

This article describes the principal changes of Hadoop Templates.
The Template download section can be found at this page and Hadoop section at this page.
Note:
Stambia DI is a flexible and agile solution. It can be quickly adapted to your needs.
If you have any question, any feature request or any issue, do not hesitate to contact us.
This article is dedicated to Stambia S17,S19 or S19.
If you are using Stambia DI S20 or higher please refer to this article.
Templates.Hadoop.2020-06-26
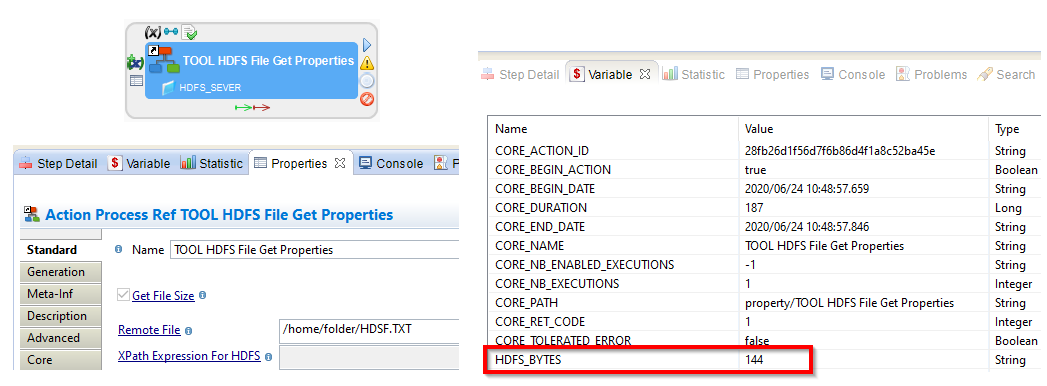
New HDFS Tool
Adding a new tool: Tool HDFS File Get Properties, which allows to retrieve information about files.
For this first version it allows to retrieve the size of a remote file.
The size will be stored in the process variable “HDFS_BYTES”.
Fixed issue about WebHDFS mode and files with space character
There was an issue when trying to manage HDFS files through WebHDFS mode, when the files has a space character in file name.
This is now fixed.
Templates.Hadoop.2020-04-30
Load XML To Hive
New Template
A new dedicated Template to load XML data to Hive has been added.
This new Template offers the ability to load XML data into Hive through HDFS for efficiency and to benefit of Hadoop cluster resources.
HDFS Tools
Retrieve all SSH settings from Metadata when using SSH Mode
When using HDFS Tools through SSH Mode, all the SSH settings from SSH Metadata are now retrieved to perform the operation.
Some settings such as proxy information or private key information were not retrieved.
Integration Rdbms to HBase
Fix issue with datatypes
When loading data from a database into HBase, matching between source and target datatypes was not done properly.
All data was therefore considered as string data which could cause issues in some situations.
The Template is now properly retrieving and handling datatypes information.
Templates.Hadoop.2019-12-03
HDFS Tools
Ability to manually define how server and API information are retrieved
A new parameter has been added on HDFS tools to manually define how server and API information are retrieved.
As a reminder, they were automatically retrieved from Metadata Links or from the involved models when used through Mapping Templates.
This new parameter, which is called "XPath Expression for HDFS" will help to make HDFS tools reusable more easily in other Templates and tools.
Fix SSH connection method
When using SSH mode for performing HDFS operations, some information from corresponding SSH Metadata such as Proxy Information, Timeout, and Private Key file, were not used by the tools.
HDFS tools have been fixed to use all SSH information available in corresponding SSH Metadata.
Hive Product
Fix DECIMAL datatype mask
DECIMAL datatype mask was not computed properly in some situations.
The mask which is used to create columns with this datatype in temporary tables and objects was not correct.
It has been fixed in this version.
Templates.Hadoop.2019-02-08
INTEGRATION Hive and INTEGRATION Impala
Recycling of previous rejects fixed
When using the option to recycle the rejects of previous execution an extra step is executed to add those previous rejects in the integration flow.
Possible duplicates while retrieving those rejects are now filtered using DISTINCT keyword.
Templates.Hadoop.2019-01-17
TOOL HBase Operation
HBase Operation tool now supports performing snapshot operations on HBase.
Three new operations have been added to take, restore, or delete a snapshot on HBase.
Templates.Hadoop.2018-09-18
hive.tech and impala.tech
Previous versions of the Stambia Hive and Impala technologies had a mechanism that automatically added some of the required kerberos properties in the JDBC URLs.
Such as the "principal" property for instance, which was retrieved automatically from the kerberos Metadata.
This was causing issues as the client kerberos keytab and principal may be different than the Hive / Impala service principal that needs to be defined in the JDBC URL.
- To avoid any misunderstanding and issue with the automatic mechanism, we decided to remove it and let the user define all the JDBC URL properties.
- This does not change how to use kerberos with Hive and Impala in Stambia, but simply the definition of the JDBC URL that must be done all by the user now.
We also updated the Hive and Impala getting started articles accordingly to give indications about what should be defined in the JDBC URL when using kerberos.
Notes
If you were using kerberos with a previous version of the Hadoop Templates, make sure to update the JDBC Urls of your Hive and Impala Metadata.
Examples of the necessary parameters are listed in the getting started articles.
For history, the parameters which were added automatically were the following AuthMech=1;principal=<principal name>
Make sure the JDBC URL correspond to the examples listed in the articles.