

Introduction
Twitter is the most used social media platform to express views and tweet statuses. Gaining an insight on the data is one of the areas of interest for organizations. Getting data like the current trends, searching tweets, users etc. can provide very useful information.
Stambia Data Integration enables users to quickly get connected to Twitter API and use all the REST APIs made available by Twitter. Data can be easily pulled from and pushed to twitter using simple mappings.
Pre-requisites
-
Create an application on https://apps.twitter.com
-
Download Twitter API metadata from http://stambia.org
-
Templates Required – Generic & WSDL
Configure Twitter API Metadata (OAuth)
Import the metadata packages downloaded from http://stambia.org into your project.
Right Click on the Project >> Import>>Archive File>>Browse the file>>Click OK
Once imported, you can double click on the metadata link to see the types of requests and their properties.
An additional step for Oauth configuration is required for authentication and authorization. The application created on https://apps.twitter.com will provides a Consumer Key and Consumer Secret. Using that, a Token Key & Secret would be created.
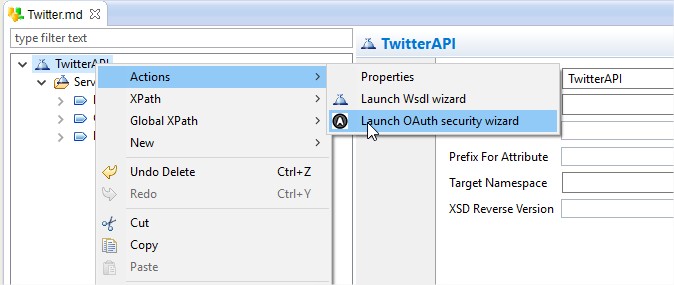
Right Click on the TwitterAPI, then Select Actions and click on Launch OAuth security wizard.
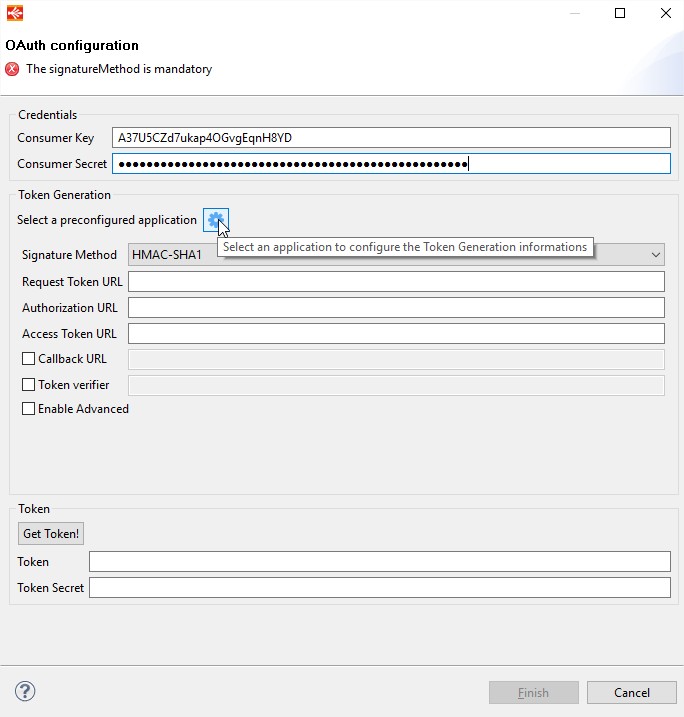
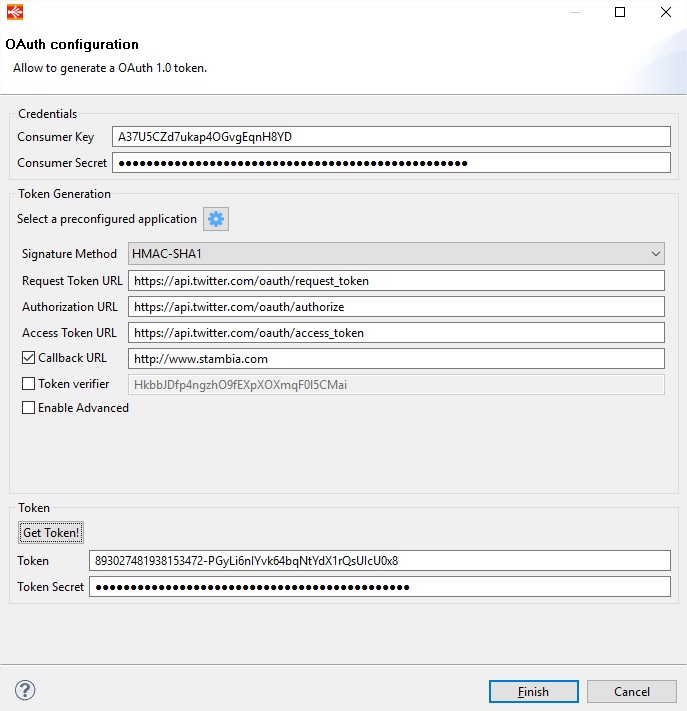
This will launch the wizard and you can provide the Consumer Key & Secret. Then Click on application selection button as shown below.
Select Twitter as the application.
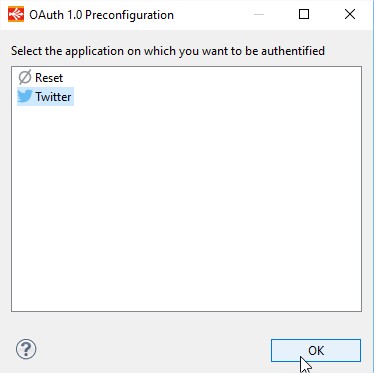
Provide the Callback URL and then Click on Get Token!
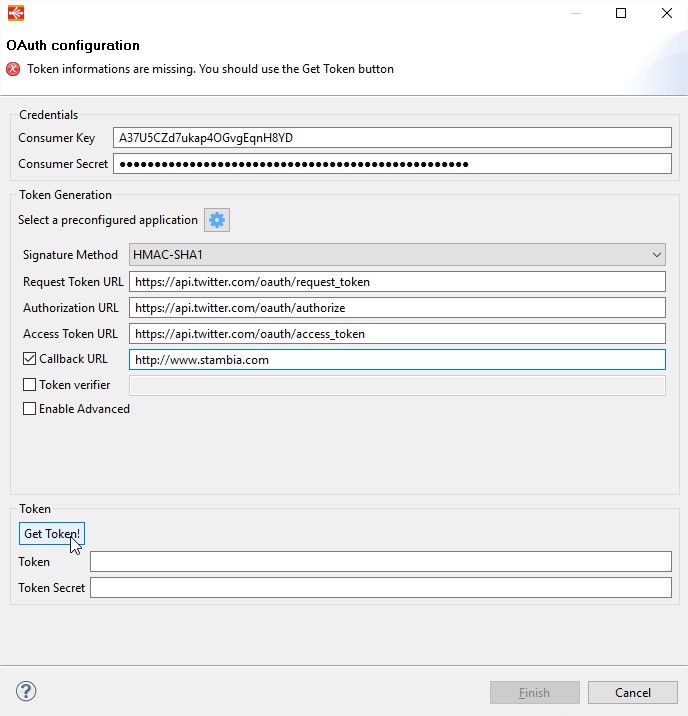
You should see a popup from twitter app for authorization. Authorize app to generate the Token.
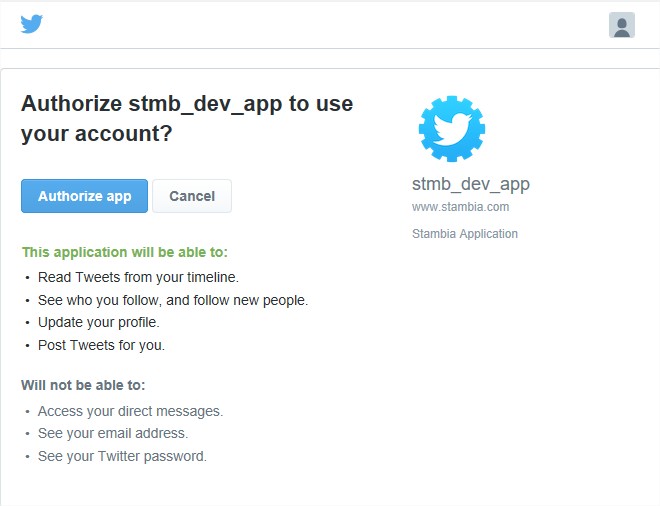
The Token and Token Secret is generated and configured in the wizard.
Browse through all the GET, POST & DELETE requests. View the properties and modify them if required. For e.g. below list of GET request can be reduced, by keeping just the request needed for a project and deleting everything else.
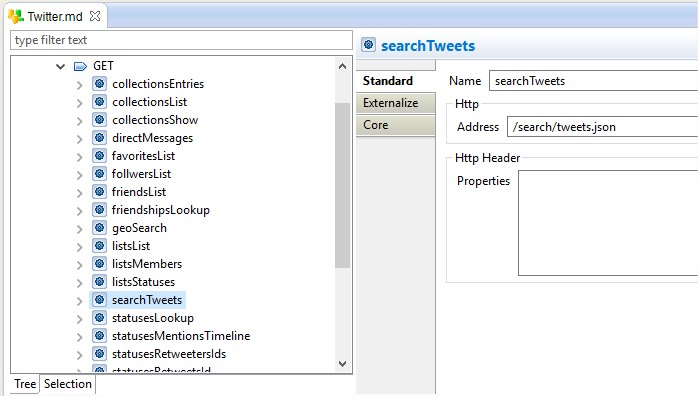
As well the metadata inside these requests can be viewed and modified. This would be a standard format of Input Parameters and Response JSON structure : -
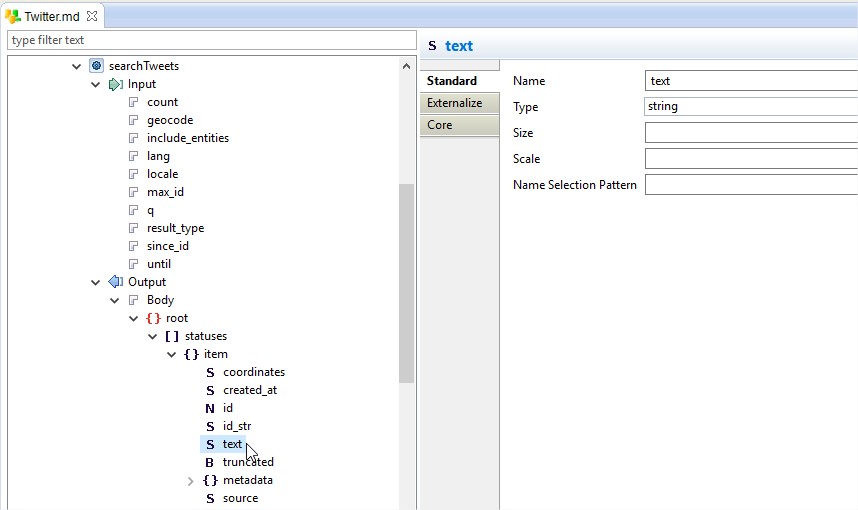
Working with Mappings
Once the metadata is set-up, we can work on some mapping to pull data out of Twitter.
As an example, we can get the current trending topics in all the regions and then using their WOEID pull out top 50 trending topics and the volume of tweets for each topic : -
For this we need to use two requests : -
trendsAvailable – No Input Parameters required. Gives all the trending topics for a region and the region’s WOEID.
trendsPlaces – Input WOEID to get the top 50 trending topics and the tweet volume.
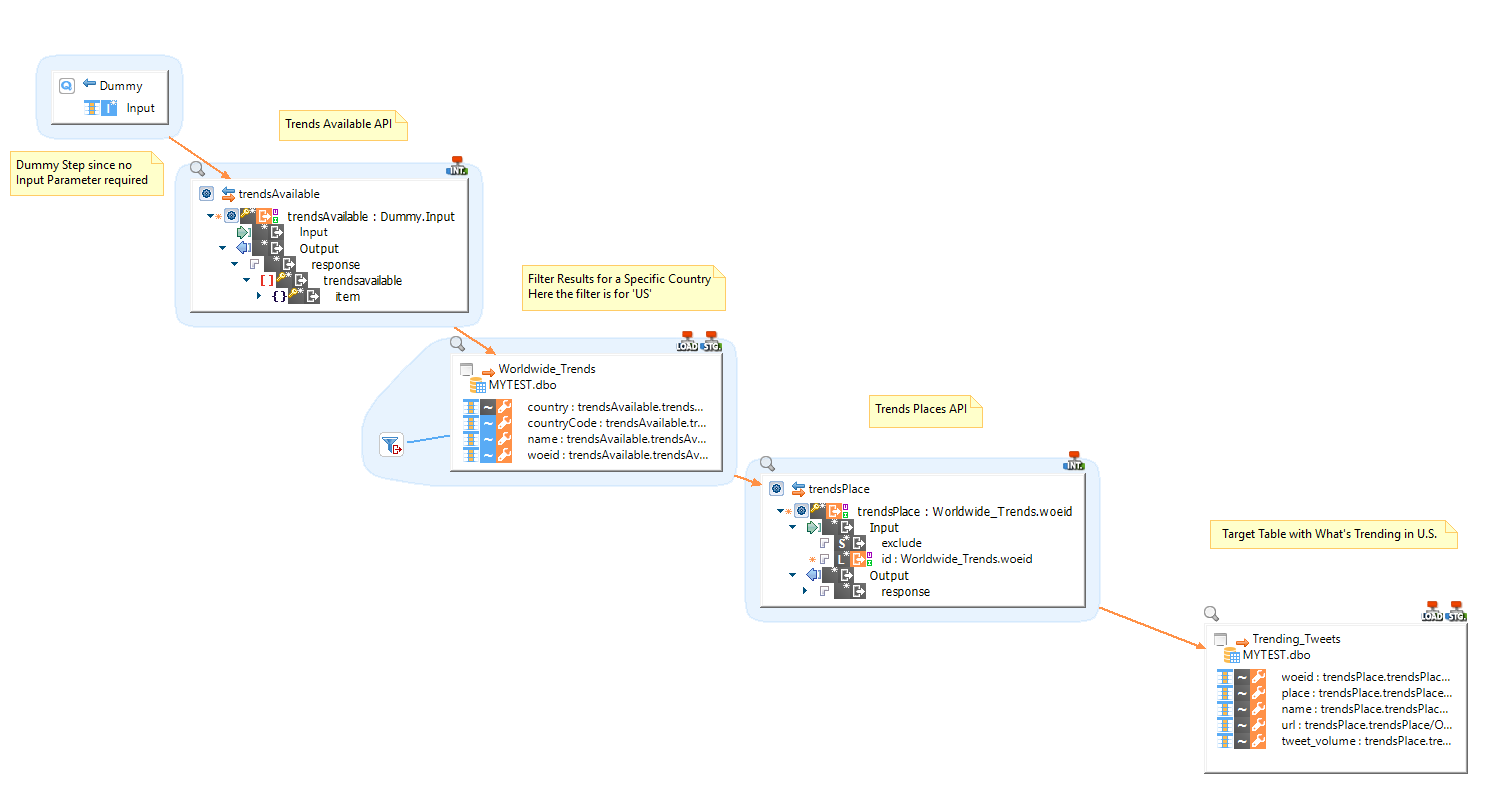
In a single mapping, we execute two GET requests connected to each other and get the data out of Twitter into a RDBMS staging table.
In cases where a huge amount of data must be moved to Hadoop for analytics, Hadoop templates can be used to push this data. The data can be processed in Spark and results can be put in a Hive Table.
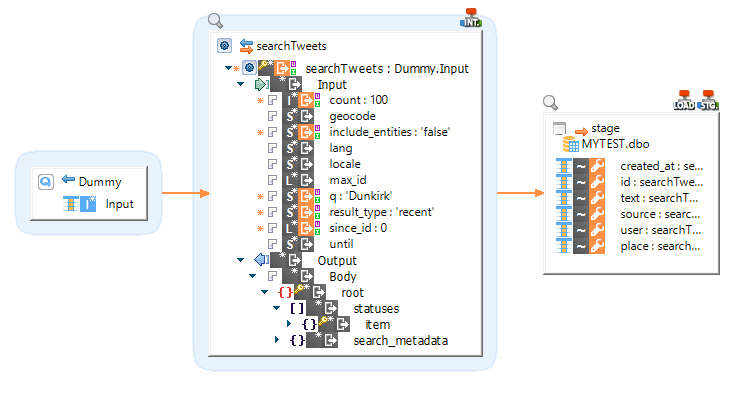
Use search Tweets Request to search keywords used in the tweets and then move the data to HDFS.
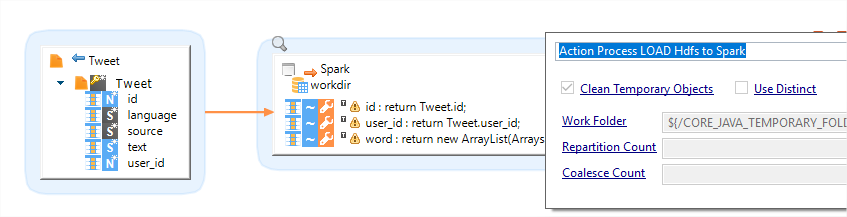
Once the file has been moved to HDFS, this can be processed in Spark.
Additionally, you can use the other request from Twitter like POST, DELETE etc.
Make sure you have the Read and Write permission on the Token.