In this article
You can find below the major changes and improvements of the S18.0 version.
Note:
This article only highlights the most important changes.
If you need further information, please consult the full changelog and/or reference documentation.
What's new in 18.0?
Note:
The runtime has not evolved in this version. It is a runtime equivalent to the S17 version.
The metadata and the processes have minor changes. The new features are mainly in the mappings.
Backward compatibility is obviously supported: your existing developments will continue to work.
Mapping capabilities
Multi-target Mappings
A same Mapping can now have multiple targets. For instance, it's possible to load multiple tables from a hierarchial datastore such as an XML File in a single Mapping.
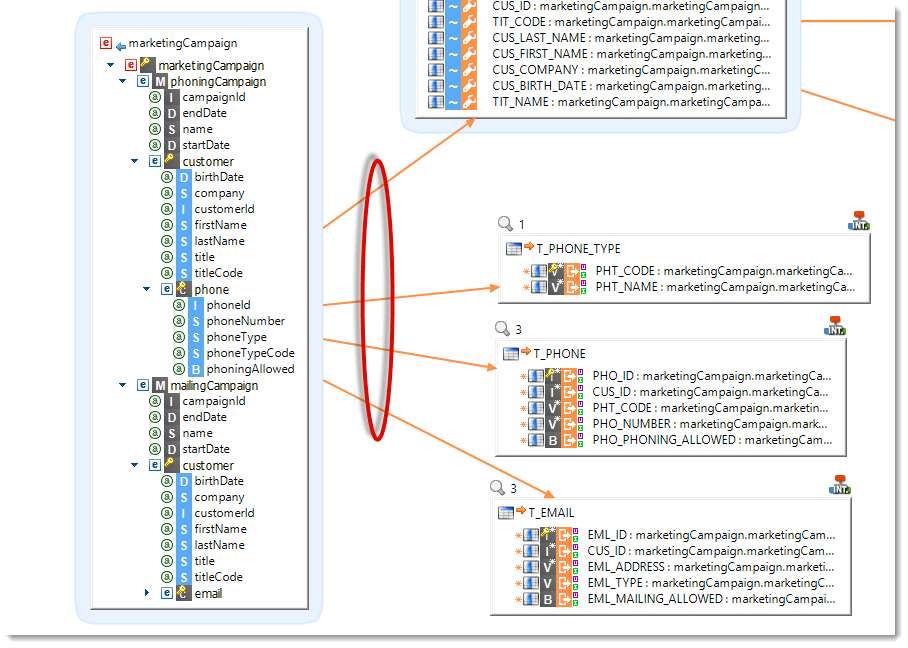
This feature can also be used to load a parent-child set of tables from a single source.
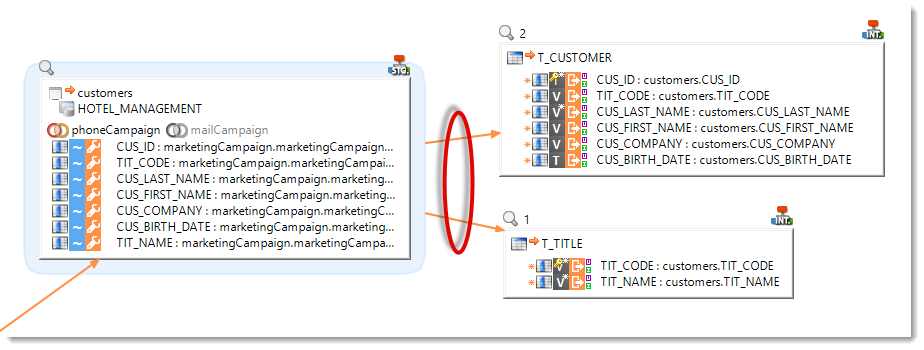
Datastore as Source and Target
A same datastore can now be used as a source and as a target in the same Mapping. This allows for instance to invoke a web service and use the answer inside the same mapping.
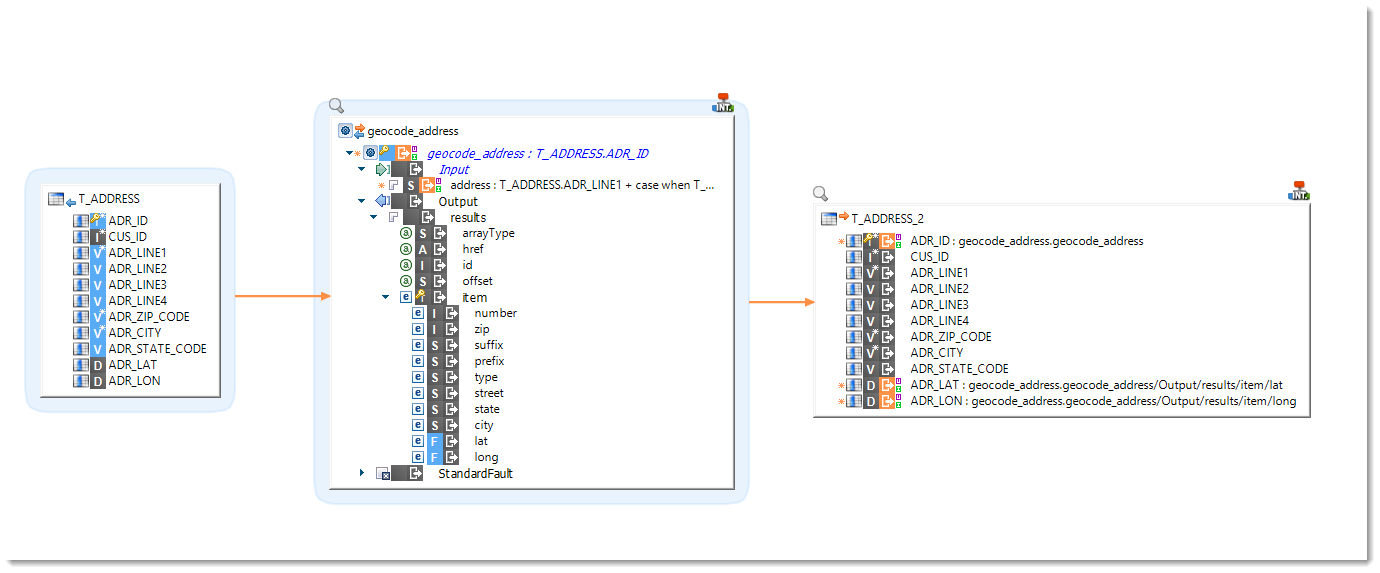
Set based operations support
Stambia now supports the use of set operators such as UNION, MINUS, etc.
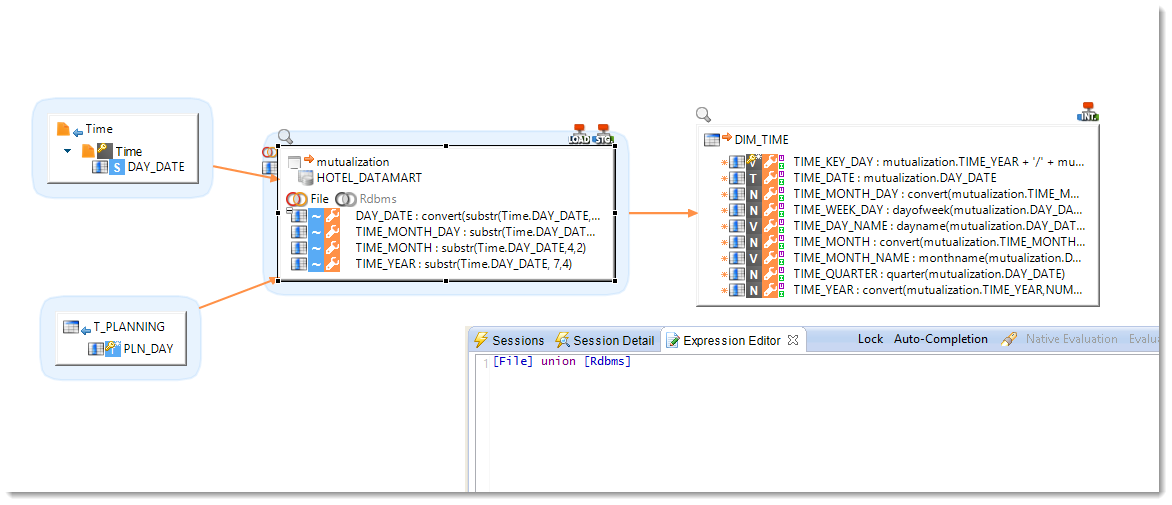
Stages
A new object exists in Mappings: the Stage. This object extends Stambia's capabilities beyond what you ever dreamt of by allowing the execution of additional transformations on any schema before the final integration in the target datastore. There are various applications of this new feature.
Stages can simplify Mapping by dividing complex transformations into smaller manageable pieces or by mutualizing an expression reused in multiple transformations.
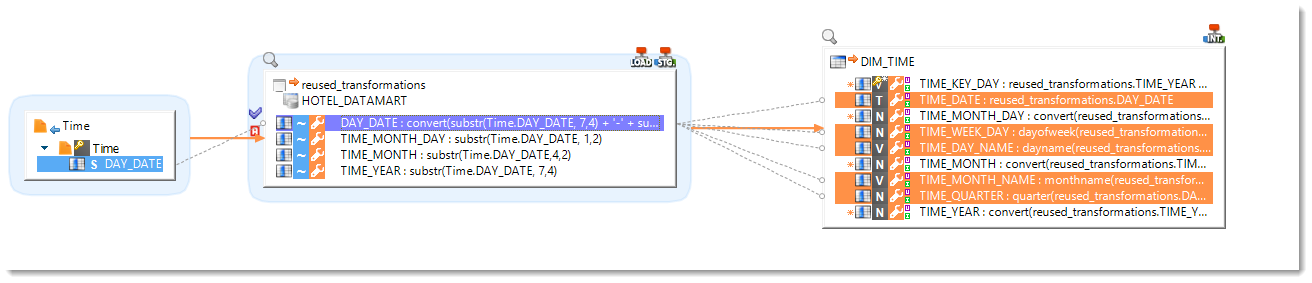
Stages allow to easily create Mappings from file to file.
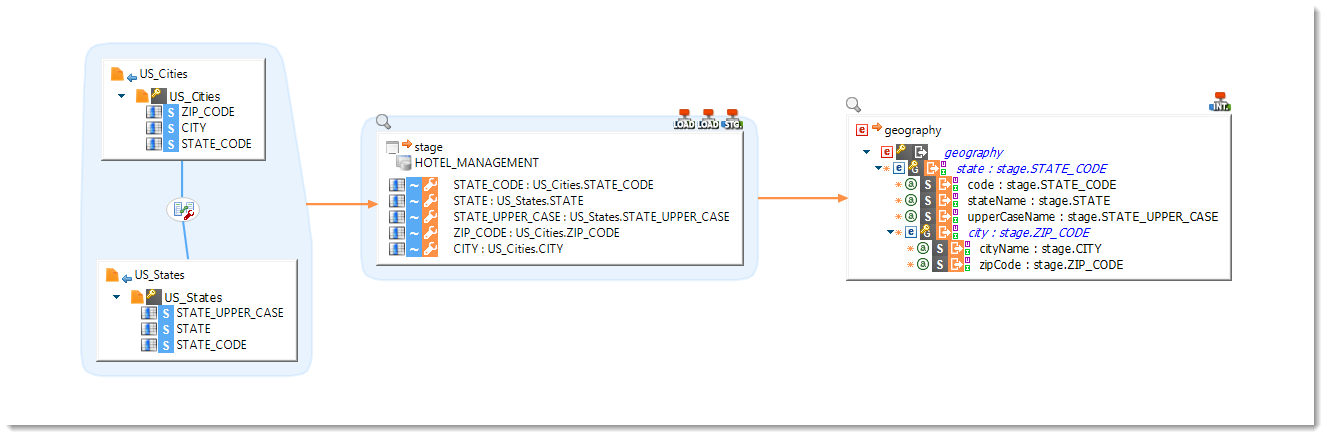
Stages can also be used to create on the fly temporary tables without having to reverse them.
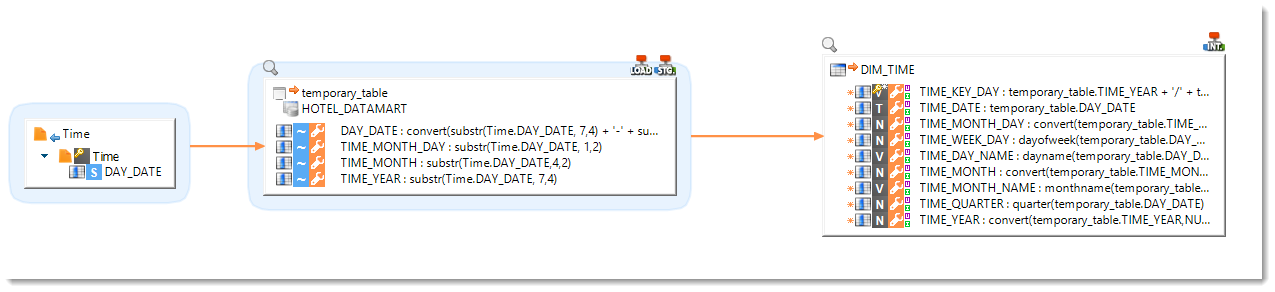
You can rely on Stages to optimize Mappings by pushing data to the source system before aggregation and save bandwith by reducing the total amount of data being transfered.
Optimizations
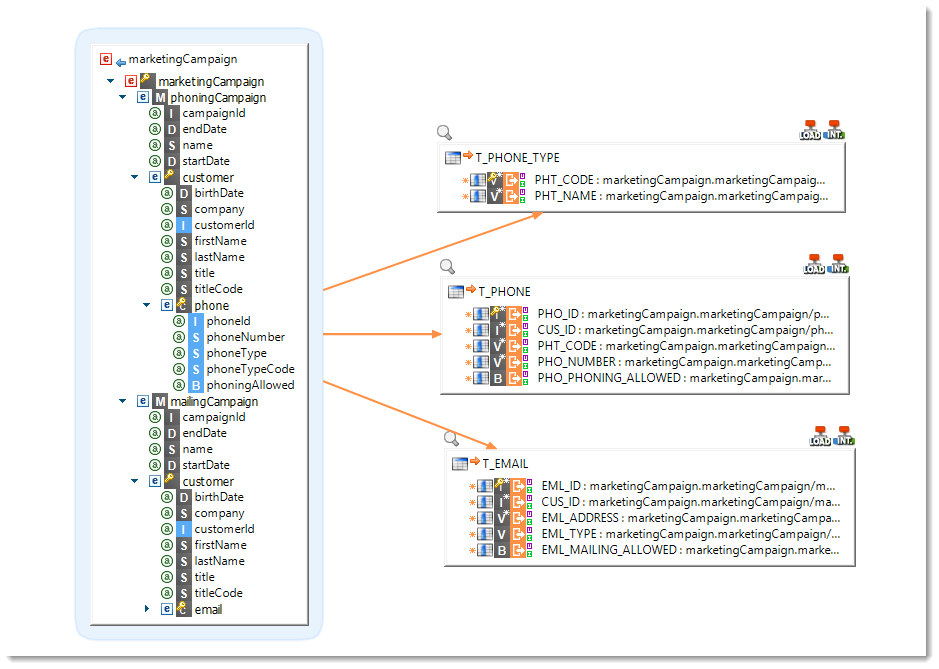
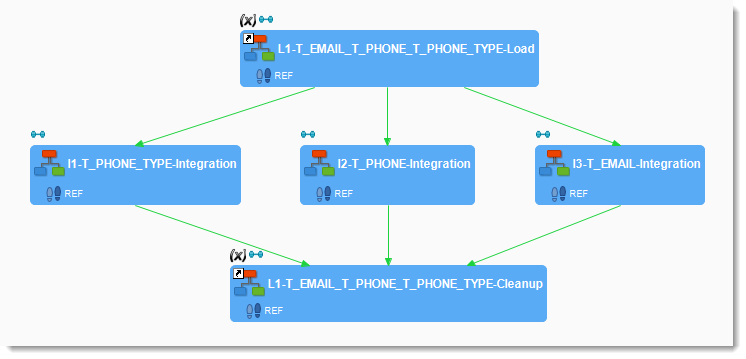
Mutualized loads
When Stambia detects that Load phases can be mutualized inside a Mapping it loads them once and reuses it for several targets. This is particularly useful to load an XML file into multiple targets.
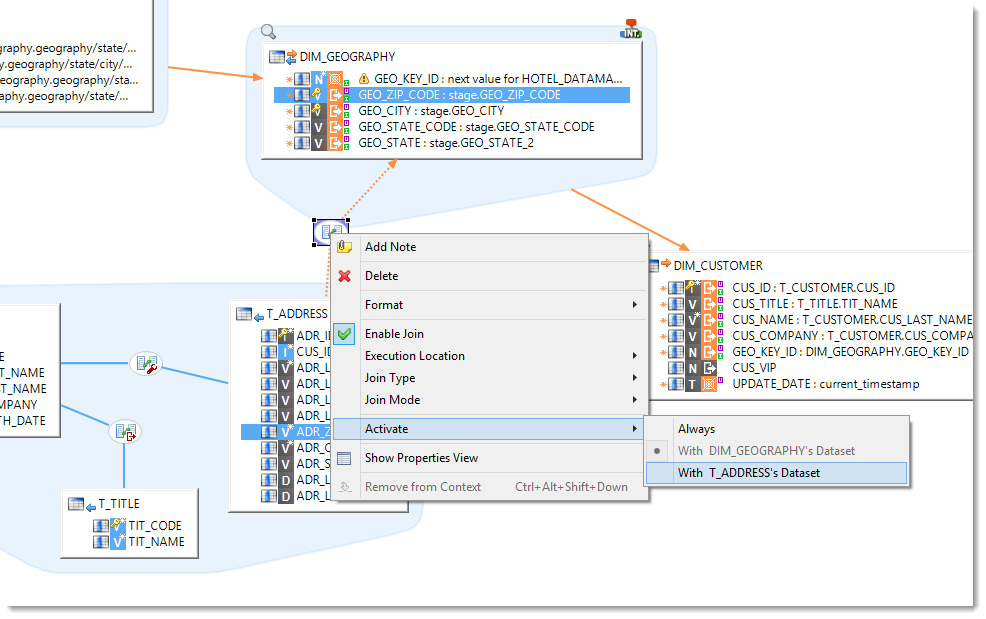
Conditional joins
A conditional join allows to split a dataset in two parts and allows to reuse one of them in another dataset. Not only this may drastically simplify your most complex mappings but this also allows you to load a sub-part of a dataset only once and reuse the result for integration into multiple tables.
Usability and productivity
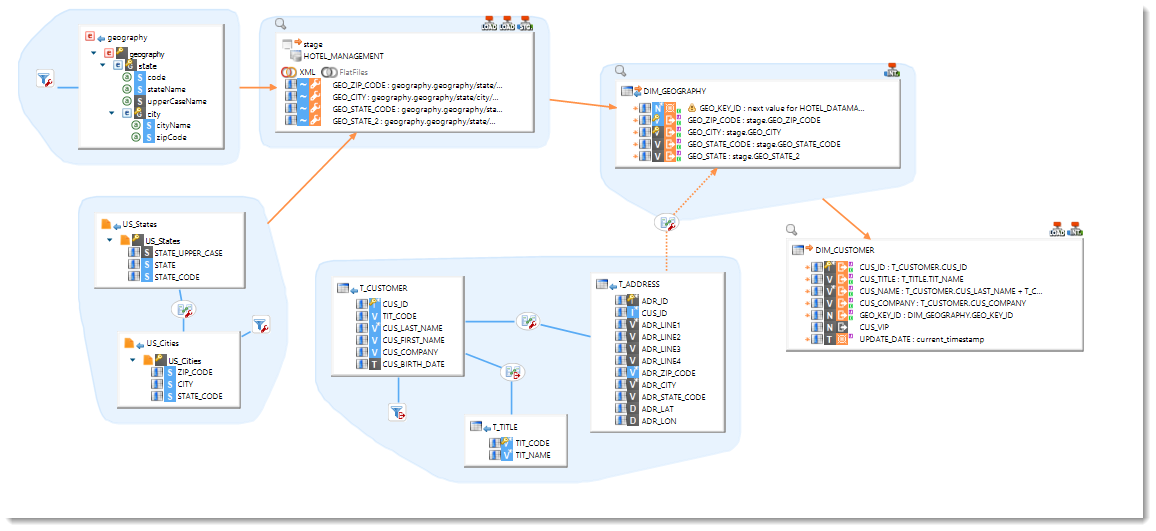
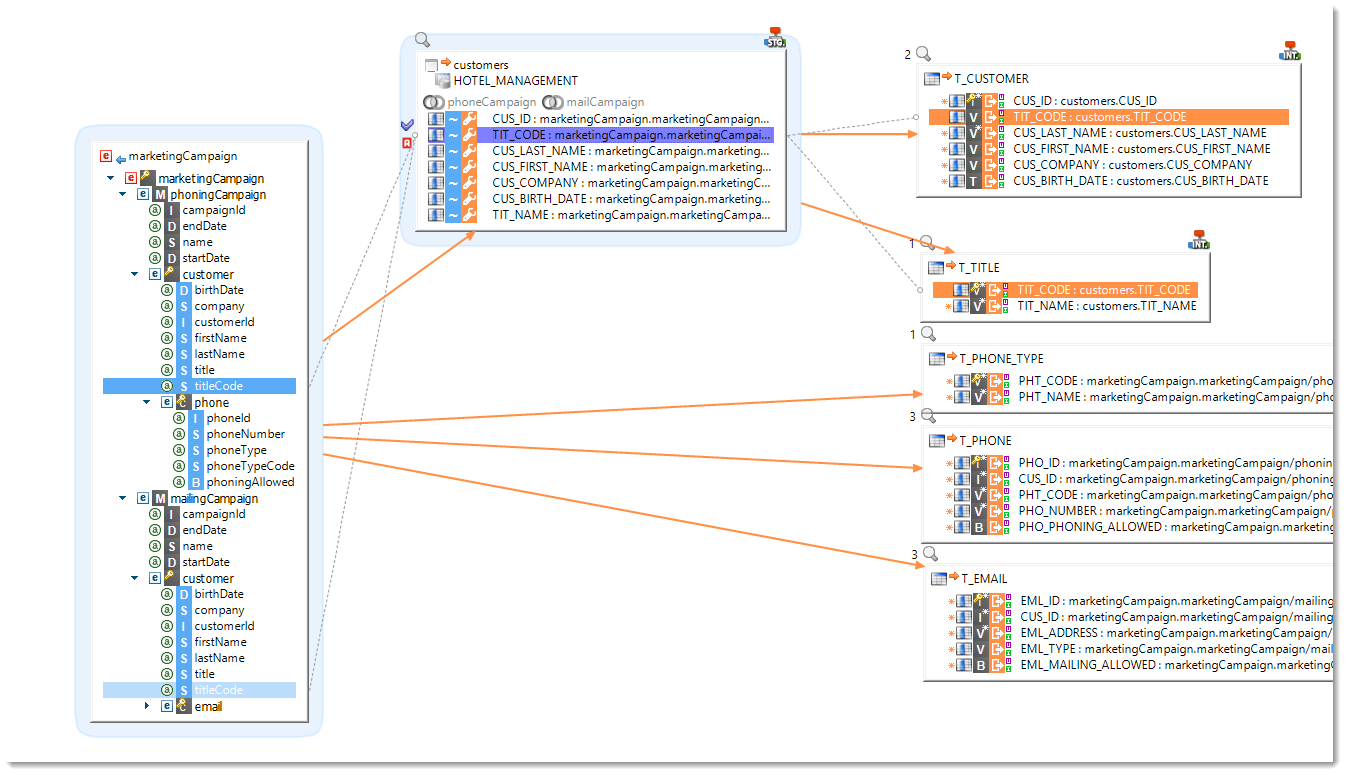
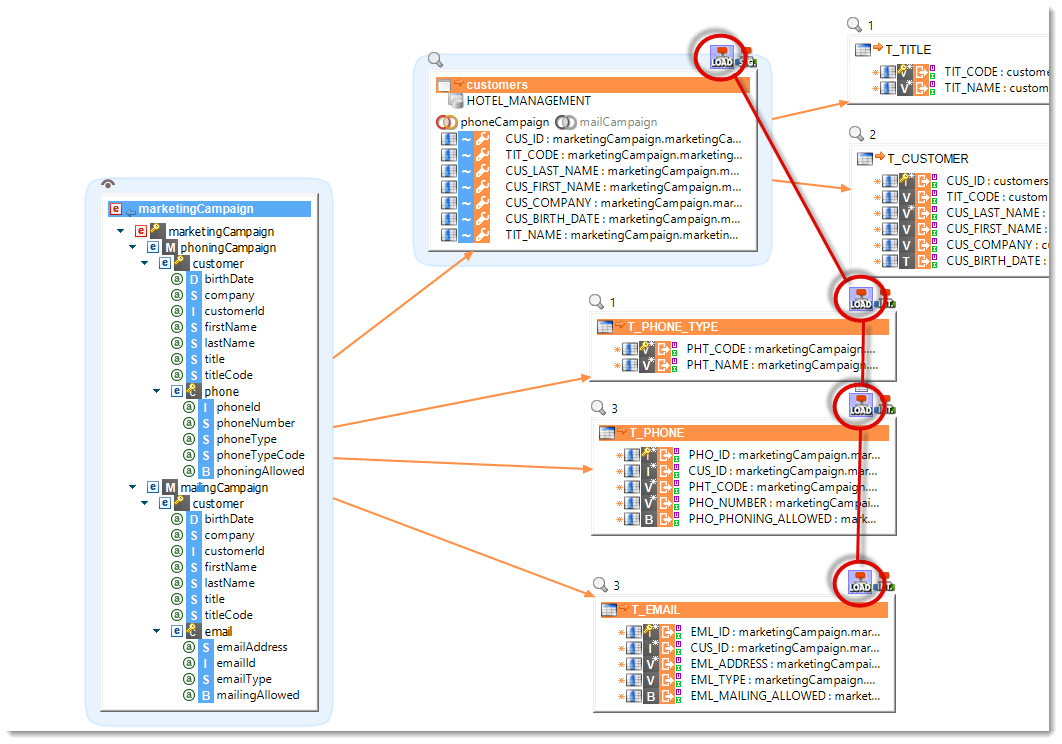
Datasets and Sourcesets
Stambia S18 introduces the notions of Sourcesets and Datasets which are materialized as blue areas in the Mappings grouping tables that participate to the integration into a same target. The orange links between these zones and their target datastores provide greater overall readability on the Mapping diagram.
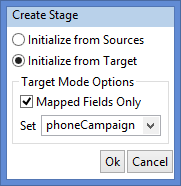
Easy creation of a Stage
The creation of a Stage on an existing Mapping can automatically take over existing transformations and push them to the Stage. This is particularly useful if you need to add a set-based operation on an existing Mapping.
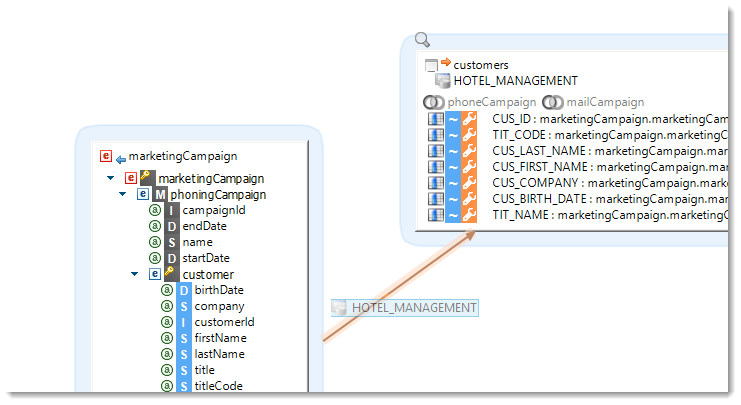
This features avoids the developer to recreate complex expressions. Of course, when deleting a Stage the expressions are automatically pushed to the target datastore in order to avoid loosing and having to redevelop them.
Data lineage
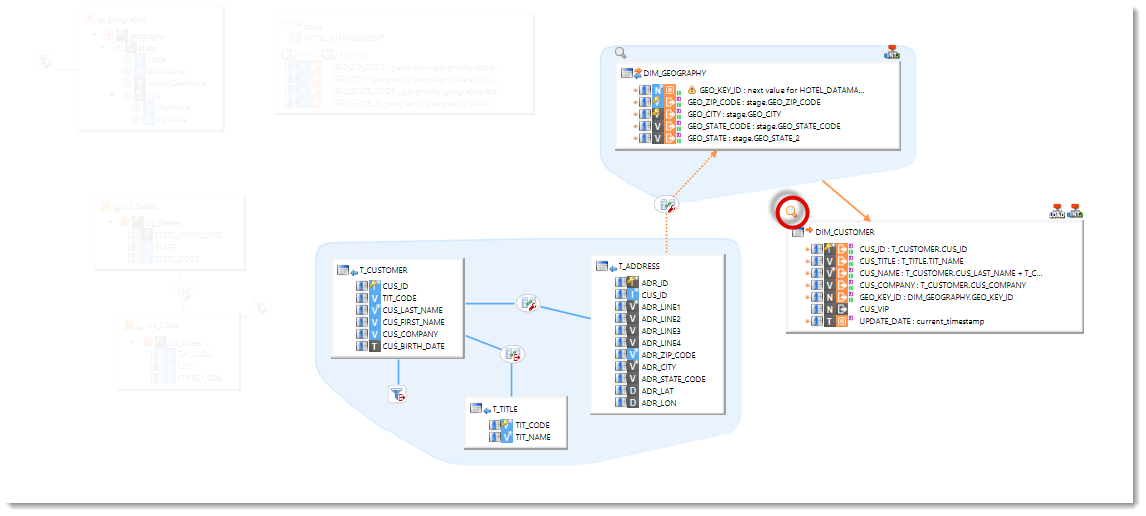
When selecting a column in a Mapping, dotted lines appear to show the data lineage from and to this column. It becomes very easy to perform impact analysis on a complex Mapping.
Highlight source tables
It is possible to highlight the possible sources and the current sources of a table and focus only on what is relevant when designing a complex Mapping.
Field selector
When working with large datastores you have the ability to hide part of the fields you are not interested in in order to focus only on the required fields.
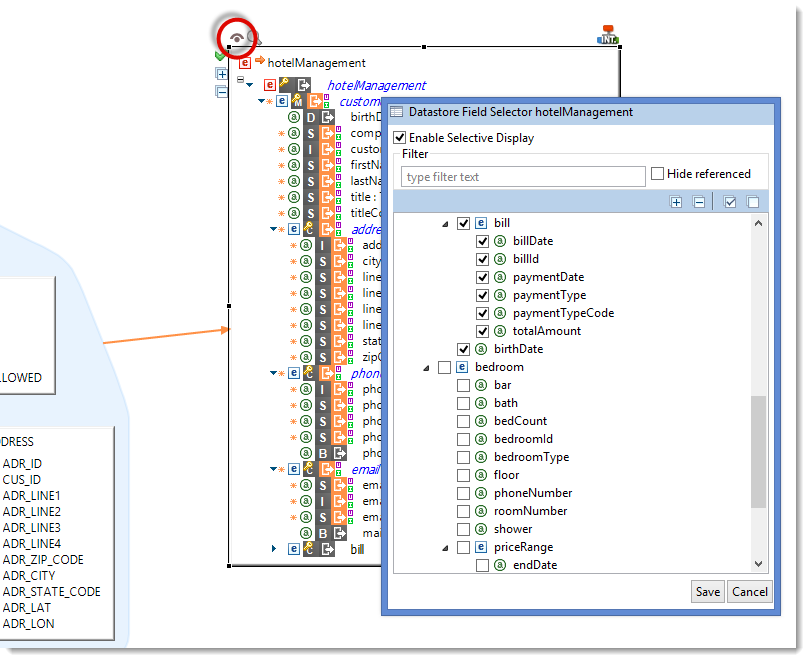
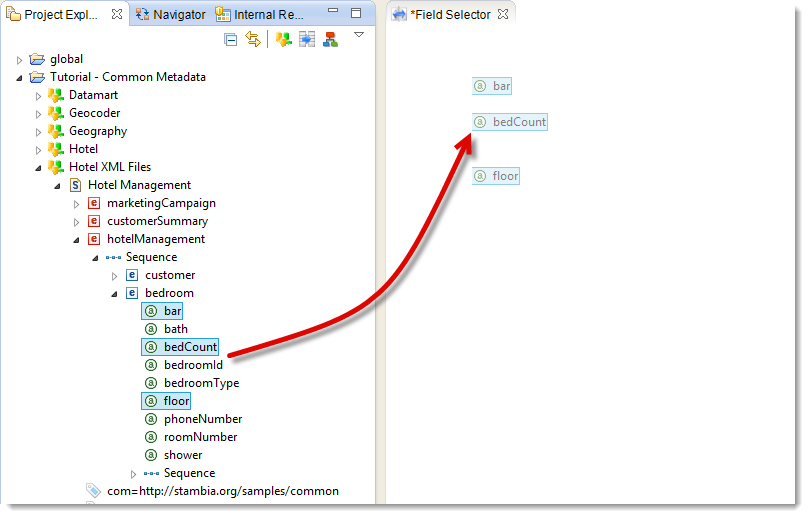
In order to improve even more your efficiency, you can drag and drop to the Mapping the fields you are interested in. This will add the datastore with a predefined Field Selector set to these fields.
Templates location
In a Mapping, the templates are now attached to their target datastore. Each template is having an icon on the upper right corner of the datastore.
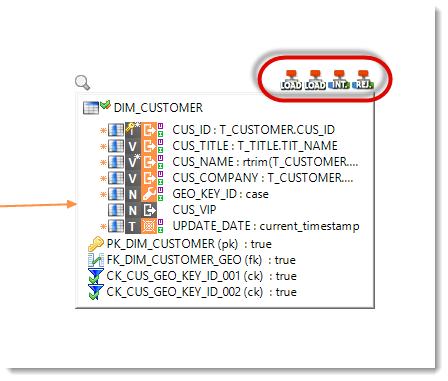
Furthermore, when you select the load template of a mutualized load, it is highlighted for each load that is part of this mutualization.
Other improvements
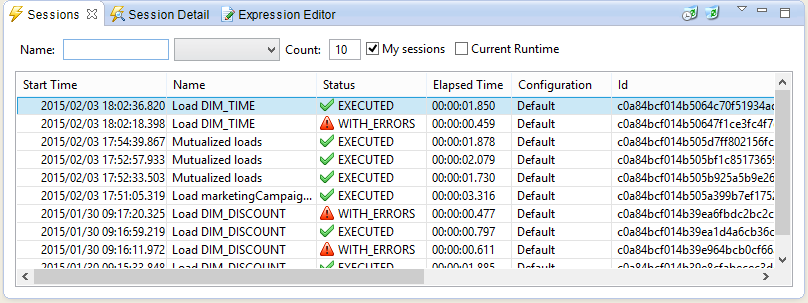
Double click on Sessions
Now, to open the Process corresponding to a Session, you can double click on the Session itself. If the corresponding Process (or Mapping) exists in your workspace it will be automatically opened.
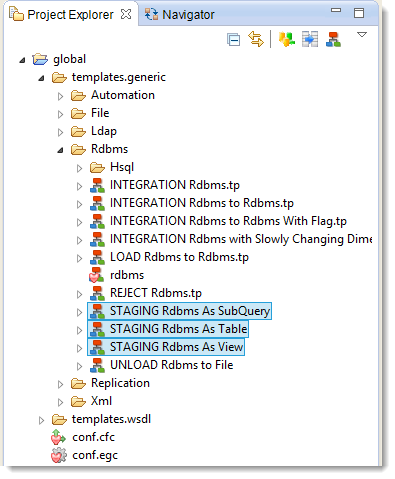
New template types
In order to support Stages a new type of template has been introduced: STAGING templates.
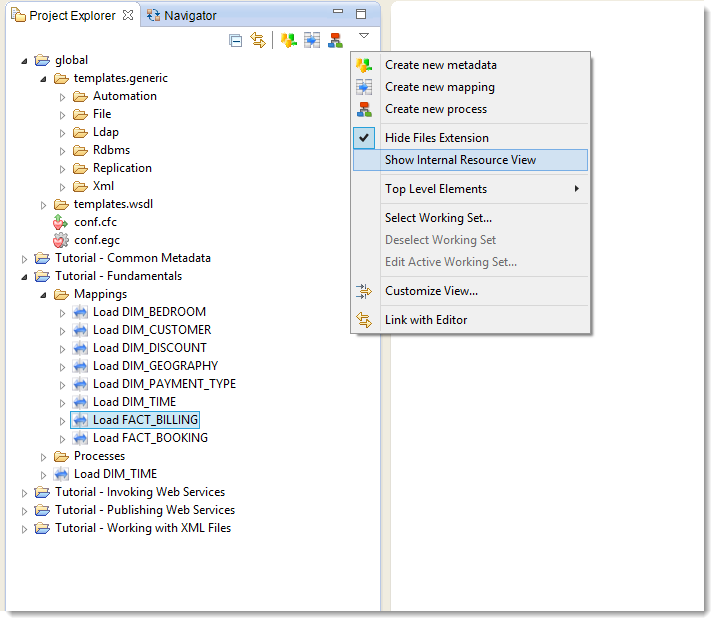
Internal resource
The ".tech" project has been replaced by a new "Internal resource" view. This view allows to navigate among the different technologies, and to import them into the workspace in order to customize them.
Incremental Build
Mappings are built continuously as a background process. It saves time when developping Mappings.
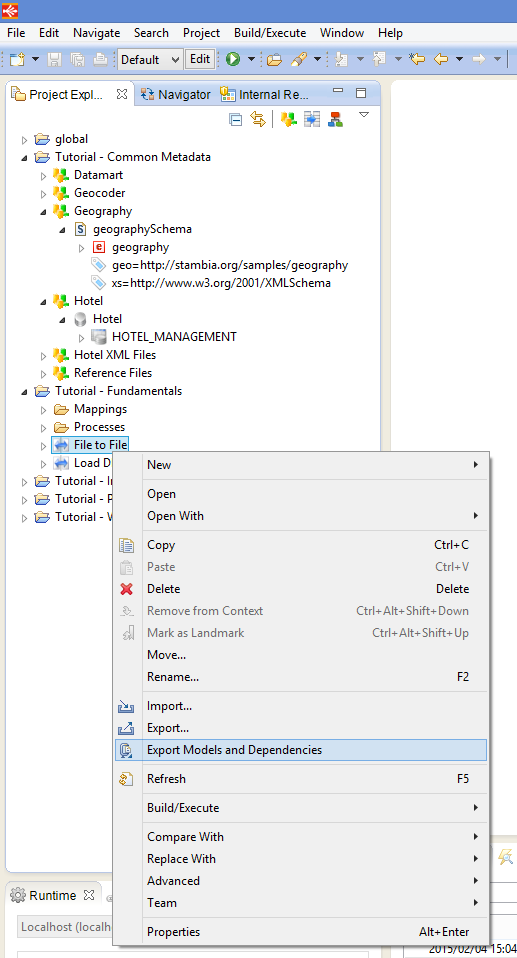
Easy Mapping export
When exporting a Mapping all the required objects can now be automatically retrieved. This will speed up your exchanges with your collegues and with our support team.