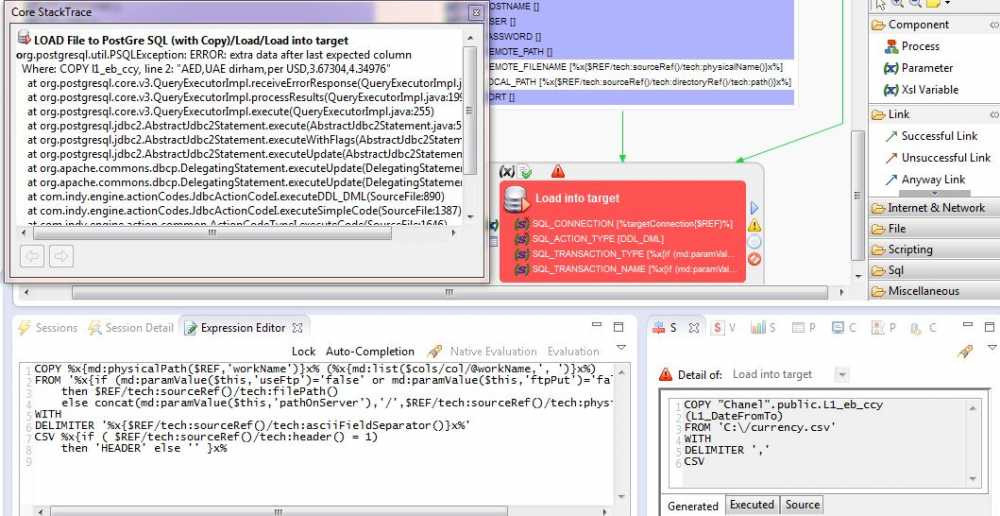
Here is the code in the "Load into target"
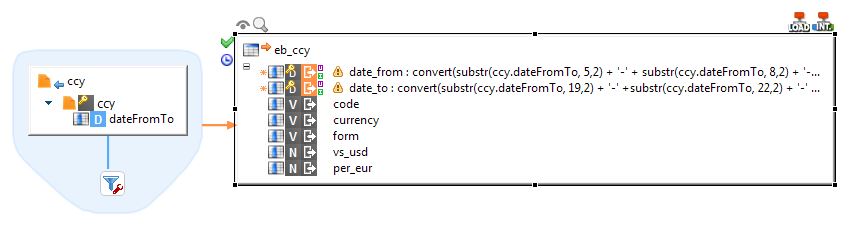
the structure in my metadata is:
Table(
Date_from date,
Date_to date,
champ1 varchar(3),
champ2 varchar(30),
champ3 varchar(10),
champ4 decimal,
champ5 decimal
);
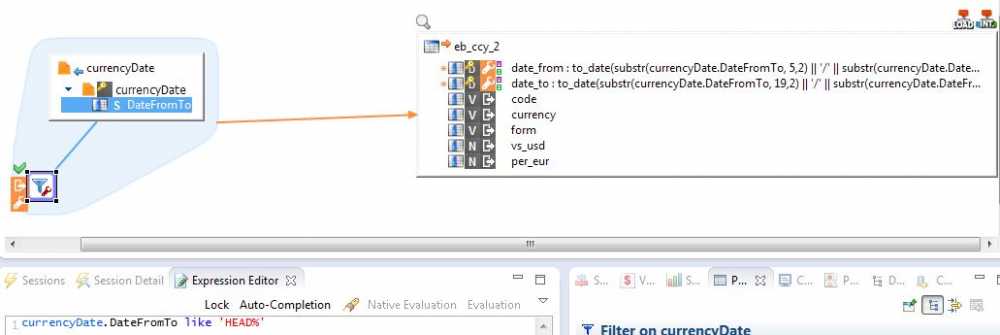
the first line in the file must be insert in Date_form and Date_to and it must be repeated as much as I have Data ( I will create 2 mappings; one for Dates and the other for the other data and I ll create a process to repeat the first mapping.That is my idea )
here the first lines :
HEAD12/22/2014 To 01/28/2015
AED,UAE dirham,per USD,3.67304,4.34976
ARS,Argentine peso,per USD,8.57102,10.15014
for example here as output I must have:
12/22/2014 01/28/2015 AED UAE dirham per USD 3.67304 4.34976
12/22/2014 01/28/2015 ARS Argentine peso per USD 8.57102 10.15014