

Stambia Data Integration allows to work with Microsoft Azure SQL Databases, offering the possibility to produce fully customized Integration Processes.
In this article, you'll learn to reverse your first Metadata, configure it to use Microsoft Azure Storage, and produce Mappings or Processes using it.
The idea in our examples will be to load data from the demo HSQL Database, and from delimited files, to an Azure SQL Database.
Refer to the presentation article for the download section and the list of supported features.
Prerequisites
A master key must exist in the target Azure SQL Database.
This is required as the load template will initialize credentials in the database to connect to the Azure Blob Storage, which require that a master key exist in the Database.
Refer to Microsoft documentation to learn how to create one:
https://docs.microsoft.com/en-us/sql/t-sql/statements/create-master-key-transact-sql
Installation
The installation procedure is quite simple:
- Download the Generic, Specific, and Azure templates and import them in your workspace
- Install the Microsoft Azure Storage Java libraries in the Runtime (see this article).
- Install the Microsoft SQL Server JDBC library (sqljdbcxx.jar) in the stambiaRuntime/lib/jdbc/ folder of the Runtime (S17, S18, S19) or in the module subfolder (S20).
- Restart the Runtime after having installed the libraries
Metadata Configuration
Azure SQL Database Metadata
The first step is to create the Azure SQL Database Metadata.
For this, simply create a new Metadata for the Azure SQL Database as you would usually do for any other database:
Here is an example of configuration:
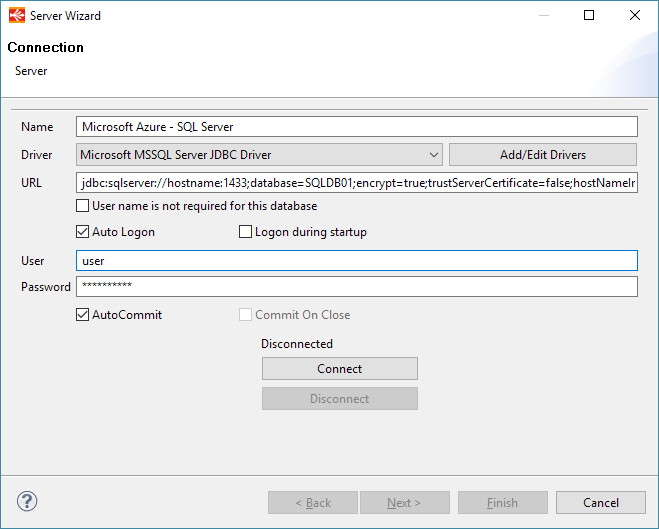
A few notes:
- The Microsoft MSSQL Server JDBC Driver must be used
- The complete JDBC URL of the Azure SQL Database must be used. You can find it on the Azure portal, as explained in this Microsoft article.
That's all, you can now connect and reverse your schemas and tables as usual.
Azure Storage Metadata
To load data into Azure SQL Databases, the idea is to first send it as a file on an Azure Storage Container, and then load it with the help of the BULK INSERT statement.
This is, in most cases, way faster than using direct JDBC loading that can be slow when trying to connect to cloud databases like Azure ones.
Therefore, our Azure templates are designed to use this method and so require to have an available Azure Storage to send data in.
Refer to this article to learn how to create an Azure Storage Metadata.
For instance:

The container doesn't have to exist on the storage, the templates allow to create it automatically in case it doesn't.
Making the two Metadata work together
Now that we have our Azure SQL Database and Azure Storage Metadata, we must specify that the database should use the container we defined when loading data.
To accomplish this, just drag and drop the container from the Project Explorer in the Azure SQL Database:
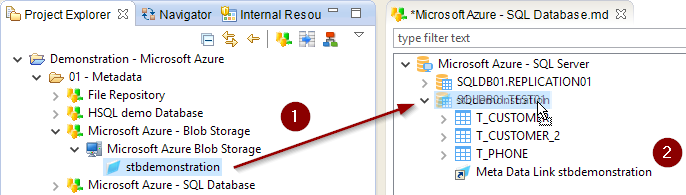
Depending on if you want to re-use it on several tables or schemas, drag and drop it on the desired node.
In our case, we want it to be available for all tables so we put it on the schema.
Finally, rename the Metadata link that is created to TARGET_AZURE_CONTAINER:
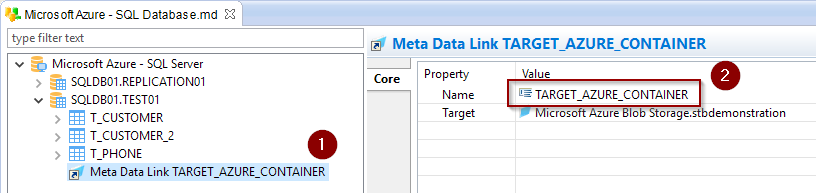
This is required as the template will search for a Metadata Link named like this on the target Azure SQL Database, to know where to store the temporary file.
That's it, we are now done configuring our Metadata and we can start developing our Mappings.
Loading data from a database into an Azure SQL Database
Developing Mappings to load data into an Azure SQL Database is no different than your usual developments.
Drag and drop your source(s) and target(s) tables and map the fields as required:
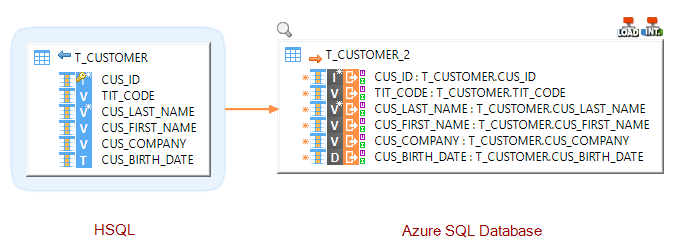
Make sure to use the LOAD Rdbms to Azure SQL Database load template
Loading data from a file into an Azure SQL Database
As for loading data from a table, loading data from a file is exactly as usual.
Drag and drop the source file and target table in your Mapping and map the fields:
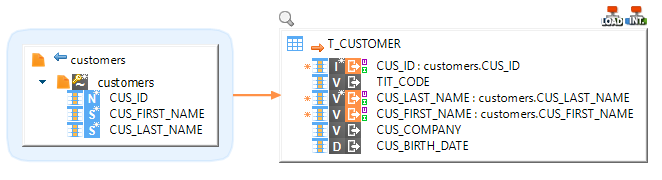
Make sure to use the LOAD File to Azure SQL Database load template:
Demonstration Project
The Azure demonstration project that you can find on the download page contains examples to illustrate the features.
Do not hesitate to have a look at this project to find samples and examples.