In this article
You can find below the major changes and improvements of the S18.1.x version.
Note:
This article only highlights the most important changes.
If you need further information, please consult the full changelog and/or reference documentation.
What's new in 18.1.0?
Breadcrumb Trail
S18.1 improves the usability of processes with the addition of a breadcrumb trail at the top of processes to navigate in the sub-processes:
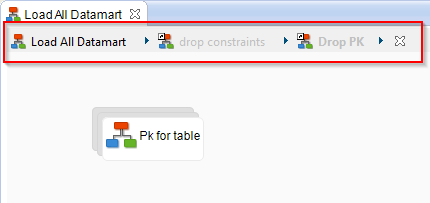
By default, only the main process editor can be edited (main process and sub-processes created inside).
All process links (Mappings, reference to other processes, ...) are read only, to prevent modification of other processes by error.
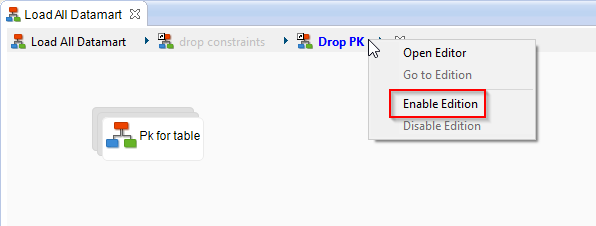
To enable the edition:
- Right click on a sub-process on the breadcrumb trail and click on Enable Edition. This will enable the edition directly inside this process.
- Right click on a sub-process on the breadcrumb trail and click on Open Editor. This will open a new editor for the selected sub-process.
Computed Fields
Computed fields are virtual fields, which are calculated on the fly during execution. They are only evaluated during execution and are not stored in the temporary objects (tables, views, etc):
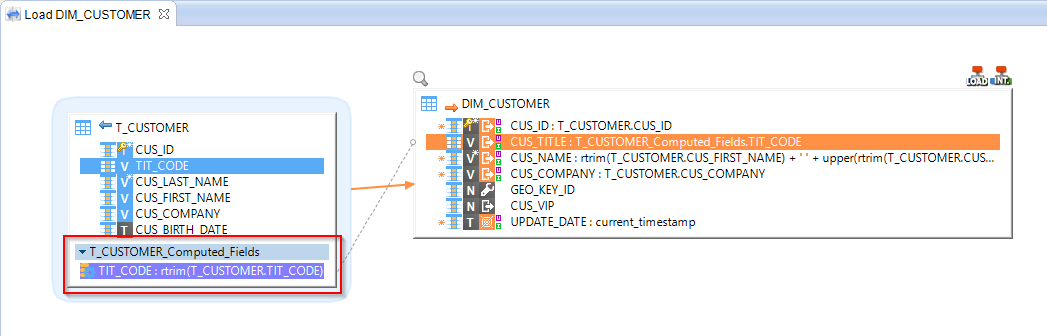
To create a computed field on a mapping:
- Right-click on a column and select Create ComputedField
- A name for the container of the computed fields will be asked for the first created on the datastore.
- Finally, you can change the expression of the computed field to your needs.
Note :
- Computed fields can be created only on objects having transformation capacities (RDBMS mostly, with SQL syntax)
- It is possible to create a computed field from an other computed field too. This is usefull to chain transformations or operations.
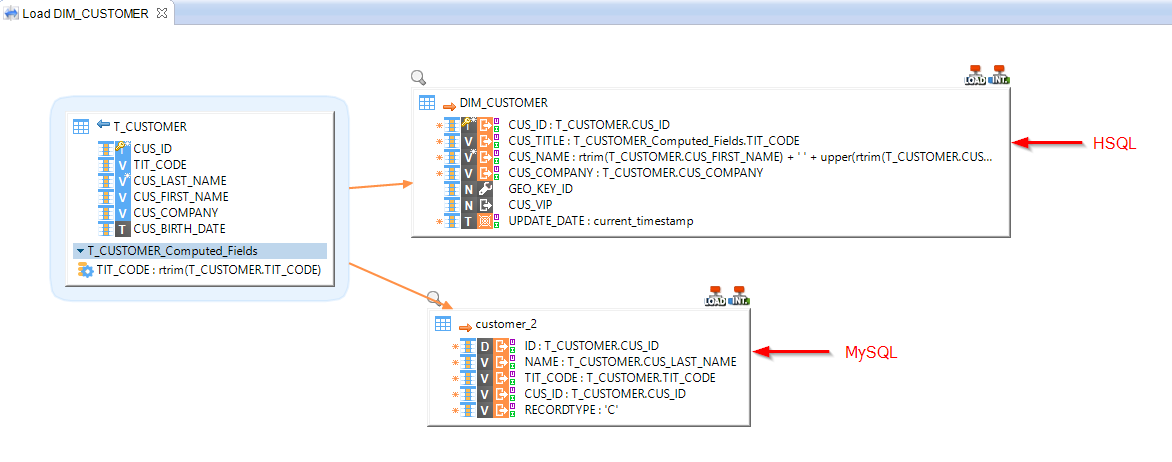
Multi-connection target datastores
It is now possible for target datastores having the same source to be on different connections:
Search tool
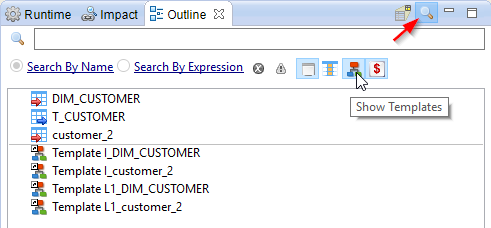
A new search tool has been added in the Outline View. It offers the possibilty to search in mappings and processes and access easily to their objects:
Target Filters
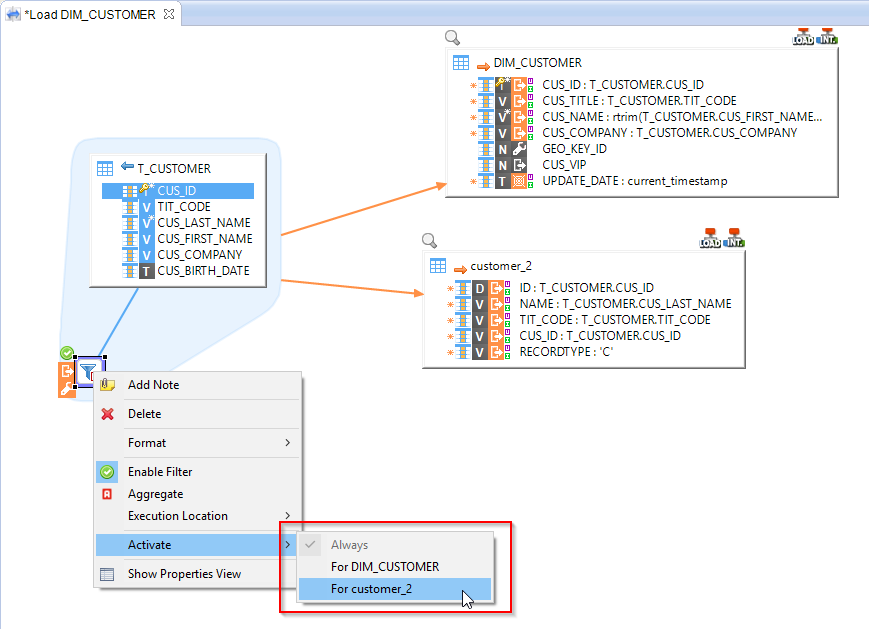
Filters can now be configured to be activated only for one target.
Right-click on the filter and select Activate > For [...]
Result:
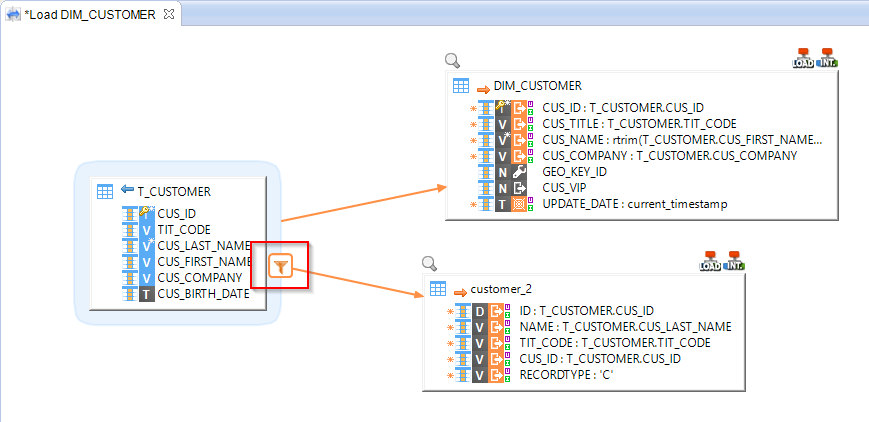
The filter will be used only for the Load/Integration of the customer_2 table.
Queries
A SQL Select Query can now be reversed and used in a database Metadata as a datastore.
Right-click on the database node and select New > Query Folder. It will create a folder in which the queries will be stored.
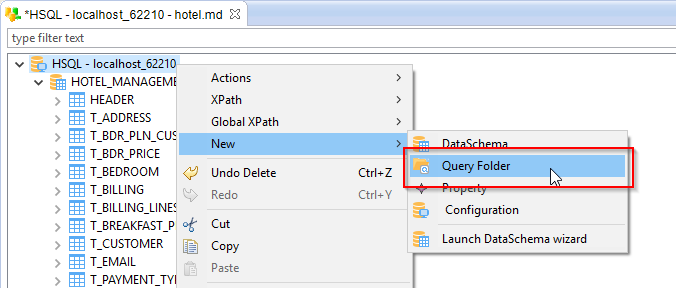
Give a name to the query folder which appeared in the Metadata and finally, right-click on it and select New > Query.
Next, configure the query with a name and expression, and reverse it with Actions > Reverse
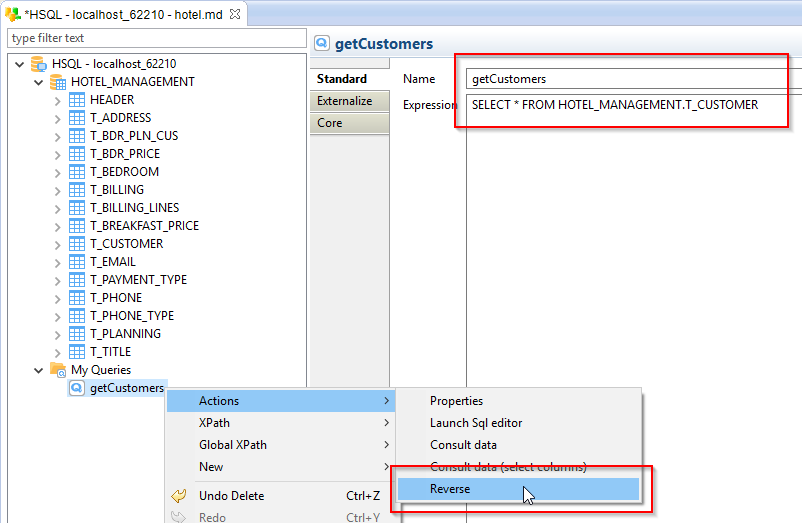
Result:
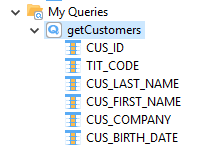
The reversed query can be used in Mappings as Source like any other datastores. However, it is not recommended to use it as a Target as it only represents a query and is not a table.
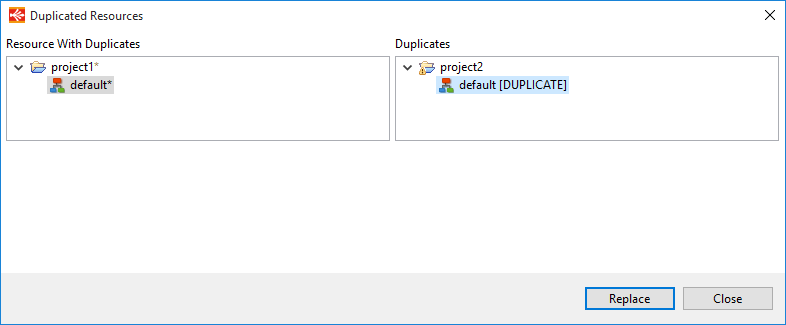
Duplicated Resources
Multiple resources with the same ID, called duplicates, can now co-exist in the same Workspace.
Only one can be active at the same time, and is indicated with an asterisk at the end of the name:
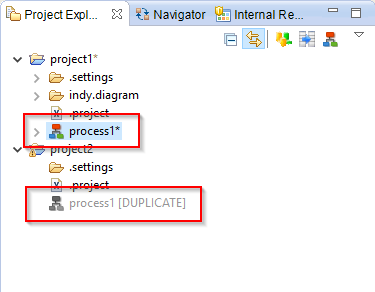
To enable a duplicate:
- Right click on it and select
Enable Duplicate Model. - The duplicated resource will become the active one.
Moreover, the Manage Duplicate Resources tool in the Impact View permits to manage the duplicates of the whole workspace:
A new window will open: