

Stambia Data Integration allows to work with Snowflake Databases, offering the possibility to produce fully customized Integration Processes.
In this article, you'll learn to reverse your first Metadata, optionally configure it to use external storages such as Microsoft Azure Storage or Amazon S3 and to produce Mappings or Processes.
The idea in our examples will be to load data from the demo HSQL Database, and from delimited files, to a Snowflake Database.
Refer to the presentation article for the download section and the list of supported features.
Prerequisites:
- Generic Templates
- Snowflake Connector
- Optionally Azure Connector
- Optionally Amazon Connector
Installation
The installation procedure is the following:
- Download and install Generic Templates in your workspace
- Download and install Snowflake Connector
- Optionally install the Azure Connector
- Optionally install the Amazon Connector
- Restart the Designer and Runtime
Metadata Configuration
Snowflake Database Metadata
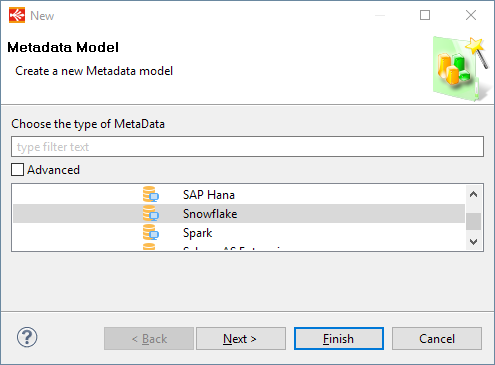
The first step is to create the Snowflake Database Metadata.
For this, simply create a new Metadata for Snowflake as you would usually do for any other database:
Here is an example of configuration:
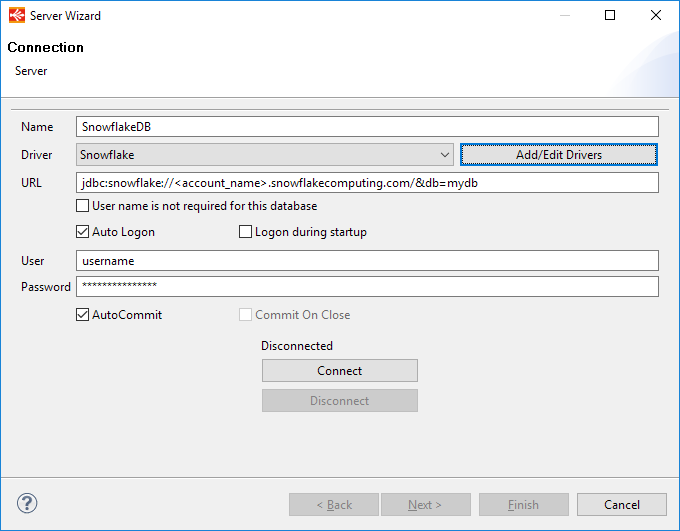
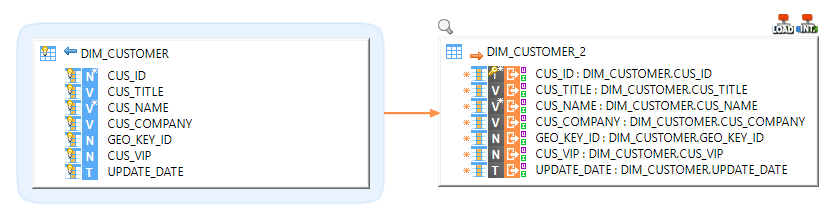
That's all, you can now connect and reverse your schemas and tables as usual.
If the wizard informs you that the JDBC driver class cannot be loaded, you must click on the "Add/Edit Drivers", find or create Snowflake Driver entry in the new window displayed and configure it as explained in this article.
The Snowflake Driver Class is "net.snowflake.client.jdbc.SnowflakeDriver".
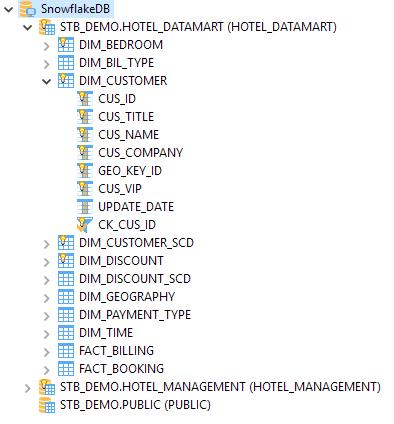
Here is an example of reversed Metadata:
About Internal and External Storage
For optimizing data loading into Snowflake Stambia Templates goes through internal or external storage to temporarily store data as file before loading it.
The idea is to first extract source data to be loaded into Snowflake in file, store it on a storage Snowflake can access, and finally load data into Snowflake from the storage.
This also work for loading flat files into Snowflake.
Actually, the Templates support the following storage providers:
- Internal Snowflake Stage
- External Storage
- Microsoft Azure Storage
- Amazon S3
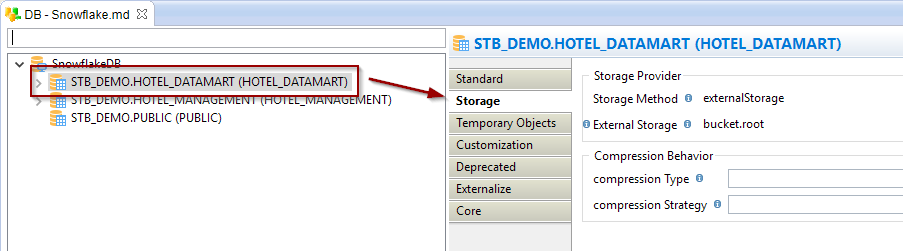
Defining Storage in Metadata
Storage information are defined in Metadata, which allows to specify the default storage type to be used when working with this Metadata, and also necessary information about the external storage which should be used.
On Metadata server node, go into 'Storage' tab and define here the 'Default Storage Type' and 'External Storage' attributes:
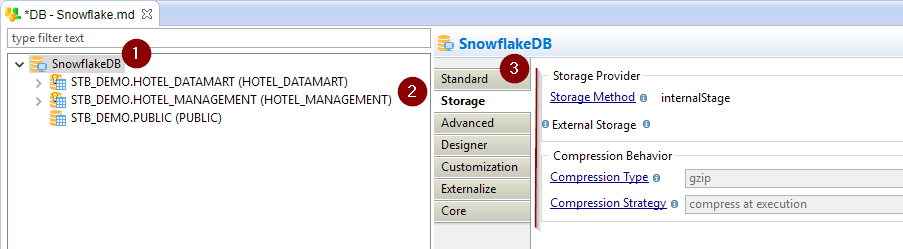
Below is some information about those attributes:
| Attribute | Description |
| Storage Method |
Storage Method used by default in Mappings loading data into Snowflake.
Note that this will be default method for all schemas and tables of the Metadata. |
| External Storage |
Metadata link of the external storage container to be used when using external storage. Drag and drop here a Microsoft Azure Storage Container or Amazon S3 Folder. This is not necessary if you only plan to use internal stage storage type. Note that this will be the default for all the schemas and tables of the Metadata. |
| Compression Type | Defines the compression type used when loading files (source files or temporarly generated files) into this database. It can be overridden on schemas and tables if needed. |
| Compression Strategy |
Defines how compression behavior when loading files (source files or temporarly generated files) into this database. It can be overridden on schemas and tables if needed. - compress at execution: use this option when you want Stambia to compress files which are sent to Snowflake during flows automatically during execution. - delegate compression to driver: use this option when you want the compression of files which are sent to Snowflake during flows to be performed automatically by the Snowflake driver, using the 'AUTO_COMPRESS' option supported on the 'PUT' statement. - assume already compressed: use this option when source files have already been compressed before the execution of Mappings. |
Those attributes can be overridden per schema and per table easily: for this simply go on the desired schema or table node, then go inside the 'Storage' tab where you'll find the same attributes, which will override the value set on the parent nodes.
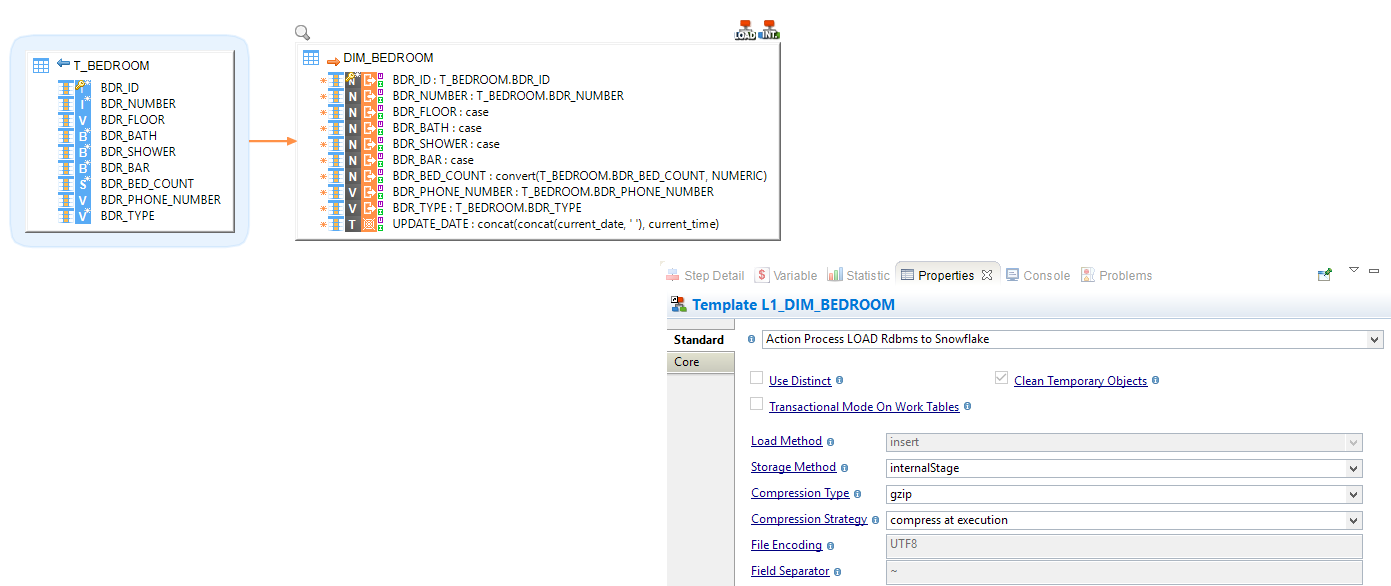
The storage method and compression behavior can also be overridden directly in Mappings through parameters on Stambia's Snowflake Load Templates, allowing to manually define a different behavior than specified in Metadata for each Mapping.
'External Storage' is not linked to 'Default Storage Type'. You can decide to use 'internalStage' storage type by default but provide an External Storage link for specific cases where you'll override the default storage type. (For instance, forcing externalStorage on a specific Table or in a specific Mapping.)
Defining External Storage
To define External Storage simply drag and drop Microsoft Azure Storage Container or Amazon S3 Folder on the attribute:

Overriding Storage configuration
As indicated previously storage attributes can be overridden on schema and table nodes, and also directly in Mappings.
Example of override on schema node:
Example of override in Mapping:
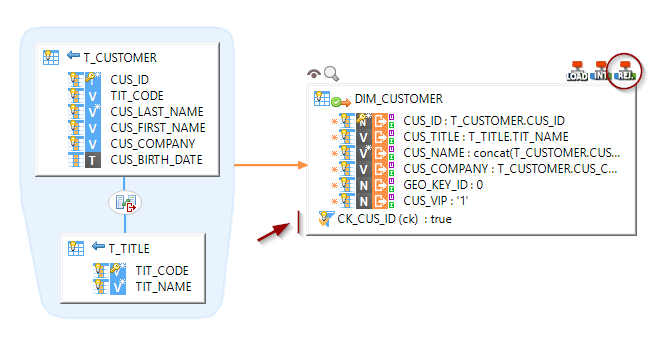
Creating your first Mappings
Your Metadata being ready and your tables reversed, you can now start creating your first Mappings.
Snowflake technology in Stambia is not different than any other database you could usually use.
Drag and drop your sources and targets, map the columns as usual, and configure the templates accordingly to your requirements.
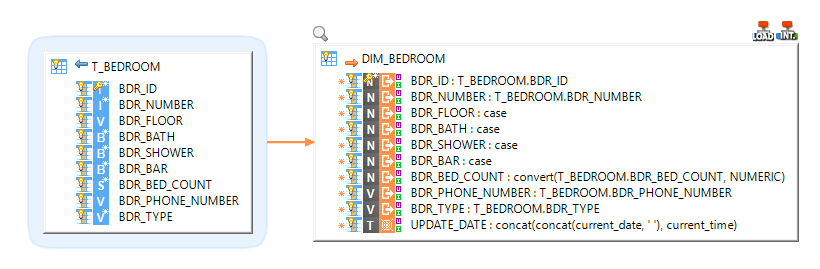
Loading data from a database into Snowflake
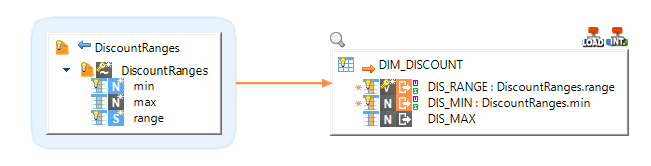
Loading data from a Delimited File into Snowflake
Loading data from Snowflake into another database
Performing Reject detection while loading a Snowflake Table
Replicating a source database into Snowflake

Demonstration Project
A Snowflake demonstration project can be found on the download page. It contains examples to illustrate the features.
Do not hesitate to have a look at this project to find samples and examples.