

This article describes the principal changes of Generic Templates.
The Template download section can be found at this page.
Note:
Stambia DI is a flexible and agile solution. It can be quickly adapted to your needs.
If you have any question, any feature request or any issue, do not hesitate to contact us.
This article is dedicated to Stambia DI S17, S18 and S19.
If you are using Stambia DI S20 please refer to this article.
templates.generic.2020-09-17
INTEGRATION File
Generated header line was unexpectedly missing a line separator after it when using some specific parameter combination
When using "generate header" parameter alongside with "truncate=true" and "line separator=after", the generated header line was unexpectedly missing a line separator after it.
Data was written just after the header without any separation.
This has been fixed, a line separator is now properly added after the header line in this situation.
templates.generic.2020-05-26
INTEGRATION File
Following improvements have been performed on this Template:
- Parameter "Order ByExpression" now supports XPath expressions
- Adding a new statistic: STAT_INSERT
templates.generic.2020-04-24
TOOL Ldap Extractor (search)
Following improvements have been performed on this tool:
- New parameter to work with large volumes of data: "Page Size"
- Optimization performed: attributes which will not be extracted to target file are not read anymore
- Fix issue avoiding the tool to be used several times in the same Process
- Fix issue about "Count Limit" parameter which was not taken into account
TOOL Ldap Integrator
A new parameter "Match Ldap Attributes with" has been added.
This parameter defines how the template matches the ldap attributes with the file's fields:
- physical name: the template gets the ldap attributes which have the same name as the fields' physical names
- logical name: the template gets the ldap attributes named as the field name (not physical)
Load XML to Rdbms
New options have been added to be able to create indexes on temporary load tables when reading an XML File.
Using those options can help to improve performances when working with large XML files.
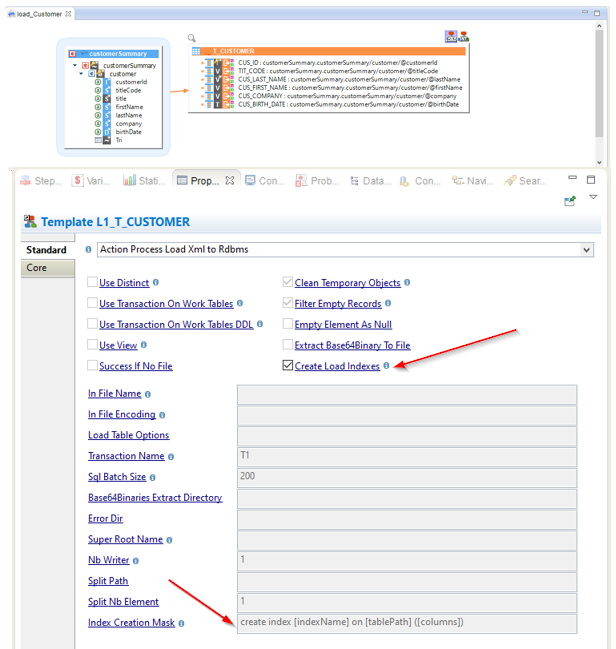
When 'Create Load Indexes' is set to true, the Template will automatically create indexes on the temporary Load tables created for the loading of the XML file.
Note that the Template will use a default syntax to create indexes which should work for most database technologies.
Note however that you can adjust the syntax used if needed through the "Index Creation Mask" parameter.
INTEGRATION Rdbms to Rdbms (no load)
This Template now supports having a source where CDC mode is enabled.
templates.generic.2019-11-20
REPLICATOR Rdbms
Fix replication of files
Prerequisites:
Stambia DI Designer S19.0.21 or higher is required to benefit of this fix
Object delimiters and Object Prefixes were not applied when the source of the replication was a file.
Those issues have been fixed.
templates.generic.2019-08-09
LOAD Xml to Rdbms
New parameter 'Use Transaction On Work Tables DDL'
A new parameter "Use Transaction On Work Tables DDL" has been added to define if the execution of Drop and Create table SQL DDL statements performed by the Template should be done in a transaction.
This can be useful to perform everything in a transaction, drop and create table included, when working with databases which allows such statements to be executed in transaction.
Note that some databases perform an implicit commit on DDL statements. In this case it is necessary to let this option to false to avoid committing the transaction to early in the process.
Some other databases handle the DDL in a transaction. In this case it is necessary to set this option to true to make sure that the tables are visible on the insert statements.
Refer to parameter's documentation for further information.
Drop and create table statements performed with "if exists" clause when applicable.
All drop and create table statements performed by the Template will now be performed with the "if exists" clause when the database supports it, to avoid logging errors when it does not exist.
When used with Netezza as target, set catalog clause is added
When using the Template to load XML data into Netezza, a "set catalog" statement is performed before drop and create table ones.
This is required when dropping or creating tables from another database than the one specified in the JDBC URL.
Ability to disable creation and drop of tables
An internal mechanism has been introduced to be able to re-use this Template more easily.
This is used for instance behind the scenes by the new "Load XML to Netezza" Template.
templates.generic.2019-07-11
REPLICATOR Rdbms
Support loading data when replicating to Google BigQuery
The replicator now supports loading data when replicating into a target BigQuery datastore.
REPLICATOR Xml to RDBMS
Primary key columns now created with NOT NULL option
When replicating source XML files into a database through the XML Replicator, tables are created on the target database when the "Create Tables" option is enabled.
The primary key columns were created as nullable, which could cause issue in some databases.
Primary key columns are now created with the non-nullable keyword, such as "NOT NULL" for most databases.
templates.generic.2019-06-11
REPLICATOR Rdbms
Fix several issues for Oracle SQL*Loader data loading
Two issues happening when loading data into Oracle through SQL*Loader have been fixed.
There were some cases where generated CTL file was not containing the defining of columns, which was causing issues, and which is now fixed.
There was also an issue with the record delimiter used to export source data into files which could be different than the one used by SQL*Loader which could also lead to issue and bad data loading, and which has also been fixed.
New truncate table parameter
A new additional parameter for removing data on target table before the replication has been added: 'Truncate Tables'.
Refer to parameter's documentation for further information.
templates.generic.2019-04-17
REPLICATOR Rdbms
Snowflake loading updated
Snowflake specific loading has been updated to take into account the changes which have been implemented on Snowflake Connector from templates.snowflake.2019-04-17.
Data loading will now be more efficient and match connector updates.
Generated target table name was incorrect for Microsoft SQL Server when using prefix parameter
Replication on a target Microsoft SQL Server database using "Target Object Prefix" parameter was not working properly.
Specified prefix was not included into the delimiters which surround generated target table but outside, which was causing issues.
This has been fixed, prefix is now placed properly in generated table name.
Replicator Xml to Rdbms
Ability to use technology specific loaders
XML Replicator now supports using technology specific loaders.
A new parameter named "Load Method" has been added to enable specific loading.
Refer to parameter documentation for further information.
templates.generic.2019-02-08
INTEGRATION Rdbms and INTEGRATION Hsql
Recycling of previous rejects fixed
When using the option to recycle the rejects of previous execution an extra step is executed to add those previous rejects in the integration flow.
Possible duplicates while retrieving those rejects are now filtered using DISTINCT keyword.
templates.generic.2019-01-29
Unload Rdbms to File
Template has been updated to use automatically technology specific syntax when generating empty NULL columns.
This has been modified to address issues with technologies which requires a different syntax than using "NULL" keyword, such as IBM Informix database which requires the column to be dynamically datatyped using "NULL:integer" for instance.
Prerequisites:
Stambia DI Designer S19.0.15 or higher is required for the Template to use technology specific syntax for this case.
Notes:
When using prior Designer versions, or a technology on which the syntax has not been defined, this will continue to work as before, by using the 'NULL' keyword
templates.generic.2019-01-15
TOOL Ldap Integrator
Operation failure management
Each row of source file is now processed even if an issue occurs while executing one of the iterations.
Previously, as soon as one of the operations was failing, the tool stopped executing and returned the error, avoiding all other iterations to be processed.
From now, all rows will be processed and when an iteration fails it will simply log information about it if required and process the next one.
New parameter for exporting encountered errors in file
A new parameter called 'Export Errors' has been added.
When enabled encountered errors will be traced in a log file.
New statistics
New variables are now published by tool, allowing to consult easily the result of operations: how many succeeded and how many failed.
They are all listed in the tool's description.
Allow having multiple instance of the tool in same process
All scripting actions contained in the tool have been updated to have a dynamically generated scripting connection.
This allows using multiple times the tools in the same process and also in parallel.
templates.generic.2018-12-19
REPLICATOR Rdbms
The Replicator now supports specific loaders for SybaseIQ and Snowflake for data loading.
They will now be used by default for these technologies instead of the generic mode.
If required, generic mode can still be used by enabling 'Force Generic Rdbms Mode'.
templates.generic.2018-12-05
REPLICATOR Rdbms
A new parameter named 'Split By Pattern' has been added to offer the possibility to customize the xpath expression used to find the column which is used to split source data into multiple subsets when using the split by mechanism.
As a reminder this mechanism can be used to replicate source table data into target with multiple parallel tasks.
Each task contains a number of rows calculated from the numeric column which is used to split data.
templates.generic.2018-10-22
INTEGRATION Rdbms to Rdbms (no load)
The 'INTEGRATION Rdbms to Rdbms (no load)', which has the specificity to integrates source data directly in the target without creating any temporary work table, is now available in more situations.
It was previously displayed in Mappings when integrating data on Excel and Google Spreadsheet as they are technologies which requires not using temporary objects and has now been expended to more cases.
It will now be available when integrating data in a target database as soon as the source is also a database, offering the possibility to perform direct integration in more situations.
Note that this applies only for technologies working through JDBC like databases, or files (which uses or own JDBC driver).
templates.generic.2018-10-08
REJECT Hsql
- Generated queries for Primary Keys and Alternate Keys were incorrect for composite keys
TOOL Ldap Extractor (search)
- Fix undefined variable error which is thrown when using the tool